Dans le développement des processeurs modernes, il existe une tendance à une augmentation progressive du nombre de cœurs, ce qui augmente leurs capacités en calcul parallèle. Cependant, il existe depuis longtemps des GPU nettement supérieurs aux CPU à cet égard. Et ces capacités des GPU ont déjà été prises en compte par certaines entreprises. Les premières tentatives d'utilisation d'accélérateurs graphiques pour l'informatique non ciblée ont été réalisées depuis la fin des années 90. Mais seule l'émergence des shaders est devenue l'impulsion pour le développement d'une technologie complètement nouvelle, et en 2003 le concept de GPGPU (General-Purpose Graphics Processing Units) est apparu. Un rôle important dans le développement de cette initiative a été joué par BrookGPU, qui est une extension spéciale pour le langage C. Avant l'avènement de BrookGPU, les programmeurs ne pouvaient travailler avec les GPU que via l'API Direct3D ou OpenGL. Brook a permis aux développeurs de travailler avec un environnement familier et le compilateur lui-même, à l'aide de bibliothèques spéciales, a implémenté une interaction avec le GPU à un niveau bas.
De tels progrès ne pouvaient qu'attirer l'attention des leaders de cette industrie - AMD et NVIDIA, qui ont commencé à développer leurs propres plates-formes logicielles pour l'informatique non graphique sur leurs cartes vidéo. Personne ne connaît mieux que les développeurs de GPU toutes les nuances et fonctionnalités de leurs produits, ce qui permet à ces mêmes entreprises d'optimiser le plus efficacement possible le progiciel pour des solutions matérielles spécifiques. Actuellement, NVIDIA développe la plate-forme CUDA (Compute Unified Device Architecture), AMD appelle une technologie similaire CTM (Close To Metal) ou AMD Stream Computing. Nous examinerons certaines des capacités de CUDA et évaluerons en pratique les capacités informatiques de la puce graphique G92 de la carte vidéo GeForce 8800 GT.
Mais d’abord, examinons certaines des nuances liées à l’exécution de calculs à l’aide de GPU. Leur principal avantage est que la puce graphique est initialement conçue pour exécuter plusieurs threads, alors que chaque cœur d'un CPU classique exécute un flux d'instructions séquentielles. Tout GPU moderne est un multiprocesseur composé de plusieurs clusters de calcul, avec de nombreuses ALU dans chacun. La puce GT200 moderne la plus puissante se compose de 10 clusters de ce type, chacun disposant de 24 processeurs de flux. La carte vidéo GeForce 8800 GT testée, basée sur la puce G92, dispose de sept grandes unités de calcul dotées chacune de 16 processeurs de flux. Les processeurs utilisent des blocs SIMD SSE pour les calculs vectoriels (données multiples à instruction unique - une instruction est exécutée sur plusieurs données), ce qui nécessite de transformer les données en 4 vecteurs. Le GPU traite les threads de manière scalaire, c'est-à-dire une instruction est appliquée sur plusieurs threads (SIMT - instruction unique sur plusieurs threads). Cela évite aux développeurs de convertir les données en vecteurs et permet un branchement arbitraire dans les flux. Chaque unité de calcul GPU dispose d'un accès direct à la mémoire. Et la bande passante de la mémoire vidéo est plus élevée, grâce à l'utilisation de plusieurs contrôleurs de mémoire séparés (sur le G200 haut de gamme, il y a 8 canaux 64 bits) et des fréquences de fonctionnement élevées.
En général, dans certaines tâches lorsque l’on travaille avec de grandes quantités de données, les GPU sont beaucoup plus rapides que les CPU. Ci-dessous vous voyez une illustration de cette déclaration :
Le graphique montre la dynamique de croissance des performances du CPU et du GPU depuis 2003. NVIDIA aime citer ces données à titre publicitaire dans ses documents, mais ce ne sont que des calculs théoriques et en réalité l'écart, bien sûr, peut s'avérer beaucoup plus petit.
Quoi qu’il en soit, il existe un énorme potentiel de GPU pouvant être utilisés et qui nécessite une approche spécifique du développement logiciel. Tout cela est implémenté dans l'environnement matériel et logiciel CUDA, qui se compose de plusieurs niveaux logiciels - l'API d'exécution CUDA de haut niveau et l'API de pilote CUDA de bas niveau.

