Добрый день, друзья.
Наверняка вы уже забыли вкус моих статей. Предыдущий материал был довольно давно, хотя и обещал я публиковать статьи чаще, чем обычно.
В последнее время увеличилось количество работы. Создал новый проект (информационный сайт), занимался его версткой, дизайном, собирал семантическое ядро и начал публиковать материал.
Сегодня же будет очень объемный и важный материал для тех, кто ведет свой сайт более 6-7 месяцев (в некоторых тематиках более 1 года) имеет большое количество статей (в среднем 100) и еще не достиг планки минимум в 500-1000 посещений в сутки. Цифры взяты по минимуму.
Важность семантического ядра
В некоторых случаях слабый рост сайта вызван неправильной технической оптимизацией сайта. Больше случаев, когда контент некачественный. Но еще больше случаев, когда тексты пишутся вообще не под запросы - материалы никому не нужны. Но имеется еще и очень огромная часть людей, которая создает сайт, все правильно оптимизирует, пишет качественные тексты, но спустя 5-6 месяцев сайт только начинает набирать первые 20-30 посетителей с поиска. Небольшими темпами через год это уже 100-200 посетителей и цифра в доходах равняется нулю.
И хотя, все сделано правильно, нет никаких ошибок, а тексты порой даже в разы качественней конкурентов, но вот как-то не идет, хоть убей. Начинаем списывать этот косяк на отсутствие ссылок. Конечно ссылки дают буст в развитии, но это не самое главное. И без них можно через 3-4 месяца иметь 1000 посещений на сайте.
Многие скажут, что это все треп и так быстро такие цифры не получишь. Но если мы посмотрим, то не достигаются такие цифры именно на блогах. Информационные же сайты (не блоги), созданные для быстрого заработка и окупаемости вложений, примерно через 3-4 месяца вполне реально выходят на суточную посещаемость в 1000 человек, а через год – 5000-10000. Цифры конечно зависят от конкурентности ниши, ее объема и объема самого сайта на указанный срок. Но, если взять нишу с довольно небольшой конкуренцией и объемом в 300-500 материалов, то такие цифры за указанные сроки вполне достижимы.
Почему же именно блоги не достигают таких быстрых результатов? Главнейшей причиной является отсутствие семантического ядра. Из-за этого статьи пишут всего под один какой-то запрос и практически всегда под очень конкурентный, что не дает странице выбиться в ТОП за короткие сроки.
На блогах, как правило, статьи пишут по подобию конкурентов. Имеем 2- читаемых блога. Видим, что у них посещаемость приличная, начинаем анализировать их карту сайта и публиковать тексты под те же самые запросы, которые уже переписаны сотнями раз и очень конкурентные. В итоге получаем очень качественный контент на сайте, но в поиске он себя чувствует плохо, т.к. требует большого возраста. Бьемся об голову, почему же мой контент лучший, но в ТОП не пробивается?
Именно поэтому я решил написать подробный материал про семантическое ядро сайта, чтобы вы могли собрать себе список запросов и что немало важно – писали тексты под такие группы ключевых слов, которые без покупки ссылок и всего за 2-3 месяца выходили в ТОП (конечно, если контент качественный).
Материал для большинства будет сложный, если ни разу не сталкивались с этим вопросом в его правильном ключе. Но тут главное начать. Как только начинаете действовать, все сразу становится ясно.
Сделаю очень важное замечание. Касается оно тех, кто не готов вкладываться в качество своими кровными заработанными монетами и всегда пытается находить бесплатные лазейки. Семантику бесплатно качественно не соберешь и это известный факт. Поэтому, в данной статье я описываю процесс сбора семантики максимального качества. Никаких бесплатных способов или лазеек именно в этом посте не будет! Обязательно будет новый пост, где расскажу про бесплатные и другие инструменты, с помощью которых вы сможете собрать семантику, но не в полном объеме и без должного качества. Поэтому, если вы не готовы вкладываться в основу основ для вашего сайта, тогда данный материал вам ни к чему!
Несмотря на то, что практически каждый блоггер пишет статью о сем. ядре, могу с уверенностью сказать, что нет нормальных бесплатных пособий в интернете по данной теме. А если и есть, то нет такого, которое бы в полной картине давало понятие, что же должно получится на выходе.
Чаще всего ситуация заканчивается тем, что какой-то новичок пишет материал и рассказывает о сборе семантического ядра, как о применении сервиса для сбора статистика поисковых запросов от Яндекс (wordstat.yandex.ru). В конечном итоге необходимо зайти на этот сайт, вбить запросы по вашей теме, сервис выдаст список фраз, входящих в ваш вбитый ключ – это и есть вся методика.
Но на самом деле семантическое ядро собирается не так. В описанном выше случае у вас попросту не будет семантического ядра. Вы получите какие-то оторванные запросы и все они будут об одном и том же. Например, возьмем мою нишу «сайтостроение».
Какие главные запросы можно по ней без раздумий назвать? Вот лишь некоторые:
- Как создать сайт;
- Раскрутка сайта;
- Создание сайта;
- Продвижение сайта и т.д.
Запросы получаются об одном и том же. Смысл их сводится лишь к 2м понятиям: создание и раскрутка сайта.
После такой проверки сервис wordstat выдаст очень много поисковых запросов, которые входят в главные запросы и они также будут об одном и том же. Единственное их различие будет в измененных словоформах (добавление некоторых слов и изменение расположения слов в запросе с изменением окончаний).
Конечно, определенное количество текстов написать получится, так как запросы могут быть разные даже в данном варианте. Например:
- Как создать сайт wordpress;
- Как создать сайт joomla;
- Как создать сайт на бесплатном хостинге;
- Как раскрутить сайт бесплатно;
- Как раскрутить сайт сервис и т.д.
Очевидно, что под каждый запрос можно выделить отдельный материал. Но такое составление семантического ядра сайта не увенчается успехом, т.к. не будет полноты раскрытия информации на сайте в выбранной нише. Весь контент будет лишь о 2х темах.
Иногда блоггеры-новички описывают процесс составления семантического ядра, как анализ отдельных запросов в сервисе анализа запросов Яндекс Вордстат. Вбиваем какой-то отдельный запрос, относящийся не к теме в целом, а лишь к определенной статье (например, как оптимизировать статью), получаем по нему частотность и вот оно – семантическое ядро собирается. Получается, что таким образом мы должны умственно определить всевозможные темы статей и проанализировать их.
Оба вышеописанные варианты неправильные, т.к. не дают полного семантического ядра и заставляют постоянно возвращаться к его составлению (второй вариант). К тому же вы не будете иметь на руках вектор развития сайта и не сможете в первую очередь публиковать материалы, которые и нужно размещать в числе первых.
Касаемо первого варианта, то покупая когда-то курсы по раскрутке сайтов, я постоянно видел именно такое объяснение сбора ядра запросов для сайта (вбить главные ключ и скопировать все запросы из сервиса в текстовый документ). В итоге меня постоянно мучал вопрос «А что же делать с такими запросами?» На ум приходило следующее:
- Писать много статей об одном и том же, но употребляя разные ключевые слова;
- Все эти ключи вписывать в поле description к каждому материалу;
- Вписать все ключи из сем. ядра в общее поле description ко всему ресурсу.
Ни одно из этих предположений не было верным, как в общем-то и само составленное семантическое ядро сайта.
На окончательном варианте сбора семантического ядра мы должны получит не просто список запросов в количестве 10000, например, а иметь на руках список групп запросов, каждая из которых используется для отдельной статьи.
Группа может содержать от 1 до 20-30 запросов (иногда 50, а то и больше). В таком случае в тексте мы употребляем все эти запросы и страница в перспективе ежедневно будет приносить трафик по всем запросам, если попадет на 1-3 позиции в поиске. Кроме этого, каждая группа должна иметь свою конкуренцию, чтобы знать, имеет ли смысл сейчас публиковать по ней текст или нет. Если конкуренция большая, тогда можем ожидать эффект от страницы только через 1-1.5 года и с проведением регулярных работ по ее продвижению (ссылки, перелинковка и т.д.). Поэтому, лучше на такие тексты делать упор в самую последнюю очередь, даже если они самые трафиковые.
Ответы на возможные вопросы
Вопрос №1. Понятно, что на выходе получаем группу запросов для написания текста, а не всего один ключ. Не будут ли похожи в этом случае ключи между собой и почему бы под каждый запрос не написать отдельный текст?
Вопрос №2. Известно, что каждая страница должна затачиваться лишь под один ключевик, а тут мы получаем целую группу да еще в некоторых случаях с достаточно большим содержанием запросов. Как в таком случае происходит оптимизация самого текста, ведь если ключей, например, 20, тогда употребление хотя бы по одному разу каждого в тексте (даже большого размера) уже похоже на текст для поисковика, а не для людей.
Ответ. Если взять пример запросов из предыдущего вопроса, то затачиваться материал первым делом будет именно под самый частотный (1й) запрос, так как мы большего всего заинтересованы в его выходе на топовые позиции. Данный ключевик мы и считаем главным в этой группе.
Оптимизация под главную ключевую фразу происходит также, как бы это и делалось при написании текста лишь под один ключ (ключ в заголовке title, употребление нужного количества символов в тексте и нужного количества раз самого ключа, если требуется).
Касаемо других ключей, то мы их также вписываем, но не слепо, а на основе анализа конкурентов, который может показать среднее значение количества этих ключей в текстах из ТОПа. Может получиться ситуация, что для большинства ключевиков вы получите нулевые значения, а значит в точном вхождении они не требуют употребления.
Таким образом текст пишется, употребляя всего лишь главный запрос в тексте в прямом. Конечно другие запросы тоже могут быть употреблены, если анализ конкурентов покажет их наличие в текстах из ТОП. Но это никак не 20 ключевиков в тексте в их точном вхождении.
Совсем недавно публиковал материал под группу из 11 ключей. Вроде бы много запросов, но на скриншоте ниже можете видеть, что лишь главный самый частотный ключ имеет употребление точного вхождения – 6 раз. Остальные же ключевые фразы не имеют точных вхождений, но также и разбавочных (на скриншоте не видно, но в ходе анализа конкурентов это показано). Т.е. они вообще не употребляются.
(1я колонка – частотность, 2я – конкурентность, 3я – количество показов)
В большинстве случаев будет похожая ситуация, когда лишь пару ключей нужно будет употребить в точном вхождении, а все остальные либо сильно разбавлять, либо вообще не употреблять даже в разбавочном вхождении. Статья получается читаемой и нет намеков на заточку только под поиск.
Вопрос №3. Вытекает из ответа на Вопрос №2. Если остальные ключи в группе не нужно вообще употреблять, то как тогда они будут получать трафик?
Ответ. Дело в том, что по наличию определенных слов в тексте поисковик может определить о чем текст. Так как в ключевых словах имеются определенные отдельные слова, относящиеся только к этому ключу, то их и нужно употреблять в тексте определенное количество раз на основе того же анализа конкурентов.
Таким образом ключ в точном вхождении не употребится, а вот слова из ключа по отдельности в тексте присутствовать будут и в ранжировании также будут принимать участие. В итоге по этим запросам текст будет также находиться в поиске. Но и количество отдельных слов в этом случае в идеале требуется соблюдать. Помогут конкуренты.
На основные вопросы, которые могли загнать вас в ступор, я ответил. Подробнее, как оптимизировать текст под группы запросов, я напишу в одном из следующим материалов. Там будет и про анализ конкурентов и про написание самого текста под группу ключей.
Ну, а если вопросы еще остались, тогда задавайте свои комментарии. На все отвечу.
А теперь давайте начнем составление семантического ядра сайта.
Очень важно. Весь процесс, как он есть на самом деле я никак не смогу описать в этой статье (придется делать целый вебинар на 2-3 часа или мини-курс), поэтому я постараюсь быть краток, но в то же время информативным и затронуть максимальное количество моментов. Например, я не буду описывать в детальности настройку софта KeyCollector. Все будет урезано, но максимально понятно.
Теперь пройдемся по каждому пункту. Начнем. Сначала подготовка.
Что необходимо для сбора семантического ядра?

