В сегодняшней статье речь пойдет о том, как переменные могут быть связаны друг с другом. С помощью корреляции мы сможем определить, существует ли связь между первой и второй переменной. Надеюсь, это занятие покажется вам не менее увлекательным, чем предыдущие!
Корреляция измеряет мощность и направление связи между x и y. На рисунке представлены различные типы корреляции в виде графиков рассеяния упорядоченных пар (x, y). По традиции переменная х размещается на горизонтальной оси, а y - на вертикальной.

График А являет собой пример положительной линейной корреляции: при увеличении х также увеличивается у, причем линейно. График В показывает нам пример отрицательной линейной корреляции, на котором при увеличении х у линейно уменьшается. На графике С мы видим отсутствие корреляции между х и у. Эти переменные никоим образом не влияют друг на друга.
Наконец, график D - это пример нелинейных отношений между переменными. По мере увеличения х у сначала уменьшается, потом меняет направление и увеличивается.
Оставшаяся часть статьи посвящена линейным взаимосвязям между зависимой и независимой переменными.
Коэффициент корреляции
Коэффициент корреляции, r, предоставляет нам как силу, так и направление связи между независимой и зависимой переменными. Значения r находятся в диапазоне между — 1.0 и + 1.0. Когда r имеет положительное значение, связь между х и у является положительной (график A на рисунке), а когда значение r отрицательно, связь также отрицательна (график В). Коэффициент корреляции, близкий к нулевому значению, свидетельствует о том, что между х и у связи не существует график С).
Сила связи между х и у определяется близостью коэффициента корреляции к - 1.0 или +- 1.0. Изучите следующий рисунок.

График A показывает идеальную положительную корреляцию между х и у при r = + 1.0. График В - идеальная отрицательная корреляция между х и у при r = — 1.0. Графики С и D - примеры более слабых связей между зависимой и независимой переменными.
Коэффициент корреляции, r, определяет, как силу, так и направление связи между зависимой и независимой переменными. Значения r находятся в диапазоне от — 1.0 (сильная отрицательная связь) до + 1.0 (сильная положительная связь). При r= 0 между переменными х и у нет никакой связи.
Мы можем вычислить фактический коэффициент корреляции с помощью следующего уравнения:

Ну и ну! Я знаю, что выглядит это уравнение как страшное нагромождение непонятных символов, но прежде чем ударяться в панику, давайте применим к нему пример с экзаменационной оценкой. Допустим, я хочу определить, существует ли связь между количеством часов, посвященных студентом изучению статистики, и финальной экзаменационной оценкой. Таблица, представленная ниже, поможет нам разбить это уравнение на несколько несложных вычислений и сделать их более управляемыми.

![]()

Как видите, между числом часов, посвященных изучению предмета, и экзаменационной оценкой существует весьма сильная положительная корреляция. Преподаватели будут весьма рады узнать об этом.
Какова выгода устанавливать связь между подобными переменными? Отличный вопрос. Если обнаруживается, что связь существует, мы можем предугадать экзаменационные результаты на основе определенного количества часов, посвященных изучению предмета. Проще говоря, чем сильнее связь, тем точнее будет наше предсказание.
Использование Excel для вычисления коэффициентов корреляции
Я уверен, что, взглянув на эти ужасные вычисления коэффициентов корреляции, вы испытаете истинную радость, узнав, что программа Excel может выполнить за вас всю эту работу с помощью функции КОРРЕЛ со следующими характеристиками:
КОРРЕЛ (массив 1; массив 2),
массив 1 = диапазон данных для первой переменной,
массив 2 = диапазон данных для второй переменной.
Например, на рисунке показана функция КОРРЕЛ, используемая при вычислении коэффициента корреляции для примера с экзаменационной оценкой.

Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
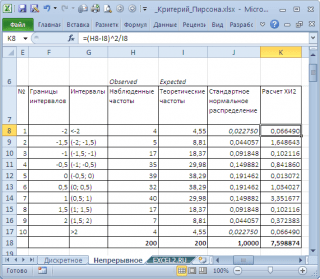
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.
ЛАБОРАТОРНАЯ РАБОТА
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ В EXCEL
1.1 Корреляционный анализ в MS Excel
Корреляционный анализ состоит в определении степени связи между двумя случайными величинами X и Y. В качестве меры такой связи используется коэффициент корреляции. Коэффициент корреляции оценивается по выборке объема п связанных пар наблюдений (x i , y i) из совместной генеральной совокупности X и Y. Для оценки степени взаимосвязи величин X и Y, измеренных в количественных шкалах, используетсякоэффициент линейной корреляции (коэффициент Пирсона), предполагающий, что выборки X и Y распределены по нормальному закону.
Коэффициент корреляции изменяется от -1 (строгая обратная линейная зависимость) до 1 (строгая прямая пропорциональная зависимость). При значении 0 линейной зависимости между двумя выборками нет.
Общая классификация корреляционных связей (по Ивантер Э.В., Коросову А.В., 1992):
Существует несколько типов коэффициентов корреляции, что зависит от переменных Х иY, которые могут быть измерены в разных шкалах. Именно этот факт и определяет выбор соответствующего коэффициента корреляции (см. табл. 13):
В MS Excel для вычисления парных коэффициентов линейной корреляции используется специальная функция КОРРЕЛ (массив1; массив2),
|
№ испытуемых | ||
Пример 1: 10 школьникам были даны тесты на наглядно-образное и вербальное мышление. Измерялось среднее время решения заданий теста в секундах. Исследователя интересует вопрос: существует ли взаимосвязь между временем решения этих задач? Переменная X - обозначает среднее время решения наглядно-образных, а переменная Y- среднее время решения вербальных заданий тестов.
Р ешение:
Для выявления степени взаимосвязи,
прежде всего, необходимо ввести данные
в таблицу MS Excel (см. табл., рис. 1). Затем
вычисляется значение коэффициента
корреляции. Для этого курсор установите
в ячейку C1. На панели инструментов
нажмите кнопку Вставка функции (fx).
ешение:
Для выявления степени взаимосвязи,
прежде всего, необходимо ввести данные
в таблицу MS Excel (см. табл., рис. 1). Затем
вычисляется значение коэффициента
корреляции. Для этого курсор установите
в ячейку C1. На панели инструментов
нажмите кнопку Вставка функции (fx).
В появившемся диалоговом окне Мастер функций выберите категорию Статистические и функциюКОРРЕЛ , после чего нажмите кнопку ОК. Указателем мыши введите диапазон данных выборки Х в поле массив1 (А1:А10). В поле массив2 введите диапазон данных выборки У (В1:В10). Нажмите кнопку ОК. В ячейке С1 появится значение коэффициента корреляции - 0,54119. Далее необходимо посмотреть на абсолютное число коэффициента корреляции и определить тип связи (тесная, слабая, средняя и т.д.)
Рис. 1. Результаты вычисления коэффициента корреляции
Таким образом, связь между временем решения наглядно-образных и вербальных заданий теста не доказана.
Задание 1. Имеются данные по 20 сельскохозяйственным хозяйствам. Найтикоэффициент корреляции между величинами урожайности зерновых культур и качеством земли и оценить его значимость. Данные приведены в таблице.
Таблица 2. Зависимость урожайности зерновых культур от качества земли
|
Номер хозяйства |
Качество земли, балл |
Урожайность, ц/га |
Задание 2. Определите, имеется ли связь между временем работы спортивного тренажера для фитнеса (тыс. часов) и стоимость его ремонта (тыс. руб.):
|
Время работа тренажера (тыс. часов) |
Стоимость ремонта (тыс. руб.) |
1.2 Множественная корреляция в MS Excel
При большом числе наблюдений, когда коэффициенты корреляции необходимо последовательно вычислять для нескольких выборок, для удобства получаемые коэффициенты сводят в таблицы, называемые корреляционными матрицами .
Корреляционная матрица - это квадратная таблица, в которой на пересечении соответствующих строк и столбцов находятся коэффициент корреляции между соответствующими параметрами.
В MS Excel для вычисления корреляционных матриц используется процедура Корреляция из пакета Анализ данных. Процедура позволяет получить корреляционную матрицу, содержащую коэффициенты корреляции между различными параметрами.
Для реализации процедуры необходимо:
1. выполнить команду Сервис - Анализ данных ;
2. в появившемся списке Инструменты анализа выбрать строку Корреляция и нажать кнопку ОК ;
3. в появившемся диалоговом окне указать Входной интервал , то есть ввести ссылку на ячейки, содержащие анализируемые данные. Входной интервал должен содержать не менее двух столбцов.
4. в разделе Группировка переключатель установить в соответствии с введенными данными (по столбцам или по строкам);
5. указать выходной интервал , то есть ввести ссылку на ячейку, начиная с которой будут показаны результаты анализа. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные. Нажать кнопку ОК .
В выходной диапазон будет выведена корреляционная матрица, в которой на пересечении каждых строки и столбца находится коэффициент корреляции между соответствующими параметрами. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, так как каждый столбец во входном диапазоне полностью коррелирует сам с собой
Пример 2. Имеются ежемесячные данные наблюдений за состоянием погоды и посещаемостью музеев и парков (см. табл. 3). Необходимо определить, существует ли взаимосвязь между состоянием погоды и посещаемостью музеев и парков.
Таблица 3. Результаты наблюдений
|
Число ясных дней |
Количество посетителей музея |
Количество посетителей парка |
Решение . Для выполнения корреляционного анализа введите в диапазон A1:G3 исходные данные (рис. 2). Затем в меню Сервис выберите пункт Анализ данных и далее укажите строку Корреляция . В появившемся диалоговом окне укажите Входной интервал (А2:С7). Укажите, что данные рассматриваются по столбцам. Укажите выходной диапазон (Е1) и нажмите кнопку ОК .
На рис. 33 видно, что корреляция между состоянием погоды и посещаемостью музея равна -0,92, а между состоянием погоды и посещаемостью парка - 0,97, между посещаемостью парка и музея - 0,92.
Таким образом, в результате анализа выявлены зависимости: сильная степень обратной линейной взаимосвязи между посещаемостью музея и количеством солнечных дней и практически линейная (очень сильная прямая) связь между посещаемостью парка и состоянием погоды. Между посещаемостью музея и парка имеется сильная обратная взаимосвязь.