CUDA utilise le langage C standard pour la programmation, ce qui constitue l'un de ses principaux avantages pour les développeurs. Initialement, CUDA inclut les bibliothèques BLAS (package d'algèbre linéaire de base) et FFT (transformation de Fourier). CUDA a également la capacité d'interagir avec les API graphiques OpenGL ou DirectX, la capacité de développer à bas niveau et se caractérise par une répartition optimisée des flux de données entre le CPU et le GPU. Les calculs CUDA sont effectués simultanément avec les calculs graphiques, contrairement à la plate-forme AMD similaire, où une machine virtuelle spéciale est lancée pour les calculs sur le GPU. Mais une telle « cohabitation » est également semée d'erreurs si une charge importante est créée par l'API graphique alors que CUDA s'exécute simultanément - après tout, les opérations graphiques ont toujours une priorité plus élevée. La plateforme est compatible avec les systèmes d'exploitation 32 et 64 bits Windows XP, Windows Vista, MacOS X et diverses versions de Linux. La plate-forme est ouverte et sur le site Web, en plus des pilotes spéciaux pour la carte vidéo, vous pouvez télécharger des progiciels CUDA Toolkit, CUDA Developer SDK, comprenant un compilateur, un débogueur, des bibliothèques standard et de la documentation.
Quant à la mise en œuvre pratique de CUDA, cette technologie a longtemps été utilisée uniquement pour des calculs mathématiques hautement spécialisés dans le domaine de la physique des particules, de l'astrophysique, de la médecine ou pour prévoir l'évolution du marché financier, etc. Mais cette technologie se rapproche progressivement des utilisateurs ordinaires, notamment des plug-ins spéciaux pour Photoshop apparaissent, capables d'utiliser la puissance de calcul du GPU. Sur une page spéciale, vous pouvez étudier la liste complète des programmes qui utilisent les capacités de NVIDIA CUDA.
Comme test pratique de la nouvelle technologie sur la carte vidéo MSI NX8800GT-T2D256E-OC, nous utiliserons le programme TMPGEnc. Ce produit est commercial (la version complète coûte 100 $), mais pour les cartes vidéo MSI, il est proposé en bonus dans une version d'essai d'une durée de 30 jours. Vous pouvez télécharger cette version sur le site Web du développeur, mais pour installer TMPGEnc 4.0 XPress MSI Special Edition, vous avez besoin du disque d'origine avec les pilotes de la carte MSI - sans cela, le programme ne sera pas installé.
Pour afficher les informations les plus complètes sur les capacités informatiques de CUDA et les comparer avec d'autres adaptateurs vidéo, vous pouvez utiliser l'utilitaire spécial CUDA-Z. Voici les informations qu'il donne sur notre carte vidéo GeForce 8800GT :
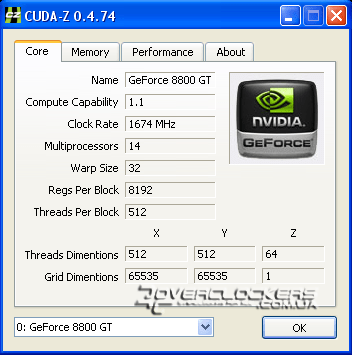


Par rapport aux modèles de référence, notre copie fonctionne à des fréquences plus élevées : le domaine raster est 63 MHz plus élevé que le nominal, les unités shader sont plus rapides de 174 MHz et la mémoire est 100 MHz plus rapide.
Nous comparerons la vitesse de conversion de la même vidéo HD lors d'un calcul utilisant uniquement le CPU et avec une activation supplémentaire de CUDA dans le programme TMPGEnc sur la configuration suivante :
- Processeur : Pentium Dual-Core E5200 2,5 GHz ;
- Carte mère : Gigaoctet P35-S3 ;
- Mémoire : 2x1 Go GoodRam PC6400 (5-5-5-18-2T)
- Carte vidéo : MSI NX8800GT-T2D256E-OC ;
- Disque dur : 320 Go WD3200AAKS ;
- Alimentation : CoolerMaster eXtreme Power 500-PCAP ;
- Système d'exploitation : Windows XP SP2 ;
- TMPGEnc 4.0 XPress 4.6.3.268 ;
- Pilotes de carte vidéo : ForceWare 180.60.

L'encodage a été réalisé à l'aide du codec DivX 6.8.4. Dans les paramètres de qualité de ce codec, toutes les valeurs sont laissées par défaut, le multithreading est activé.

La prise en charge du multithreading dans TMPGEnc est initialement activée dans l'onglet Paramètres CPU/GPU. CUDA est également activé dans la même section.
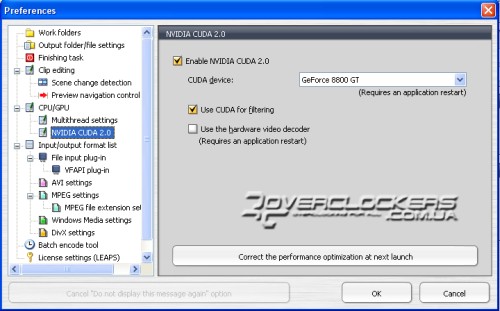
Comme vous pouvez le voir sur la capture d'écran ci-dessus, le traitement du filtre à l'aide de CUDA est activé, mais le décodeur vidéo matériel n'est pas activé. La documentation du programme prévient que l'activation du dernier paramètre augmente le temps de traitement du fichier.
Sur la base des résultats des tests, les données suivantes ont été obtenues :