Перед тем, как составить семантическое ядро сайта, настроим кейколлектор для правильного сбора статистики и парсинга запросов.
Настройка KeyCollector
Войти в настройки можно, нажав на пиктограмму в верхнем меню софта.

Сначала то, что касается парсинга.
Хочу отметить настройки «Количество потоков» и «Использовать основной IP-адрес». Количество потоков для сбора одного небольшого ядра не нужно большое. Достаточно 2-4 потоков. Чем больше потоков, тем больше нужно прокси-серверов. В идеале 1 прокси на 1 поток. Но можно и 1 прокси на 2 потока (так парсил я).
Касаемо второй настройки, то в случае парсинга в 1-2 потока можно использовать свой основной ИП адрес. Но только,если он динамический, т.к. в случае бана статического ИП вы потеряете доступ к поисковой системе Яндекс. Но все же приоритет всегда отдается использованию прокси-сервера, так как лучше обезопасить себя.
На вкладке настроек парсинга Yandex.Direct важно добавить свои аккаунты Яндекса. Чем их будет больше, тем лучше. Можете их зарегистрировать сами или купить, как я писал ранее. Я же их приобретал, так как мне проще потратить 100 рублей за 30 аккаунтов.
Добавление можно выполнить из буфера, заранее скопировав список аккаунтов в нужном формате, или загрузить из файла.
Аккаунты нужно указывать в формате «логин:пароль» при этом в логине не указывать сам хост (без @yandex.ru). Например, «artem_konovalov:jk8ergvgkhtf».
Также, если мы используем несколько прокси-серверов, лучше закрепить их за определенными аккаунтами. Подозрительно будет, если сначала запрос идет с одного сервера и с одного аккаунта, а при следующем запросе с этого же акаунта яндекса прокси сервер уже другой.
Рядом с аккаунтами имеется столбик «IP прокси». Напротив каждого аккаунта мы и вписываем определенный прокси. Если аккаунтов 20, а прокси-серверов 2, тогда будет 10 аккаунтов с одним прокси и 10 с другим. Если 30 аккаунтов, тогда 15 с один сервером и 15 с другим. Логику, думаю, вы поняли.
Если используем всего один прокси, то нет смысла вписывать его к каждому аккаунту.
Про количество потоков и использование основного ИП адреса я говорил немного ранее.
Следующая вкладка «Сеть», на которой нужно внести прокси-сервера, которые будут использоваться для парсинга.
Вводить прокси нужно в самом низу вкладки. Можно загрузить их из буфера в нужном формате. Я же добавлял по простому. В каждую колонку строки я вписывал данные о сервере, дающиеся вам при его покупке.
Далее настраиваем параметры экспорта. Так как все запросы с их частотностями нам нужно получить в файле на компьютере, то необходимо выставить некоторые параметры экспорта, чтобы не было ничего лишнего в таблице.
В самом низу вкладки (выделил красным) нужно выбрать те данные, которые нужно экспортировать в таблицу:
- Фраза;
- Источник;
- Частотность «!» ;
- Лучшая форма фразы (можно и не ставить).
Осталось лишь настроить разгадывание антикапчи. Вкладка так и называется - «Антикапча». Выбираем используемый сервис и вводим специальный ключ, который находится в аккаунте сервиса.
Специальный ключ для работы с сервисом предоставляется в письме после регистрации, но также его можно взять из самого аккаунта в пункте «Настройки – настройки аккаунта».
На этом настройки KeyCollector выполнены. Не забываем после проделанных изменений сохранить настройки, нажав на большую кнопку внизу «Сохранить изменения».
Когда все сделано и мы готовы к парсингу, можно приступить к рассмотрению этапов сбора семантического ядра, а потом уже и проделать каждый этап в порядке очереди.
Этапы сбора семантического ядра
Получить качественное и полное семантическое ядро невозможно, используя лишь основные запросы. Также нужно анализировать запросы и материалы конкурентов. Поэтому весь процесс составления ядра состоит из нескольких этапов, которые в свою очередь еще делятся на подэтапы.
- Основа;
- Анализ конкурентов;
- Расширение готового списка с этапов 1-2;
- Сбор лучших словоформ к запросам с этапов 1-3.
Этап 1 – основа
В ходе сбора ядра на этом этапе нужно:
- Сформировать основной список запросов в нише;
- Расширение этих запросов;
- Чистка.
Этап 2 – конкуренты
В принципе, этап 1 уже дает некий объем ядра, но не в полной мере, т.к. мы можем что-то упустить. А конкуренты в нашей нише помогут найти упущенные дыры. Вот шаги, необходимые к выполнению:
- Сбор конкурентов на основе запросов с этапа 1;
- Парсинг запросов конкурентов (анализ карты сайта, открытая статистика liveinternet, анализ доменов и конкурентов в SpyWords);
- Чистка.
Этап 3 – расширение
Многие останавливаются уже на первом этапе. Кто-то доходит до 2го, но имеется же еще ряд дополнительных запросов, которые также могут дополнить семантическое ядро.
- Объединяем запросы с 1-2 этапов;
- Оставляем 10% самых частотных слов со всего списка, которые содержат минимум 2 слова. Важно, чтобы эти 10% были не более 100 фраз, т.к. большое количество заставит вас сильно закопаться в процесс сбора, чистки и группировки. Нам же нужно собрать ядро в соотношении скорость/качество (минимальные потери качества при максимальной скорости);
- Выполняем расширение этих запросов с помощью сервиса Rookee (все есть в KeyCollector);
- Чистим.
Этап 4 – сбор лучших словоформ
Сервис Rookee может для большинства запросов определить их лучшую (правильную) словоформу. Этим также нужно пользоваться. Целью не является определить то слово, которое более правильно, а найти еще некоторые запросы и их формы. Таким образом можно подтянуть еще пул запросов и использовать их при написании текстов.
- Объединение запросов с первых 3х этапов;
- Сбор по ним лучших словоформ;
- Добавление лучших словоформ в список ко всех запросам, объединенным с 1-3 этапов;
- Чистка;
- Экспорт готового списка в файл.
Как видите, все не так уж и быстро, а тем более не так просто. Это я обрисовал лишь нормальный план составления ядра, чтобы на выходе получить качественный список ключей и ничего не потерять или потерять по минимуму.
Теперь я предлагаю пройтись по каждому пункту в отдельности и проштудировать все от А до Я. Информации много, но это того стоит, если вам нужно действительно качественное семантическое ядро сайта.
Этап 1 – основа
Сперва мы формируем список основных запросов ниши. Как правило, это 1-3х словные фразы, которые описывают определенный вопрос ниши. В пример предлагаю взять нишу «Медицина», а конкретнее - поднишу сердечных заболеваний.
Какие основные запросы мы можем выделить? Все я конечно писать не буду, но парочку приведу.
- Заболевания сердца
- Инфаркт;
- Ишемическая болезнь сердца;
- Аритмия;
- Гипертония;
- Порок сердца;
- Стенокардия и т.д.
Простыми словами – это общие названия заболеваний. Таких запросов может быть достаточно много. Чем больше сможете сделать, тем лучше. Но не стоит вписывать для галочки. Бессмысленно выписывать более конкретные фразы от общих, например:
- Аритмия;
- Аритмия причины;
- Лечение аритмии;
- Аритмия симптомы.
Главной является лишь первая фраза. Остальные нет смысла указывать, т.к. они появятся в списке в ходе расширения с помощью парсинга из левой колонки Яндекс вордстат.
Для поиска общих фраз можно пользоваться, как сайтами конкурентов (карта сайта, названия разделов…), так и опытом специалиста в этой нише.

Парсинг займет некоторое время, в зависимости от количества запросов в нише. Все запросы по умолчанию помещаются в новую группу с названием «Новая группа 1», если память не изменяет. Я обычно переименовываю группы, чтобы понимать, какая за что отвечает. Меню управления группами находится справа от списка запросов.
Функция переименования находится в контекстном меню при нажатии правой кнопки мыши. Это меню понадобится еще для создания других групп на втором, третьем и четвертом этапах.
Поэтому, можете сразу добавить еще 3 группы, нажав на первую пиктограмму «+», чтобы группа создалась в списке сразу после предыдущей. Пока в них не нужно ничего добавлять. Пусть просто будут.
Называл я группы так:
- Конкуренты – понятно, что в этой группе находится список запросов, который я дособрал у конкурентов;
- 1-2 – это объединенный список запросов с 1го (основного списка запросов) и 2го (запросы конкурентов) этапов, чтобы оставить из них всего 10% запросов, состоящих минимум из 2х слов и собрать по ним расширения;
- 1-3 – объединенный список запросов с первого, второго и третьего (расширений) этапов. Также в эту группу мы собираем лучшие словоформы, хотя грамотней было бы собрать их в новую группу (например, лучшие словоформы), а затем после их чистки уже перенести в группу 1-3.
После окончания парсинга из yandex.wordstat вы получаете большой список ключевых фраз, который, как правило (ели ниша небольшая) будет в пределах нескольких тысяч. Много из этого является мусором и запросами-пустышками и придется все чистить. Что-то отсеем автоматически с помощью функционала KeyCollector, а что-то придется лопатить руками и немного посидеть.
Когда запросы все собраны, нужно собрать их точные частотности. Общая частотность собирается при парсинге, а вот точную нужно собирать отдельно.
Для сбора статистики по количеству показов можно пользоваться двумя функциями:
- С помощью Яндекс Директ – быстро, статистика собирается пачками, но имеются ограничения (например, фразы больше 7ми слов не прокатят и с символами тоже);
- С помощью анализа в Яндекс Вордстате – очень медленно, фразы анализируются по одной, но нет ограничений.
Сначала собрать статистику с помощью Директа, чтобы это было максимально быстро, а для тех фраз, по которым с Директом не получилось определить статистику, используем уже Вордстат. Как правило, таких фраз останется мало и они дособерутся быстро.
Сбор статистика показов с помощью Яндекс.Директ осуществляются при нажатии на соответствующую кнопку и назначении нужных параметров.
После нажатия на кнопку «Получить данные» может быть предупреждение, что Яндекс Директ не включен в настройках. Вам нужно будет согласиться на активацию парсинга с помощью Директа, чтобы начать определять статистику частотности.
Вы сразу увидите, как пачками в колонку «Частотность! » начнут проставляются точные показатели показов по каждой фразе.
Процесс выполнения задачи можно видеть на вкладке «Статистика» в самом низу программы. Когда задача будет выполнена, на вкладке «Журнал событий» вы увидите уведомление о завершении, а также исчезнет полоса прогресса на вкладке «Статистика».
После сбора количества показов с помощью Яндекс Директ мы проверяем, имеются ли фразы, для которых частотность не собралась. Для этого сортируем колонку «Частотность!» (нажимаем на нее), чтобы в верху стали наименьшие значения или наибольшие.
Если вверху будут все нули, тогда все частотности собранные. Если же будут пустые ячейки, тогда для этих фраз показы не определились. Тоже самое касается и при сортировке по убиванию, только тогда придется смотреть результат в самом низу списка запросов.
Начать сбор с помощью яндекс вордстат также можно, нажав на пиктограмму и выбрав необходимый параметр частотности.