Рис. 2. Результаты вычисления корреляционной матрицы из примера 2
Задание 3 . 10 менеджеров оценивались по методике экспертных оценок психологических характеристик личности руководителя. 15 экспертов производили оценку каждой психологической характеристики по пятибальной системе (см. табл. 4). Психолога интересует вопрос, в какой взаимосвязи находятся эти характеристики руководителя между собой.
Таблица 4. Результаты исследования
|
Испытуемые п/п |
тактичность |
требовательность |
критичность |
Коэффициент корреляции отражает степень взаимосвязи между двумя показателями. Всегда принимает значение от -1 до 1. Если коэффициент расположился около 0, то говорят об отсутствии связи между переменными.
Если значение близко к единице (от 0,9, например), то между наблюдаемыми объектами существует сильная прямая взаимосвязь. Если коэффициент близок к другой крайней точке диапазона (-1), то между переменными имеется сильная обратная взаимосвязь. Когда значение находится где-то посередине от 0 до 1 или от 0 до -1, то речь идет о слабой связи (прямой или обратной). Такую взаимосвязь обычно не учитывают: считается, что ее нет.
Расчет коэффициента корреляции в Excel
Рассмотрим на примере способы расчета коэффициента корреляции, особенности прямой и обратной взаимосвязи между переменными.
Значения показателей x и y:
Y – независимая переменная, x – зависимая. Необходимо найти силу (сильная / слабая) и направление (прямая / обратная) связи между ними. Формула коэффициента корреляции выглядит так:

Чтобы упростить ее понимание, разобьем на несколько несложных элементов.