После выбора типа частотности вы увидите, как постепенно начнут заполнятся пустые ячейки.
Важно: не стоит пугаться, если после конца процедуры останутся пустые ячейки. Дело в том, что пустыми они будут в случае их точной частотности менее 30. Это мы выставили в настройках парсинга в Keycollector. Эти фразы можно смело выделить (также, как и обычные файлы в проводнике Windows) и удалить. Фразы выделятся голубым цветом, нажимаем правую кнопку мышки и выбираем «Удалить выделенные строки».
Когда вся статистика собрана, можно приступить к чистке, которую очень важно делать на каждом этапе сбора семантического ядра.
Основная задача – убрать фразы не относящие к тематике, убрать фразы со стоп-словами и избавиться от слишком низкочастотных запросов.
Последнее в идеале не нужно выполнять, но, если мы будем в ходе составления сем. ядра использовать фразы даже с минимальной частотностью в 5 показов в месяц, то это увеличит ядро на процентов 50-60 (а может быть и все 80%) и заставить нас сильно закопаться. Нам же нужно получить максимальную скорость при минимальных потерях.
Если хотим получить максимально полное семантическое ядро сайта, но при этом собирать его около месяца (есть опыт совсем отсутствует), тогда берите частотности от 4-5 месячных показов. Но лучше (если новичок) оставлять запросы, которые имеют хотя бы 30 показов в месяц. Да, мы немного потеряем, но это цена за максимальную скорость. А уже в ходе роста проекта можно будет заново получить эти запросы и уже их использовать для написания новых материалов. И это только при условии, что все сем. ядро уже выписано и нет тем для статей.
Отфильтровать запросы по количеству их показов и другим параметрам позволяет все тот же кейколлектор на полном автомате. Изначально я рекомендую сделать именно это, а не удалять мусорные фразы и фразы со стоп-словами, т.к. гораздо проще будет это делать, когда общий объем ядра на этом этапе станет минимальным. Что проще, лопатить 10000 фраз или 2000?
Доступ к фильтрам находится на вкладке «Данные», нажав на кнопку «Редактировать фильтры».

Я рекомендую сначала отобразить все запросы с частотностью менее 30 и перенести их в новую группу, чтобы их не удалять, так как в будущем они могут пригодиться. Если же мы просто применим фильтр для отображения фраз с частотностью более 30, то после очередного запуска KeyCollector придется заново применять этот же фильтр, так как все сбрасывается. Конечно, фильтр можно сохранить, но все равно придется его применять, постоянно возвращаясь ко вкладке «Данные».
Чтобы избавить себя от этих действий, мы в редакторе фильтров добавляем условие, чтобы отображались фразы только с частотностью менее 30.



В будущем выбрать фильтр можно, нажав на стрелку возле пиктограммы дискеты.
Итак, после применения фильтра, в списке запросов останутся только фразы с частотностью менее 30, т.е. 29 и ниже. Также отфильтрованная колонка выделится цветом. В примере ниже вы будете видеть частотность только 30, т.к. я показываю все это на примере уже готово ядра и все почищено. На это внимания не обращайте. У вас все должно быть так, как я описываю в тексте.

Для переноса нужно выделить все фразы в списке. Нажимаем на первую фразу, Листаем в самый низ списка, зажимаем клавишу «Shift» и кликаем один раз на последнюю фразу. Таким образом выделяется все фразы и пометятся голубым фоном.
Появится небольшое окно, где необходимо выбрать именно перемещение.
Теперь можно удалить фильтр с колонки частотности, чтобы остались запросы только с частотностью 30 и выше.

Определенный этап автоматической чистки мы выполнили. Дальше придется повозиться, удалив мусорные фразы.
Сначала предлагаю указать стоп-слова, чтобы удалить все фразы с их наличием. В идеале конечно же это делается сразу на этапе парсинга, чтобы в список они и не попадали, но это не критично, так как очищение от стоп-слов происходит в автоматическом режиме с помощью Кейколлектора.
Основная сложность состоит в составлении списка стоп-слов, т.к. в каждой тематике они разные. Поэтому, делали бы мы чистку от стоп-слов в начале или сейчас – не так важно, так как стоит найти все стоп-слова, а это дело наживное и не такое уж и быстрое.
В интернете вы можете найти общетематические списки, в которые входят самые распространенные слова по типу «реферат, бесплатно, скачать, п…рно, онлайн, картинка и т.д.».
Сначала предлагаю применить общетематический список, чтобы количество фраз еще уменьшилось. На вкладке «Сбор данных» жмете на кнопку «Стоп-слова» и добавляете их списком.
В этом же окне жмем на кнопку «Отметить фразы в таблице», чтобы отметились все фразы, содержащие введенные стоп-слова. Но нужно, чтобы весь список фраз в группе был не отмечен, чтобы после нажатия на кнопку остались отмечены только фразы со стоп-словами. Снять отметки со всех фраз очень просто.

Когда останутся отмеченные только фразы со стоп-словами, мы ух либо удаляем, либо переносим в новую группу. Я в первый раз удалил, но все таки приоритетней создать группу «Со стоп-словами» и переместить в нее все лишние фразы.
После очистки, фраз стало еще меньше. Но и это не все, т.к. все равно мы что-то упустили. Как сами стоп-слова, так и фразы, не относящие к направленности нашего сайта. Это могут быть коммерческие запросы, под которые тексты не напишешь или же напишешь, но они не будут соответствовать ожиданиям пользователя.
Примеры таких запросов могут быть связаны со словом «купить». Наверняка, когда пользователь что-то ищет с этим словом, то он уже хочет попасть на сайт, где это продают. Мы же напишем текст под такую фразу, но посетителю он нужен не будет. Поэтому, такие запросы нам не нужны. Их мы ищем в ручном режиме.
Оставшийся список запросов мы не спеша и внимательно листаем до самого конца в поисках таких фраз и обнаружения новых стоп-слов. Если обнаружили какое-то слово, употребляющееся много раз, то просто добавляем его в уже существующий список стоп-слов и жмем на кнопку «Отметить фразы в таблице». В конце списка, когда по ходу ручной проверки мы отметили все ненужные запросы, удаляем отмеченные фразы и первый этап составления семантического ядра окончен.
Получили определенное семантическое ядро. Оно еще не совсем полное, но уже позволит написать максимально возможную часть текстов.
Осталось лишь добавить к нему еще небольшую часть запросов, которую мы могли упустить. В этом помогут следующие этапы.
Этап 2 – конкуренты
В самом начале мы собрали список общих фраз, относящихся к нише. В нашем случае это были:
- Заболевания сердца
- Инфаркт;
- Ишемическая болезнь сердца;
- Аритмия;
- Гипертония;
- Порок сердца;
- Стенокардия и т.д.
Все они относятся именно к нише «Болезни сердца». По этим фразам необходимо в поиске найти сайты конкурентов именно по данной теме.
Вбиваем каждую из фраз и ищем конкурентов. Важно, чтобы это были не общетематические (в нашем случае медицинские сайты общей направленности, т.е. про все болезни). Нужны именно нишевые проекты. В нашем случае - только про сердце. Ну может быть еще и про сосуды, т.к. сердце связано с сосудистой системой. Мысль, думаю, вы поняли.
Если у нас ниша «Рецепты салатов с мясом», тогда в перспективе только такие сайты и искать. Если их нет, то старайтесь найти сайты только про рецепты, а не в общем про кулинарию, где все обо всем.
Если же общетематический сайт (общемедицинский, женский, про все виды стройки и ремонта, кулинария, спорт), тогда придется очень помучиться, как в плане составления самого семантического ядра, т.к. придется долго и нудно пахать – собирать основной список запросов, долго ждать процесса парсинга, чистить и группировать.
Если на 1й, а иногда и даже на 2й странице, не удается найти узкие тематические сайты конкурентов, тогда попробуйте использовать не основные запросы, которые мы сформировали перед самим парсингом на 1м этапе, а запросы уже из всего списка после парсинга. Например:
- Как лечить аритмию народными средствами;
- Симптомы аритмии у женщин и так далее.
Дело в том, что такие запросы (аритмия, болезни сердца, порок сердца…) имеют самую высокую конкурентность и по ним выбиться в ТОП практически нереально. Поэтому, на первых позициях, а может быть и на страницах, вы вполне реально найдете только общетематические порталы обо всем в виду их огромнейшей авторитетности в глазах поисковых систем, возраста и ссылочной массы.
Так что вполне разумно использовать для поиска конкурентов более низкочастотные фразы, состоящие из большего количества слов.
Нужно спарсить их запросы. Можно использовать сервис SpyWords, но функция анализа запросов в нем доступна на платном тарифе, стоимость которого довольно большая. Поэтому для одного ядра нет смысла обновлять тариф на этом сервисе. Если нужно собрать несколько ядер на протяжении месяца, например 5-10, тогда можно купить аккаунт. Но опять же – только при наличии бюджета на тариф PRO.
Также можно использовать статистику Liveinternet, если она открыта для просмотра. Очень часто владельцы делают ее открытой для рекламодателей, но закрывают раздел «поисковые фразы», а именно он нам и нужен. Но все же имеются сайты, когда этот раздел открыт для всех. Очень редко, но имеются.
Самым простым способом является банальный просмотр разделов и карты сайта. Иногда мы можем упустить не только какие-то общеизвестные фразы ниши, но и специфические запросы. На них может и не так много материалов и под них не создашь отдельный раздел, но пару десятков статей они могут прибавить.
Когда мы нашли еще список новых фраз для сбора, запускаем тот же сбор поисковых фраз из левой колонки Яндекс Вордстат, как и на первом этапе. Только запускаем мы его уже, находясь во второй группе «Конкуренты», чтобы запросы добавлялись именно в нее.
- После парсинга собираем точные частотности поисковых фраз;
- Задаем фильтр и перемещаем (удаляем) запросы с частотностью менее 30 в отдельную группу;
- Чистим от мусора (стоп-слова и запросы, не относящиеся к нише).
Итак, получили еще небольшой список запросов и семантическое ядро стало более полным.
Этап 3 – расширение
У нас уже есть группа с названием «1-2». В нее мы копируем фразы из групп «Основной список запросов» и «Конкуренты». Важно именно скопировать, а не переместить, чтобы в предыдущих группах все фразы на всякий случай остались. Так будет безопасней. Для этого в окне переноса фраз нужно выбрать вариант «копирование».
Получили все запросы с 1-2 этапов в одной группе. Теперь нужно оставить в этой группе всего 10% самых частотных запросов от всего количества и которые содержат не менее 2х слов. Также их должно быть не более 100 штук. Уменьшаем, чтобы не закопаться в процесс сбора ядра на месяц.
Сперва применяем фильтр, в котором зададим условие, чтобы показывались минимум 2х словные фразы.

Отмечаем все фразы в оставшемся списке. Нажав на колонку «Частотность!», сортируем фразы по убыванию количества показов, чтобы в верху были самые частотные. Далее выделяем первые 10% из оставшегося числа запросов, снимаем с них отметку (правая кнопка мыши – снять отметку с выделенных строк) и удаляем отмеченные фразы, чтобы остались только эти 10%. Не забываем, что если ваши 10% будут более 100 слов, тогда на 100й строке останавливаемся, больше не нужно.
Теперь проводим расширение с помощью функции кейколлектора. Поможет в этом сервис Rookee.

Параметры сбора указываем, как на скриншоте ниже.

Сервис соберет все расширения. Среди новых фраз могут быть очень длинные ключи, а также символы, поэтому не для всех получится собрать частотность через Яндекс Директ. Придется потом дособрать статистику с помощью кнопки от вордстата.
После получения статистики убираем запросы с месячными показами менее 30 и проводим чистку (стоп-слова, мусор, неподходящие к нише ключи).
Этап закончен. Получили еще список запросов.
Этап 4 – сбор лучших словоформ
Как говорил ранее, целью не является определить такую форму фразы, которая будет более правильной.
В большинстве случаев (исходя из моей практики) сбор лучших словоформ укажет на ту же фразу, что и имеется в списке запросов. Но, без сомнения, будут и такие запросы, к которым будет указана новая словоформа, которой еще нет в семантическом ядре. Это дополнительные ключевые запросы. Этим этапом мы добиваем ядро до максимальной полноты.
При сборе своего ядра данный этап дал еще 107 дополнительных запросов.
Сперва мы копируем ключи в группу «1-3» из групп «Основные запросы», «Конкуренты» и «1-2». Должна получиться сумма всех запросов со всех ранее проделанных этапов. Далее используем сервис Rookee по той же кнопке, что и делали расширение. Только выбираем другую функцию.

Начнется сбор. Фразы будут добавляться в новую колонку «Лучшая форма фразы ».

Лучшая форма будет определена не ко всем фразам, так как сервис Rookee попросту не знает все лучшие формы. Но ля большинства результат будет положительным.
Когда процесс окончен, нужно добавить эти фразы ко всему списку, чтобы они находились в той же колонке «Фраза». Для этого выделяете все фразы в колонке «Лучшая форма фразы», копируете (правая кнопка мыши - копировать), далее жмете на большую зеленую кнопку «Добавить фразы» и вносите их.
Убедиться в том, что фразы появились в общем списке очень просто. Так как при подобном добавлении фраз в таблицу происходит в самый низ, то листаем в самый низ списка и в колонке «Источник» мы должны видеть иконку кнопки добавления.

Фразы, добавленные с помощью расширений, будут помечены иконкой руки.
Так как частотность для лучших словоформ не определена, то нужно это сделать. Аналогично предыдущим этапам выполняем сбор количества показов. Не бойтесь, что сбор осуществляем в той же группе, где находятся остальные запросы. Сбор просто продолжится для тех фраз, которые имеют пустые ячейки.
Если вам будет удобней, тогда изначально вы можете добавить лучшие словоформы не в ту же группу, где они и были найдены, а в новую, чтобы там были только они. И уже в ней собрать статистику, очистить от мусора и так далее. А уже потом оставшиеся нормальные фразы добавить ко всему списку.
Вот и все. Семантическое ядро сайта собрано. Но работы еще осталось немало. Продолжаем.
Перед следующими действиями нужно выгрузить все запросы с необходимыми данными в excel файл на компьютер. Настройки экспорта мы выставили ранее, поэтому можно сразу его и сделать. За это отвечает пиктограмма экспорта в главном меню KeyCollector.

Открыв файл, должны получить 4 колонки:
- Фраза;
- Источник;
- Частотность!;
- Лучшая форма фразы.
Это наше итоговое семантическое ядро, содержащее максимальный чистый и необходимый список запросов для написания будущих текстов. В моем случае (узкая ниша) получилось 1848 запросов, что равняется приблизительно 250-300 материалам. Точно сказать не могу - полностью еще на разгруппировал все запросы.
Для немедленного применения это еще сырой вариант, т.к. запросы находятся в хаотичном порядке. Нужно еще раскидать их по группам, чтобы в каждой были ключи к одной статье. Это и является окончательной целью.
Разгруппировка семантического ядра
Этот этап выполняется довольно быстро, хотя и с некоторыми сложностями. Поможет нам сервис http://kg.ppc-panel.ru/ . Имеются и другие варианты, но будем использовать этот в виду того, что с ним мы сделаем все в соотношении качество/скорость. Тут нужна не скорость, а в первую очередь качество.
Очень полезной вещью сервиса является запоминание всех действий в вашем браузере по кукам. Если даже, вы закроете эту страницу или браузер в целом, то все сохранится. Таким образом нет нужды делать все за один раз и бояться, что в один момент может все пропасть. Продолжить можно в любое время. Главное не чистить куки браузера.
Пользование сервисом я покажу на примере нескольких выдуманных запросов.
Переходим на сервис и добавляем все семантическое ядро (все запросы из excel файла), экспортированное ранее. Просто копируем все ключи и вставляем их в окно, как показано на изображении ниже.
Они должны появится в левой колонке «Ключевые слова».
На наличие закрашенных групп в правой стороне не обращайте внимание. Это группы из моего предыдущего ядра.
Смотрим на левую колонку. Имеется добавленный список запросов и строка «Поиск/фильтр». Фильтром мы и будем пользоваться.
Технология очень проста. Когда мы вводим часть какого-то слова или фразы, то сервис в режиме реального времени оставляет в списке запросов только те, что содержат введенное слово/фразу в самом запросе.
Более наглядно смотрите ниже.

Я хотел найти все запросы, относящиеся к аритмии. Ввожу слово «Аритмия» и сервис автоматически оставляет в списке запросов только те, что содержат введенное слово или его часть.
Фразы переместятся в группу, которая будет называться одной из ключевых фраз этой группы.
Получили группу, где лежат все ключевые слова по аритмии. Чтобы увидеть содержимое группы, кликните на нее. Немного позже мы будем эту группу еще разбивать на более мелкие группы, так как с аритмией есть очень много ключей и все они под разные статьи.
Таким образом на начальном этапе группировки нужно создать большие группы, которые объединяют большое количество ключевых слов из одного вопроса ниши.
Если взять в пример ту же тематику сердечных болезней, тогда сначала я буду создавать группу «аритмия», потом «порок сердца», затем «инфаркт» и так далее пока не будет групп по каждой из болезни.
Таких групп, как правило, будет практически столько же, сколько и основных фраз ниши, сгенерированных на 1м этапе сбора ядра. Но в любом случае, их должно быть больше, так как имеются еще фразы с 2-4го этапов.
Некоторые группы могут содержать вообще 1-2 ключа. Это может быть связано, например с очень редким заболеванием и про него никто не знает или никто не ищет. Поэтому и запросов нет.
В общем, когда основные группы созданы, необходимо их разбить на более мелкие группы, которые и будут использованы для написания отдельных статей.
Внутри группы напротив каждой ключевой фразы есть крестик, нажав на который, фраза удаляется из группы и обратно попадает в неразгруппированный список ключевых слов.
Таким образом и происходит дальнейшая группировка. Покажу на примере.
На изображении вы можете видеть, что имеются ключевые фразы, связанные с лечением аритмии. Если мы хотим их определить в отдельную группу для отдельной статьи, тогда удалям их из группы.

Они появятся в списке левой колонки.
Если в левой колонке еще присутствуют фразы, тогда, чтобы найти удаленные ключи из группы, придется применить фильтр (воспользоваться поиском). Если же список полностью находится по группам, тогда там будут только удаленные запросы. Мы их отмечаем и жмем на «Создать группу».