Между переменными определяется сильная прямая связь.
Встроенная функция КОРРЕЛ позволяет избежать сложных расчетов. Рассчитаем коэффициент парной корреляции в Excel с ее помощью. Вызываем мастер функций. Находим нужную. Аргументы функции – массив значений y и массив значений х:

Покажем значения переменных на графике:

Видна сильная связь между y и х, т.к. линии идут практически параллельно друг другу. Взаимосвязь прямая: растет y – растет х, уменьшается y – уменьшается х.
Матрица парных коэффициентов корреляции в Excel
Корреляционная матрица представляет собой таблицу, на пересечении строк и столбцов которой находятся коэффициенты корреляции между соответствующими значениями. Имеет смысл ее строить для нескольких переменных.

Матрица коэффициентов корреляции в Excel строится с помощью инструмента «Корреляция» из пакета «Анализ данных».


Между значениями y и х1 обнаружена сильная прямая взаимосвязь. Между х1 и х2 имеется сильная обратная связь. Связь со значениями в столбце х3 практически отсутствует.
Лабораторная работа №6. Проверка гипотезы о нормальном распределении выборки по критерию Пирсона.
Лабораторная работа выполняется в Excel 2007.
Цель работы – дать навыки первичной обработки данных, построении гистограмм, подборе подходящего закона распределения и вычислении его параметров, проверка согласия между эмпирическим и гипотетическим законом распределения по критерию хи-квадрат Пирсона средствами Excel.
1. Формирование выборки нормально распределенных случайных чисел с заданными значениями математического ожидания и среднего квадратического отклонения.
Данные → Анализ данных → Генерация случайных чисел → ОК .
Рис. 1. Диалоговое окно Анализ данных
В появившемся окне Генерация случайных чисел ввести:
Число переменных: 1 ;
Число случайных чисел: 100 ;
Распределение: Нормальное .
Параметры:
Среднее = 15 (математическое ожидание);
Стандартное отклонение = 2 (среднее квадратическое отклонение);
Случайное рассеивание: не заполнять (или заполнить по указанию преподавателя );
Выходной интервал: адрес первой ячейки столбца массива случайных чисел - $ A $1 . ОК .

Рис. 2. Диалоговое окно Генерация случайных чисел с заполненными полями ввода
В результате выполнения операции Генерация случайных чисел появится столбец $ A $1: $A$100 , содержащий 100 случайных чисел.

Рис. 3. Фрагмент листа Excel первых нескольких случайных чисел $A$1: $A$100.
2. Определение параметров выборки, описательные статистики
В главном меню Excel выбрать: Данные → Анализ данных → Описательная статистика → ОК .
В появившемся окне Описательная статистика ввести:
Входной интервал – 100 случайных чисел в ячейках $ A $1: $ A $100 ;
Группирование - по столбцам;
Выходной интервал – адрес ячейки, с которой начинается таблица Описательная статистика - $ C $1 ;
Итоговая статистика – поставить галочку. ОК.

Рис. 4. Диалоговое окно Описательная статистика с заполненными полями ввода.
На листе Excel появится таблица – Столбец 1

Рис. 5. Таблица Столбец 1 с данными процедуры Описательная статистика .
Таблица содержит описательные статистики, в частности:
Среднее – оценка математического ожидания;
Стандартное отклонение – оценка среднего квадратического отклонения;
Эксцесс и Асимметричность – оценки эксцесса и асимметрии.
Приблизительное равенство нулю оценок эксцесса и асимметрии, и приблизительное равенство оценки среднего оценке медианы дает предварительное основание выбрать в качестве основной гипотезы H 0 распределения элементов генеральной совокупности - нормальный закон.
Интервал – размах выборки;
Минимум – минимальное значение случайной величины в выборке;
Максимум – максимальное значение случайной величины в выборке.
В ячейке F 15 - длина частичного интервала h , вычисленная следующим образом:
Число интервалов группировки k в Excel вычисляется автоматически по формуле
где, скобки означают – округление до целой части числа в меньшую сторону.
В рассматриваемом варианте n = 100 , следовательно, k = 11 . Действительно:

Эта формула занесена в ячейку F 15: =($D$13-$D$12)/10
Результаты процедуры Описательная статистика потребуются в дальнейшем при построении теоретического закона распределения.