В колонке «Группы» появится еще одна.
Таким образом мы распределяем все ключи по темам и под каждую группу в конечно итоге пишется отдельная статья.
Единственная сложность сего процесса заключается в анализе необходимости разгруппировки некоторых ключевиков. Дело в том, что имеются ключи, которые по своей сути разные, но они не требуют написания отдельных текстов, а пишется подробный материал по многих вопросам.
Это ярко выражено именно в медицинской тематике. Если взять пример с аритмией, то нет смысла делать ключи «аритмия причины» и «аритмия симптомы». Ключи про лечение аритмии еще под вопросом.
Узнается это после анализа поисковой выдачи. Заходим в поиск Яндекса и вбиваем анализируемый ключ. Если видим, что в ТОПе находятся статьи, посвященные только симптомам аритмии, тогда данный ключ выделяем в отдельную группу. Но, если же тексты в ТОПе раскрывают все вопросы (лечение, причины, симптомы, диагностика и так далее), тогда разгруппировка в данном случае не нужна. Все эти темы раскрываем в рамках одной статьи.
Если в Яндексе находятся именно такие тексты на верхушке выдачи, тогда это знак, что разгруппировку делать не стоит.
Тоже самое можно привести на примере ключевой фразы «причины выпадения волос». Могут быть подключи «причины выпадения волос у мужчин» и «…у женщин». Очевидно, что под каждый ключ можно написать отдельный текст, если исходить из логики. Но о чем скажет Яндекс?
Вбиваем каждый ключ и смотрим, какие же тексты там присутствуют. Под каждый ключ там отдельные подробные тексты, тогда ключи разгруппированием. Если же в ТОПе по обеим запросам находятся общие материалы по ключу «причины выпадения волос», внутри которого раскрыты вопросы касаемо женщин и мужчин, тогда оставляем ключи в рамках одной группы и публикуем один материал, где раскрываются темы по всем ключам.
Это важно, так как поисковая система не зря определяет тексты в ТОП. Если на первой странице находятся исключительно подробные тексты по определенному вопросу, тогда велика вероятность, что разбив большую тему на подтемы и написав по каждой материал, вы не попадаете в ТОП. А так один материал имеет все шансы получить хорошие позиции по всем запросам и собирать по ним хороший трафик.
В медицинских тематиках этому моменту нужно уделять много внимания, что значительно усложняет и замедляет процесс разгруппировки.
В самом низу колонки «Группы» имеется кнопка «Выгрузить». Жмем на нее и получаем новую колонку с текстовым полем, содержащим все группы, разделенные между собой строчным отступом.
Если не все ключи находятся в группах, то в поле «Выгрузка» пробелов между ними не будет. Они появляются только при полностью выполненной разгруппировке.
Выделяем все слова (комбинация клавиш Ctrl+A), копируем их и вставляем в новый excel файл.
Ни в коем случае не жмем на кнопку "Очистить все", так как удалится абсолютно все, что вы проделали.
Этап разгруппировки окончен. Теперь можно смело писать по тексту под каждую группу.
Но, для максимальной эффективности, если бюджет вам не позволяет выписать все сем. ядро за пару дней, а имеется лишь строго ограниченная возможность для регулярной публикации небольшого количества текстов (10-30 в месяц, к примеру), тогда стоит определить конкуренцию всех групп. Это важно, так как группы с наименьшей конкуренцией дают результат в первые 2-3-4 месяца после написания без каких-либо ссылок. Достаточно лишь написать качественный конкурентноспособный текст и правильно его оптимизировать. Дальше за вас все сделает время.
Определение конкуренции групп
Сразу хочу отметить, что низко-конкурентный запрос или группа запросов не означает, что они являются сильно микро низкочастотными. Вся прелесть и есть в том, что достаточно приличное количество запросов, которые имеют низкую конкуренцию, но при этом обладают высокой частотностью, что сразу же дает выход такой статье в ТОП и привлечение солидного трафика на один документ.
Например, вполне реальная картина, когда группа запросов имеет конкуренцию 2-5, а частотность порядка 300 показов в месяц. Написав всего 10 таких текстов, после выхода их в ТОП, мы будем получать 100 посетителей ежедневно минимум. И это всего 10 текстов. 50 статей – 500 посещений и эти цифры взяты и потолка, так как это берется в учет лишь трафик по точным запросам в группе. Но привлекаться же трафик будет еще и по другим хвостам запросов., а не только по тем, что находятся в группах.
Вот почему так важно определить конкуренцию. Иногда вы можете видеть ситуацию, когда на сайте 20-30 текстов, а уже 1000 посещений. И причем сайт молодой и ссылок нет. Теперь вы знаете, с чем это связано.
Конкуренцию запросов можно определять через тот же KeyCollector абсолютно бесплатно. Это очень удобно, но в идеале данный вариант не являются правильным, так как формула определения конкурентности постоянно меняется с изменением алгоритмов поисковых систем.
Лучше определять конкуренцию с помощью сервиса http://mutagen.ru/ . Он платный, но более максимально приближенный к реальным показателям.
100 запросов стоят всего 30 рублей. Если у вас ядро на 2000 запросов, тогда вся проверка обойдется в 600 рублей. В сутки дается 20 бесплатных проверок (только тем, кто пополнил баланс на любую сумму). Можете каждый день оценивать по 20 фраз, пока не определите конкурентность всего ядра. Но это очень долго и глупо.
Поэтому, я пользуюсь именно мутагеном и ни имею к нему никаких претензий. Иногда бывают проблемы, связанные со скоростью обработки, но это не так критично, так как даже закрыв страницу сервиса, проверка продолжается в фоновом режиме.
Сам анализ сделать очень просто. Регистрируемся на сайте. Пополняем баланс любым удобным способом и по главному адресу (mutagen.ru) доступна проверка. В поле водим фразу и она сразу же начинает оцениваться.
Видим, что по проверяемому запросу конкурентность оказалась более 25. Это очень высокий показатель и может равняться любому числу. Сервис не отображает его реальным, так как это не имеет смысла в виду того, что такие конкурентные запросы практически нереально продвинуть.
Нормальный уровень конкуренции считается до 5. Именно такие запросы легко продвигаются без лишних телодвижений. Чуть более высокие показатели тоже вполне приемлемы, но запросы со значениями более 5 (например, 6-10) стоит использовать после того, как уже написали тексты под минимальную конкурентность. Важен максимально быстрый текста в ТОП.
Также во время оценки определяется стоимость клика в Яндекс.Директ. По ней можно оценить ваш будущий заработок. Во внимание берем гарантированные показы, значение которых можем смело делить на 3. В нашем случае можно сказать, что один клик по рекламе Яндекс директа нам будет приносить 1 рубль.
Сервис определяет и количество показов, но на них мы не смотрим, так как определяются частотность не вида "!запрос", а только "запрос". Показатель получается не точным.
Такой вариант анализа подойдет, если мы хотим проанализировать отдельный запрос. Если нужна массовая проверка ключевых фраз, тогда на главной странице сверху поля ввода ключа имеется специальная ссылка.

На следующей странице создаем новое задание и добавляем список ключей из семантического ядра. Берем их из того файла, где ключи уже разгруппированы.
Если на балансе достаточно средств для анализа, проверка сразу начнется. Продолжительность проверки зависит от количества ключей и может занять некоторое время. 2000 фраз я анализировал порядка 1го часа, когда во второй раз проверка всего 30 ключей заняла аж несколько часов.
Сразу после запуска проверки вы увидите задание в списке, где будет колонка "Статус". По ней вы и поймете, готово ли задание или нет.
Кроме этого после выполнения задания вы сразу сможете скачать файл со список всех фраз и уровнем конкуренции для каждой. Фразы будут все в таком порядке, как они и были разгруппированы. Единственное, будут удалены пробелы между группами, но это не страшно, т.к.все будет интуитивно понятно, ведь каждая группа содержит ключи на другую тему.
Кроме этого, если задание еще не выполнилось, вы можете зайти внутрь самого задания и посмотреть результаты конкуренции для уже выполненных запросов. Просто нажмите на название задания.
В пример покажу результат проверки группы запросов для семантического ядра. Собственно, эта та группа, под которую писалась данная статья.
Видим, что практически все запросы имеют максимальную конкуренцию 25 или же ближе к ней. Это значит, что по этим запросам, мне либо вообще не видать первых позиций или же не видать их очень долго. Такой материал бы на новом сайте я вообще не писал.
Сейчас же я его опубликовал только для создания качественного контента на блог. За цель конечно ставлю вывести в топ, но это уже позже. Если на первую страницу хотя бы лишь по главному запросу мануал и выйдет, тогда я уже могу рассчитывать не солидный трафик только на эту страницу.
Последним шагом осталось создать окончательный файл, на который мы и будем смотреть в процессе наполнения сайта. Семантическое ядро сайта то уже собрано, но вот управляться с ним не совсем удобно пока.
Создание финального файла со всеми данными
Нам снова понадобится KeyCollector, а также последний файл excel, который мы получили с сервиса mutagen.
Открываем ранее полученный файл и видим примерно следующее.
Из файла нам потребуются только 2 колонки:
- ключ;
- конкуренция.
Можно просто удалить все остальное содержимое из этого файла, чтобы остались только необходимые данные или же создать совсем новый файл, сделать там красивую строку заголовка с наименованием колонок, выделив ее, например, зеленым цветом, и в каждую колонку скопировать соответствующие данные.
Далее копируем все семантическое ядро из этого документа и снова добавляем его в кейколлектор. Потребуется заново собрать частотности. Это нужно, чтобы собрались частотности в таком порядке, как и расположены ключевые фразы. Ранее мы их собирали, чтобы отсеять мусор, а сейчас для создания финального файла. Фразы конечно же добавляем в новую группу.
Когда частотности собраны, мы экспортируем файл из весь столбик с частотностью копируем в финальный файл, где будут 3 колонки:
- ключевая фраза;
- конкурентность;
- частотность.
Теперь осталось немного посидеть и для каждой группы посчитать:
- Средний показатель частотности группы - важен не показатель каждого ключа, а средний показатель группы. Считается, как обычное среднеарифметическое (в excel - функция "СРЗНАЧ");
- Общую частотность группы поделить на 3, чтобы привести возможный трафик к реальным цифрам.
Чтобы вам не мучиться с освоением расчетов в excel, я подготовил для вас файл, куда вам просто в нужные колонки нужно внести данные и все будет посчитано на полном автомате. Каждую группу нужно рассчитывать в отдельности.
Внутри будет простой пример расчета.
Как видите, все очень просто. Из финального файла просто копируете все фразы группы целиком со всеми показателями и вставляете в этот файл на место предыдущих фраз с их данными. И автоматически произойдет расчет.
Важно, чтобы колонки в финальном файле и в моем были именно в таком порядке. Сначала фраза, потом частотность, а уже потом только конкуренция. Иначе, насчитаете ерунду.
Далее придется немного посидеть, чтобы создать еще один файл или лист (рекомендую) внутри файла со всеми данными о каждой группе. Этот лист будет содержать не все фразы, а лишь главную фразу группы (по ней мы будем определять, что за группа) и посчитанные значения группы из моего файла. Это своего рода окончательный файл с данными о каждой группе с посчитанными значениями. На него я и смотрю, когда выбирают тексты для публикации.
Получится все те же 3 колонки, только без каких-либо подсчетов.
В первую мы вставляем главную фразу группы. В принципе, можно любую. Она нужна лишь для того, чтобы ее скопировать и через поиск найти местоположение всех ключей группы, которые находятся на другом листе.
Во вторую мы копируем посчитанное значение частотности из моего файла, а в третью - среднее значение конкуренции группы. Берем мы эти числа из строки "Результат".
В итоге получится следующее.
Это 1й лист. На втором листе находится все содержимое финального файла, т.е. все фразы с показателями их частотности и конкуренции.
Теперь мы смотрим на 1й лист. Выбираем максимально "рентабельную" группу ключей. Копируем фразу из 1й колонки и находим ее с помощью поиска (Ctrl+F) во втором листе, где рядом с ней будут находиться остальные фразы группы.
Вот и все. Мануал подошел к концу. На первый взгляд все очень сложно, но на самом деле - достаточно просто. Как уже говорил в самом начале статьи - стоит лишь начать делать. В будущем я планирую сделать видео-мануал по этой инструкции.
Ну а на этой ноте я заканчиваю инструкцию.
Все, друзья. Буду какие-то пожелания, вопросы - жду в комментариях. До связи.
P. S. Рекорд по объему контента. В Word получилось более 50 листов мелким шрифтом. Можно было не статью публиковать, а создать книгу.
С уважением, Константин Хмелев!
Перед началом seo продвижения нужно составить семантическое ядро сайта — список поисковых запросов, который используют при поиске предлагаемых нами товаров или услуг потенциальные клиенты. Все дальнейшие работы — внутренняя оптимизация и работа с внешними факторами (покупка ссылок) ведутся в соответствии с определенном на этом этапе списком запросов.
От правильного сбора ядра также зависит итоговая стоимость продвижения и даже предполагаемый уровень конверсии (количество обращений в компанию).
Чем большее количество компаний продвигается по выбранному слову, тем выше конкуренция и соответственно стоимость продвижения.
Также при выборе списка запросов следует не только полагаться на свои представления о том, какие слова используют ваши потенциальные клиенты, но и доверять мнению профессионалов, ведь далеко не все дорогие и популярные запросы обладают высокой конверсией и продвижение некоторых из напрямую относящихся к вашему бизнесу слов может быть просто невыгодным, даже при возможности достичь идеального результата в виде ТОП-1.
Правильно сформированное семантическое ядро, при прочих равных, обеспечивает уверенное нахождение сайта на верхних позициях поисковой выдачи для широкого спектра запросов.
Принципы составления семантики
Поисковые запросы формируют люди – потенциальные посетители сайта, исходя из своих целей. Угнаться за математическими методами статистического анализа, заложенными в алгоритм работы роботов — поисковиков трудно, тем более, что они непрерывно уточняются, совершенствуются, а значит меняются.
Самый действенный способ охватить при формировании семантического ядра сайта максимальное число возможных запросов – это посмотреть на него как бы с позиции человека, делающего запрос в поиске.
Поисковик создан для того, чтобы помочь человеку быстро выйти на наиболее подходящий поисковому запросу источник информации. Поисковик ориентирован, прежде всего, на быстрый способ сузить до нескольких десятков наиболее подходящих вариантов ответов под ключевую фразу (слово) запроса.
При формировании списка этих ключевых слов, которые будут основой семантики сайта, фактически определяется круг его потенциальных посетителей.
Этапы сбора семантического ядра:
- Вначале составляется перечень основных ключевых фраз и слов, встречающихся в информационном поле сайта и характеризующих его целевую направленность. При этом можно использовать последнюю статистическую информацию о частоте запросов по рассматриваемому направлению от поисковой системы. Кроме основных вариантов слов и фраз необходимо также выписать их синонимы и варианты других названий: стиральный порошок – моющее средство. Для этой работы прекрасно подойдет сервис Яндекс Вордстат .

- Можно выписать и составные части названия какого-либо товара или предмета запроса. Очень часто в запросы попадают и слова с описками, опечатками или просто неправильно написанные в силу недостаточной грамотности большой части пользователей Интернета. Учёт этой особенности тоже может привлечь дополнительный ресурс посетителей сайта, особенно в случае появления каких-либо новых названий.
- Наиболее общие запросы, их ещё называют высокочастотными, редко приводят человека на искомый сайт. Лучше работают низкочастотные, то есть запросы с уточнением. Например, запрос Кольцо выдаст один топ, а поршневое кольцо – это уже более конкретная информация. Ориентироваться при сборе лучше именно на такие запросы. Этим будет привлекаться целевые посетители, то есть, например, потенциальные покупатели, если это коммерческий сайт.
- При составлении перечня ключевых слов целесообразно также учитывать и широко распространённые жаргонные, так называемые народные, ставшие общепринятыми и устойчивыми названия некоторых предметов, понятий, услуг и т.п., например, сотовый телефон – мобильный телефон – мобилка – мобильник. Учёт таких неологизмов в ряде случаев может дать существенный прирост целевой аудитории.
- И вообще, при составлении списка ключей лучше изначально ориентироваться именно на целевую аудиторию, то есть тех посетителей сайта, на кого рассчитан товар или услуга. В ядре не должно как основной вариант присутствовать малоизвестное название предмета (товара, услуги), даже если его необходимо раскрутить. Такие слова в запросах будут попадаться крайне редко. Лучше использовать их с уточнениями или применять более раскрученные близкие названия или аналоги.
- Когда семантика готова, его следует пропустить через ряд фильтров, чтобы убрать засоряющие ключи, а значит приводящие на сайт не целевую аудиторию.
Учёт в семантике ассоциированных запросов
- К первоначальному списку семантического ядра, составленному из основных ключей, следует добавить ряд вспомогательных низкочастотных, в которые могу входить важные, но не учтённые слова, которые не пришли в голову при его составлении. В этом хорошо поможет сам поисковик. При повторном наборе ключевых фраз из списка по теме, поисковик сам предлагает к рассмотрению варианты часто встречающихся фраз по этому направлению.
- Например, если вводится фраза – ремонт компьютеров, а затем второй запрос – матрица, то поисковая система будет их воспринимать ассоциированными, то есть взаимосвязанными по смыслу, и в помощь выдаст различные часто встречающиеся запросы по этому направлению. Такими ключевыми фразами можно расширить исходную семантику.
- Зная несколько главных слов из ядра, с помощью поисковой системы его можно значительно расширить ассоциированными фразами. В случае, когда поисковик выдаёт недостаточное количество таких дополнительных ключей, можно их получить, используя методы тезауруса – набора понятий (терминов) для конкретного предмета из той же понятийной области. Здесь могут помочь словари и справочники.
 Логическая схема подбора семантики для сайта
Логическая схема подбора семантики для сайта Формирование списка запросов и окончательное их редактирование
- Сформированные на первых двух шагах ключевые фразы, составляющие семантику, требуют их фильтрации. Среди таких фраз могут оказаться бесполезные, которые будут только утяжелять ядро, не принося никакой ощутимой пользы по привлечению целевой аудитории посетителей сайта. Фразы, полученные с помощью анализа целевой направленности сайта и расширенные с помощью ассоциированных ключей, получили название маски. Это важный перечень, позволяющий сделать сайт видимым, то есть, при работе поисковика в ответ на запрос будет выдаваться в списке предлагаемых и этот сайт.
- Теперь необходимо создать списки поисковых запросов по каждой маске. Для этого потребуется воспользоваться поисковой системой, под которую ориентируется этот сайт, например, Яндекс, Рамблер, Google или др. Созданный список под каждую маску подлежит дальнейшему редактированию и зачистке. Эта работа проводится, исходя из уточнения размещённой на сайте информации, а также собственно оценок поисковой системы.
- Зачистка заключается в удалении ненужных, неинформативных и вредных запросов. Например, если в список сайта стройматериалов попали фразы со словами «курсовая работа», то его надо удалить, так как вряд ли он расширит целевую аудиторию. После зачистки и окончательного редактирования получится вариант реально работающих ключевых запросов, наполнение под которые продвинет сайт в зону так называемой видимости для поисковых систем. В этом случае поисковый автомат по внутренним ссылкам сайта сможет показать нужную страницу из семантического ядра.
Подытоживая все вышесказанное, можно коротко сказать, что семантика сайта определяется общим количеством применяемых формулировок запросов поисковой системы и их суммарной частотой в статистике обращений по конкретному запросу.
Все работы по формированию и редактированию семантики можно свести к следующим:
- анализ размещаемой на сайте информации, целей, преследуемых созданием данного сайта;
- составление общего перечня возможных фраз, исходя из анализа сайта;
- формирование расширенного варианта ключевиков с помощью ассоциированных запросов (маски);
- формирование списка вариантов запросов по каждой маске;
- редактирование (зачистка) списка с целью исключения малозначимых фраз.
Из этой статьи вы узнали что такое семантическое ядро сайта и как его нужно составлять.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его
вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :
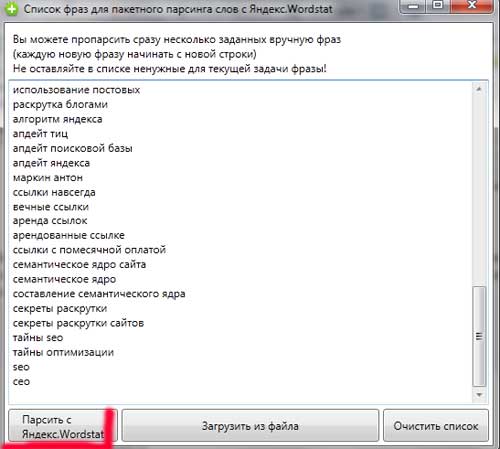
Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:
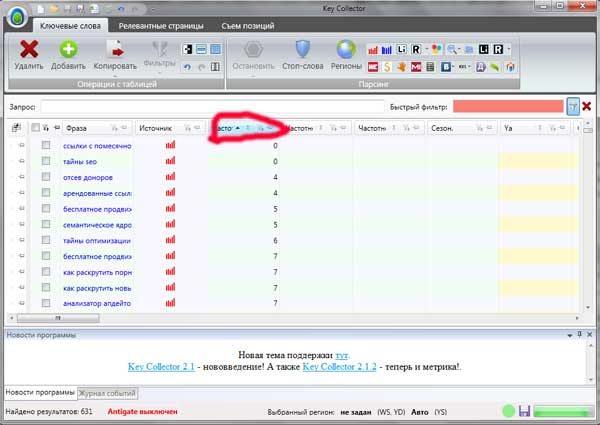
Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:
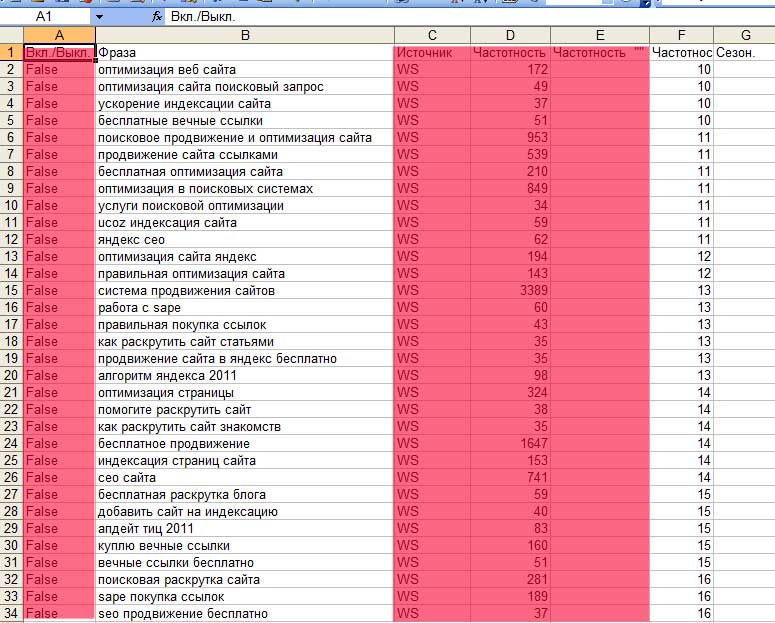
Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:


Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника
Помимо того, сайта, важно знать, как правильно его применить с максимальной пользой для внутренней и внешней оптимизации сайта.
Уже очень много статей написано на тему того как сделать семантическое ядро, поэтому, в рамках данной статьи, я хочу обратить Ваше внимание на некоторые особенности и детали, которые помогут Вам правильно использовать семантическое ядро, и тем самым, помочь раскрутить интернет-магазин или сайт. Но сперва, вкратце дам свое определение семантическому ядру сайта.
Что такое семантическое ядро сайта?
Семантическое ядро сайта - это список, набор, массив, совокупность ключевых слов и фраз, которые запрашиваются пользователями (Вашими потенциальными посетителями) в браузерах поисковых систем, чтобы найти интересующую информацию.
Зачем нужно веб-мастеру составлять семантическое ядро?
Исходя из определения семантического ядра, возникает масса очевидных ответов на этот вопрос.
Владельцам интернет-магазинов важно знать, каким образом потенциальные покупатели пытаются найти тот товар или услугу, которую владелец интернет-магазина желает продать или предоставить. От этого понимания напрямую зависит положение интернет-магазина в поисковой выдаче. Чем более соответствует наполнение интернет-магазина покупательским поисковым запросам - тем ближе интернет-магазин к ТОПу поисковой выдачи. А значит, конверсия посетителей в покупатели будет выше и качественнее.
Для блоггеров, которые активно занимаются монетизацией своих блогов (манимейкингом), также важно быть в ТОПе поисковой выдачи по тематике релевантной содержанию блога. Увеличение поискового трафика несет больше прибыли от показов и кликов из контекстной рекламы на сайте, показов и кликов по рекламным блокам партнёрских программ и рост прибыли по другим видам заработка.
Чем больше на сайте оригинального и полезного контента - тем ближе сайт к ТОПу. Жизнь существует преимущественно на первой странице выдачи поисковых систем. Поэтому, знание того как сделать семантическое ядро является необходимым для SEO любого сайта, интернет-магазина.
Иногда веб-мастера и владельцы интернет-магазинов задаются вопросом - где брать качественный и релевантный контент? Ответ исходит из вопроса - нужно создавать контент в соответствии с ключевыми запросами пользователей. Чем больше поисковые системы будут считать контент Вашего сайта релевантным (подходящим) ключевым словам пользователей - тем лучше для Вас. Кстати, отсюда возникает ответ на вопрос - где брать разнообразие тематики контента? Всё просто - анализируя поисковые запросы пользователей, можно узнать чем они интересуются и в какой форме. Таким образом, сделав семантическое ядро сайта, можно написать ряд статей и/или описаний для товаров интернет-магазина, оптимизируя каждую страницу для определенного ключевого слова (поискового запроса).
К примеру, данную статью я решил оптимизировать по ключевому запросу "как сделать семантическое ядро", потому что конкуренция по данному запросу ниже, чем по запросу "как создать семантическое ядро" или "как составить семантическое ядро". Таким образом, мне гораздо легче пробиться к ТОПу выдачи поисковых систем по этому запросу абсолютно бесплатными методами раскрутки.
Как сделать семантическое ядро, с чего начать?
Для составления семантического ядра существует ряд популярных он-лайн сервисов.
Самым популярным сервисом, на мой взгляд, является статистика ключевых слов Яндекса - http://wordstat.yandex.ru/
При помощи данного сервиса можно собрать подавляющее большинство поисковых запросов в различных словоформах и комбинациях для любой тематики. Например, в левой колонке мы видим статистику количества запросов не только по ключевой фразе "семантическое ядро", но и статистику по различным комбинациям данной ключевой фразы в разных спряжениях и с разбавочными и дополнительными словами. В левой колонке мы видим статистику поисковых фраз, которые искали вместе с ключевой фразой "семантическое ядро". Эта информация может быть ценной, хотя бы в качестве источника тем для создания нового, релевантного Вашему сайту, контента. Ещё хочу упомянуть одну особенность этого сервиса - Вы можете уточнить регион. Благодаря этой опции Вы можете более точно узнать количество и характер нужных Вам поисковых запросов по нужному региону.

Ещё одним сервисом для составления семантического ядра является статистика поисковых запросов рамблера - http://adstat.rambler.ru/

На мой субъективный взгляд, данным сервисом можно пользоваться в том случае, когда идёт битва за привлечение на свой сайт каждого единичного пользователя. Здесь можно уточнить некоторые низкочастотные и long tail запросы, обращение пользователей по ним составляет приблизительно от 1 до 5-10 в месяц, т.е. очень мало. Сразу же оговорюсь, что в дальнейшем мы рассмотрим тему классификации ключевых слов и особенности каждой группы с точки зрения их применения. Поэтому, лично я крайне редко пользуюсь данной статистикой, как правило в тех случаях, если я занимаюсь или узкоспециализированного сайта.
Для формирования семантического ядра сайта также можно пользоваться подсказками, которые выпадают при вводе поискового запроса в браузере поисковика.


И ещё один вариант для жителей Украины пополнить список ключевых слов для семантического ядра сайта - просмотреть статистику сайтов на - http://top.bigmir.net/

Выбрав нужную тематику раздела, ищем открытую статистику наиболее посещаемого и подходящего по тематике сайта

Как видите, интересующая статистика не всегда может быть открытой, как правило, веб-мастера скрывают её. Тем не менее, в качестве дополнительного источника ключевых слов тоже может сгодиться.
Кстати, о том как оформить красиво в табличном виде в Excel весь список ключевых слов Вас научит замечательная статья Глобатора (Михаила Шакина) - http://shakin.ru/seo/keyword-suggestion.html Там же можно прочесть о том как сделать семантическое ядро для англоязычных проектов.
Что делать дальше со списком ключевых слов?
В первую очередь чтобы сделать семантическое ядро, я рекомендую структурировать список ключевых слов - разбить его на условные группы: на высокочастотные (ВЧ), среднечастотные (СЧ) и назкочастотные (НЧ) ключевые слова. Важно, чтобы в данные группы попадали ключевые слова очень близкие по морфологии и тематике. Сделать это удобнее всего в виде таблицы. Я это делаю приблизительно так:

Верхняя строка таблицы - это высокочастотные (ВЧ) поисковые запросы (написаны красным). Их я поставил во главе тематических колонок, в каждую ячейку которых я отсортировал среднечастотные (СЧ) и низкочастотные (НЧ) поисковые запросы максимально однородно по тематике. Т.е. к каждому ВЧ запросу я привязал наиболее подходящие группы СЧ и НЧ запросов. Каждая ячейка СЧ и НЧ запросов - это будущая статья, которую я пишу и оптимизирую строго под набор ключевых слов в ячейке. В идеале, одна статья должна соответствовать одному ключевому слову (поисковому запросу), но это очень рутинная и затратная по времени работа, ведь таких ключевых слов могут быть тысячи! Поэтому, если их очень много, нужно выделить для себя самые значимые, а остальные отсеять. Также, можно оптимизировать будущую статью под 2 - 4 СЧ и НЧ ключевых слова.
Для интернет-магазинов, СЧ и НЧ поисковые запросы как правило, являются названиями товаров. Поэтому, здесь не возникает особых трудностей внутренняя оптимизация каждой страницы интернет-магазина, просто это длительный процесс. Он тем дольше, чем больше товаров в интернет-магазине.
Зеленым цветом я выделил те ячейки, на которые у меня уже готовы статьи, т.о. я в дальнейшем не запутаюсь со списком готовых статей.
О том как нужно оптимизировать и писать статьи для сайта я расскажу в одной из будущих статей.
Итак, сделав такую таблицу, Вы можете иметь весьма четкое представление о том, как можно сделать семантическое ядро сайта.
В итоге данной статьи, хочу сказать, что здесь мы в какой-то степени коснулись детализации вопроса о раскрутке интернет-магазина . Наверняка, прочитав некоторые мои статьи о раскрутке интернет-магазина Вам пришла мысль о том, что составление семантического ядра сайта и внутренняя оптимизация являются взаимосвязанными и взаимозависящими мероприятиями. Я надеюсь, что смог аргументировать важность и первоочередность вопроса - как сделать семантическое ядро сайта.
Здравствуйте, уважаемые читатели! Часто при личных беседах с веб-мастерами вижу непонимание важности ключевых слов для поискового продвижения. Поэтому я решил написать отдельный пост на эту важную тему. Что такое семантическое ядро сайта , его плюсы и минусы, пример готового ядра, советы по его правильному составлению — тема этой статьи. Вы узнаете, почему в плане seo-продвижения так важны для веб-ресурса правильно подобранные ключевики. Почувствуете их важность и исключительность, увидите силу от их использования.
Почему я написал этот пост? Во-первых, моя статья предназначена для начинающих веб-мастеров, которые только начали разбираться в сео продвижении. И во-вторых, в топ-20 в Яндексе нет ни одной статьи, которая подробно бы раскрыла пользователю из поиска суть семантического ядра. Исправим этот недочет. Надеюсь, русский поисковик это зачтет. 🙂
Понятие семантического ядра
Что это такое
Каждый из нас умеет пользоваться телефонным справочником. Будь то карманный алфавитный вариант в виде записной книжки или большой печатный талмуд всех телефонов города — принцип его использования очень прост. Мы ищем по определенной фамилии все контактные данные искомого человека. Для этого нам надо знать полностью ФИО человека. Обычно, уже зная фамилию человека, мы можем легко посмотреть в справочнике все записи и выбрать нужную. То есть, зная определенное слово (фамилия), мы можем получить все данные по человеку, которые записаны в книжке.

По такому принципу и работает семантика сайта — мы в поисковой системе набираем поисковый запрос (аналог той фамилии, контакты для которой ищем в справочнике) и получаем список самых точно отвечающих на него документов из различных веб-ресурсов. Эти документы являются отдельными страницами сайтов или блогов, контент на которых оптимизирован под запрашиваемый нами поисковый запрос, который называется ключевым словом. Таким образом, обычное семантическое ядро является набором поисковых запросов (ключевых слов), которые точно характеризуют тематику веб-ресурса, вид его деятельности (обычно для коммерческих сайтов, которые предлагают услуги или товары в сети Интернет).

Поэтому семантическое ядро выполняет очень важную функцию — оно позволяет веб-ресурсу получить на свои страницы пользователей из поисковых систем, которые необходимы для выполнения различных задач. Например, для коммерческого сайта такими задачами могут быть продажа товаров или услуг, для новостного портала — рекламирование сторонних источников с помощью контекстной или баннерной рекламы, для блога — рекламирование партнерских программ и т.д. То есть ядро является именно тем фундаментом, которое необходимо для получения поискового трафика с помощью seo продвижения. Без правильного и качественного набора ключевых слов получить такой трафик не реально.
Поэтому, если мы хотим использовать ресурсы и возможности поисковых систем для раскрутки своего веб-ресурса, ему нужно иметь грамотное семантическое ядро. Если же мы не хотим получать поисковый трафик, если нам не нужна целевая аудитория из поиска, то наличие семантики для нашего сайта не обосновано. Ключевые слова нам не нужны.
Типы семантического ядра
В поисковом продвижении существует основное и второстепенное семантическое ядро. Основное подразумевает под собой набор главных ключевых слов, с помощью которых данный сайт реализует поставленные перед ним цели и задачи. Например, это могут быть те поисковые запросы, по которым переходят из поиска потенциальные покупатели товаров или услуг на коммерческом сайте. То есть благодаря запросам основного ядра сайт или блог выполняют свое предназначение. Именно по таким ключевикам идет превращение обычного пользователя из поиска в клиента.
Второстепенное семантическое ядро позволяет веб-ресурсу решить менее значимые задачи или получить дополнительный трафик для привлечения большего числа потенциальных клиентов. В таком случае спектр ключевых слов может быть не только основной тематики сайта, но и смежных тем. Обычно используется в ряде коммерческих сайтов, которые хотят конвертировать посетителей с помощью дополнительных статей для продажи услуг или товаров на продающих страницах. Например, так поступают многие сайты, предоставляющие seo-услуги. На их веб-ресурсах кроме основных продающих и поясняющих страниц существует дополнительный большой набор документов, которые вместе образуют вариант блога.

У блоггеров основным ядром является список ключевых слов, которые приносят ему поисковый трафик, так как он и является основной задачей при монетизации блога с помощью целевой аудитории из поиска. А второстепенной семантики обычно у блога не бывает. Потому что какая бы ни была задача у блога, весь трафик по всем продвигаемым в поисковых системах страницам идет на решение его коммерческой задачи. Но, обычно ключевые слова по основной тематике дают намного больше коммерческих переходов, чем ключи непрофильной темы.
Что нужно знать при создании семантического ядра
Ключевые слова для семантического ядра выбираются по различным параметрам (частотность, конкурентность и т.д.). Об этом я подробно написал в . В зависимости от этих параметров подбираются семантические ядра для коммерческих сайтов, для блогов, для новостных порталов и т.д. Выбор тех или иных значений этих характеристик зависит от трех составляющих — от стратегии продвижения, от количества выделенного на него бюджета и тематики сферы деятельности продвигаемого сайта.
Стратегия продвижения диктует план подбора ключевых слов, акцентрируя свое внимание на взаимосвязь продвигаемых страниц с сайтом и их качество. Во-первых, здесь важна схема перелинковки страниц — от ее правильного выбора зависит число и важность документов, которые будут продвигаться в поисковых системах, Для каждого веб-ресурса схема должна быть своя, с помощью которой будет лучшее распределение веса на раскручиваемые документы. Во-вторых, необходимо знать объем контента продвигаемой страницы (для которого подбираются ключевики) — в зависимости от количества символов используется то или другое число ключевиков для нее.
От количества бюджета зависит возможность использования в семантическом ядре конкурентных запросов. Чем больше материальных средств может веб-мастер выделить на свой проект, тем лучшие слова он может включить в его семантику. Ведь не секрет, что самые качественные раскрученные ключевики всегда стоят приличных денег за попадание в топ-10 по ним. А значит для продвижения страниц по этим ключевым запросам недостаточно внутренней оптимизации — необходима закупка внешних ссылок, нужны материальные ресурсы для их закупки.
От тематики зависит в первую очередь минимальный порог частотности ключевого слова, который можно использовать для получения поискового трафика. Чем конкурентней тематика и чем она уже (в плане ее популярности), тем больше свой взор веб-мастер кидает в сторону низко- и микрочастотных слов (частотность их менее 50-100 в зависимости от тематики). Например, тема моего блога (seo и веб аналитика) очень узкая и большее число ключевых слов я не смогу использовать для создания семантического ядра. Поэтому большая часть ключевиков моего блога — это поисковые запросы НЧ и МК с частотностью не более 100. Если сравнить с популярными темами (например, кулинария — НЧ запросы в ней доходят до 1000!), то можно легко понять, что получить серьезный трафик по мелкой теме очень трудно — нужно иметь огромное число ключевых слов маленькой частотности (зато не конкурентной). А значит нужно иметь огромное число продвигаемых страниц.

План создания семантического ядра
Чтобы создать семантическое ядро, необходимо выполнить ряд последовательных действий:
- Выбрать те тематики сайта, для которых будут подбираться ключевые слова. Здесь необходимо выписать все направления деятельности, которой посвящен веб-ресурс. Если это интернет-магазин, значит выписываем основные категории товаров (отдельно для товаров обычно ключевые слова не ищут, если только товар не имеет номерной модели, а только общую). Если это блог, то все подтемы общей тематики, а также отдельные названия важных статей. Если сайт по предоставлению услуг, то будущими ключевыми словами будут названия этих услуг и т.д.
- На основе выбранных тематик составить список масок — первоначальных запросов, по которым будет парситься наше семантическое ядро. Более подробно по понятию списка Вы можете узнать из . еще один пост на эту тему, где описывается .
- Узнать регион продвижения Вашего сайта. В зависимости от местоположения ресурса некоторые ключевые слова могут иметь разную степень конкурентности. Чем уже и точнее регион, тем больше его важность в плане продвижения. Например, многие ключевые слова не так конкуренты по региону Россия, как по Москве.
- Спарсить всевозможные поисковые запросы с поисковой системы Яндекс и Google (если необходимо) с помощью различных способов (ручной, в программе Key Collector, анализ конкурентов и т.д.). Описанные варианты парсинга, для которых я написал подробные пошаговые руководства, можно найти по ссылкам в блоке дополнительных статей после этого поста.
- Полученные поисковые запросы необходимо проанализировать и оставить самые качественные из них. , который позволит отсеять слова-пустышки, сможет отделить конкурентные слова от неконкурентых и показать самые эффективные ключевики.
- Распределить полученные ключевые слова по документам веб-ресурса. Финишный этап в создании семантического ядра, в котором необходимо для каждой продвигаемой страницы в зависимости от условий продвижения закрепить свои ключевики. Благодаря такому распределению веб-мастер может сразу видеть главный запрос и дополнительные, но и предположить структуру будущего контента. Здесь же идет деление ядра на основное и второстепенное (если в этом есть необходимость).
После того, как полное семантическое ядро сайта создано, в плане продвижения пора браться за внутреннюю оптимизацию страниц и затем делать эффективную перелинковку.
Пример готового семантического ядра (таблица ключевиков)
Для того, чтобы Вы могли увидеть готовый результат, я решил выложить кусочек заказанного у меня семантического ядра. На этом скриншоте Вы увидите таблицу подобранных ключевиков (картинка кликабельна) :

Как видите, все ключевые слова распределены по статьям (распределение осуществляет заказчик самостоятельно или я за отдельную плату). Сразу видно, какие поисковые запросы из таблицы могут идти как главный запрос, а какие в виде дополнительных ключевиков. Все это позволяет заказчику не мешкая внедрять полученные ключевые слова сразу в готовые посты или делать примерный план будущих постов — все четко и понятно видно.
Где можно заказать отличное семантическое ядро?
Если Вы желаете собрать полноценное семантическое ядро для коммерческого сайта или информационного проекта, рекомендую обратиться .
Плюсы и минусы семантического ядра
Как и в любом деле, создание семантического ядра имеет свои положительные и отрицательные стороны. Сначала поговорим о минусах:
- Для получения качественного семантического ядра сайта нужны различные варианты затрат. Если Вы заказали свой список ключевых слов у специалиста, то такими затратами будут приличная сумма. Чем больше слов заказываете, тем больше рублей отдаете. Если же Вы подбираете ключевики самостоятельно, то можете потратить достаточно много времени, пока научитесь подбирать самые эффективные запросы. Но полученный опыт и качество ключей вернут потраченные часы за сбором ядра в виде отличной конверсии и целевого поискового трафика.
- Для отбора и анализа лучших ключевых слов из уже спарсенных необходимы знания. Не каждый веб-мастер будет копаться в этом деле — ведь кроме знаний оптимизации нужно владеть азами работы в Excel и уметь считать (для форматирования данных, в первую очередь). Но, опять же, если все это будет, качество Вашего семантического ядра будет в разы выше, чем простой набор спарсенных ключей из Вордстата.
Как видите, минусов немного, но они существенные. И если материальные средства не так важны, то изучение нужного материала требует времени, которое цениться больше всего. Ведь его нельзя вернуть… Перейдем к плюсам:
- Самый большой и важный плюс — Вы получаете крепкий фундамент для продвижения своего веб-ресурса. Без ключевых слов видимость сайта или блога будет очень низкой, что не даст привлечь на него большой поисковый трафик. А значит не будут реализованы поставленные задачи и цели. Не достаточно для привлечения пользователей поисковых систем писать просто качественный контент. Поисковикам необходимо еще наличие ключевых слов в статье (в тексте) и на странице (в ее мета-данных). Поэтому создание семантического ядра — первый этап, без которого поисковое продвижение просто нереально!
- Благодаря хорошему семантическому ядру (конечно, с учетом его грамотной внутренней оптимизации), продвигаемые страницы веб-ресурса будут не только получать именно целевых пользователей из поиска, но и позволять сайту иметь отличные поведенческие факторы. При использовании плохих ключевиков (или их отсутствия) показатель отказов заметно вырастает, число целевых конверсий уменьшается.
- Имея под рукой готовое семантическое ядро, любой веб-мастер будет иметь представление будущего своего веб-ресурса с точки зрения создания контента. Глядя на ключевые слова, он увидит будущие темы своих статей на сайте. То есть он может планировать свою деятельность намного эффективней — заранее дать копирайтеру задание, лучше подготовиться к сезонным скачкам или придумать очередной цикл постов.
- Как правило, на блоге создается (находится) большое число постов. Поэтому ключевых слов для них надо искать много. Но не стоит брать первые попавшиеся — поищите лучшие варианты, оцените их, проанализируйте параметры поисковых запросов. Возможно Вы затратите больше времени, но зато получите на выходе качественные ключи, которые смогут привлечь лучший трафик, чем сборище первых увиденных поисковых запросов. Сделайте себе установку — каждый день поиск ключевиков для одной статьи. Набив руку, Вы намного быстрее будете собирать их для своего ядра, тем самым за один раз обслужив 3-5 постов.
- Не надо читать кучу seo материалов, не кидайтесь на супер-пупер новинки в оптимизации и не ищите идеального способа создания семантики для своего блога — его не существует! Возьмите тот, который Вам понятен. И подбирайте с помощью него ключевые слова. Но доверяйте только проверенным материалам о СЯ.
- Часто бывает, когда нам сложно придумать тему для нашего будущего поста. Особенно, с точки зрения поискового продвижения, когда во главу угла становиться получение максимального поискового трафика. Готовое семантическое ядро помогает избавиться от этой проблемы раз и навсегда — перед Вашими глазами в любой момент времени (!) сможете наблюдать готовые темы следующих статей. И не только — таким образом можно прикинуть будущий цикл постов, который может потом превратиться и в свой инфопродукт. 🙂

И напоследок самый важный совет. Не гонитесь за большими и толстыми ключевиками. Не будет от этого толку, только проблем себе насобираете, потратив море времени впустую. Берите в оборот мой следующий трехфазный принцип подбора ключевиков, который я успешно использую на своем блоге (более 80% ключевых слов находятся в топ-30, около 49% в топ-10 в Яндексе и более 20-ти% в Google — и это в моей сложной конкурентной тематике!):
- Полученные спарсенные слова, которые Вы собрали своим способом (например, с помощью Вордстата, программы Словоеб, анализа конкурентов и т.д.) проверьте на конкурентность — оцените их стоимость продвижения (как это сделать, можно узнать из моей бесплатной книги или можете прочитать в отдельной дополнительной статье — ссылка после этого поста). Уберите все конкурентные запросы, оставьте только с минимальной стоимостью (например, в SeoPult это ключевики стоимостью в 100 рублей, в SeoPult Pro — 25).
- Для оставшихся поисковых запросов оцените их качество. Для этого необходимо посчитать соотношение точной и базовой частотностей (есть как в книге, так и в посте про анализ поисковых запросов). Исключите в зависимости от тематики некачественные слова, исключите слова-пустышки.
- Теперь уже среди полученных качественных слов сделайте их распределение по статьям. Если пост имеет более одного ключа, выберите самый жирный из них (но этот ключевик должен иметь большую точную частотность, чем другие). Он будет являться главным запросом, приносящим большую часть поискового трафика по продвигаемой статье. Если из предложенных для статьи ключевых слов на главенство подходят два ключа (больше двух — редкость), берите оба. Один пропишите в title, другой в h1. уникальной многофункциональной платформы Key Kollector ;
- Для блоггера лучшим помощником для создания своего семантического ядра конечно будет . Он быстро работает и абсолютно бесплатен! Рекомендую!