À 4 GHz avec CUDA activé, nous n'avons gagné que quelques secondes (soit 2 %), ce qui n'est pas particulièrement impressionnant. Mais à une fréquence plus faible, l'augmentation due à l'activation de cette technologie permet de gagner environ 13 % de temps, ce qui sera tout à fait perceptible lors du traitement de fichiers volumineux. Mais les résultats ne sont pas aussi impressionnants que prévu.
Le programme TMPGEnc dispose d'un indicateur de charge CPU et CUDA ; dans cette configuration de test, il a montré la charge CPU à environ 20 % et le cœur graphique aux 80 % restants. En conséquence, nous avons les mêmes 100 % que lors de la conversion sans CUDA, et il se peut qu'il n'y ait pas de décalage horaire du tout (mais il existe toujours). La petite capacité de mémoire de 256 Mo n'est pas non plus un facteur limitant. À en juger par les lectures de RivaTuner, pas plus de 154 Mo de mémoire vidéo ont été utilisés pendant le fonctionnement.

conclusions
Le programme TMPGEnc fait partie de ceux qui présentent la technologie CUDA au grand public. L'utilisation du GPU dans ce programme vous permet d'accélérer le processus de traitement vidéo et de soulager considérablement le processeur central, ce qui permettra à l'utilisateur d'effectuer confortablement d'autres tâches en même temps. Dans notre exemple spécifique, la carte vidéo GeForce 8800GT 256 Mo a légèrement amélioré les performances de synchronisation lors de la conversion vidéo basée sur un processeur Pentium Dual-Core E5200 overclocké. Mais il est clairement visible qu'à mesure que la fréquence diminue, le gain de l'activation de CUDA augmente ; sur les processeurs faibles, le gain de son utilisation sera bien plus important. Dans le contexte de cette dépendance, il est tout à fait logique de supposer que même avec une augmentation de la charge (par exemple, l'utilisation d'un très grand nombre de filtres vidéo supplémentaires), les résultats d'un système avec CUDA se distingueront par un plus delta significatif de la différence dans le temps passé sur le processus d'encodage. N'oubliez pas non plus que le G92 n'est pas la puce la plus puissante pour le moment et que les cartes vidéo plus modernes offriront des performances nettement supérieures dans de telles applications. Cependant, pendant que l'application est en cours d'exécution, le GPU n'est pas complètement chargé et, probablement, la répartition de la charge dépend de chaque configuration séparément, à savoir de la combinaison processeur/carte vidéo, ce qui peut finalement donner une augmentation plus grande (ou plus petite) en pourcentage. de l'activation de CUDA. Dans tous les cas, pour ceux qui travaillent avec de gros volumes de données vidéo, cette technologie leur permettra quand même de gagner beaucoup de temps.
Certes, CUDA n'a pas encore gagné en popularité : la qualité des logiciels fonctionnant avec cette technologie doit être améliorée. Dans le programme TMPGEnc 4.0 XPress que nous avons examiné, cette technologie ne fonctionnait pas toujours. La même vidéo pouvait être réencodée plusieurs fois, et puis du coup, au prochain lancement, la charge CUDA était déjà à 0%. Et ce phénomène était totalement aléatoire sur des systèmes d’exploitation complètement différents. De plus, le programme en question a refusé d'utiliser CUDA lors de l'encodage au format XviD, mais il n'y a eu aucun problème avec le codec DivX populaire.
En conséquence, jusqu'à présent, la technologie CUDA ne peut augmenter considérablement les performances des ordinateurs personnels que dans certaines tâches. Mais le champ d'application d'une telle technologie va s'élargir et le processus d'augmentation du nombre de cœurs dans les processeurs conventionnels indique une augmentation de la demande de calcul multithread parallèle dans les applications logicielles modernes. Ce n’est pas pour rien que récemment, tous les leaders de l’industrie sont devenus obsédés par l’idée de combiner CPU et GPU au sein d’une architecture unifiée (rappelez-vous simplement l’AMD Fusion tant annoncé). Peut-être que CUDA est l’une des étapes du processus de cette unification.
Nous remercions les entreprises suivantes pour avoir fourni du matériel de test :
La nouvelle technologie est comme une nouvelle espèce évolutive émergente. Une créature étrange, contrairement à de nombreux anciens. Parfois gênant, parfois drôle. Et de prime abord, ses nouvelles qualités ne semblent aucunement adaptées à ce monde posé et stable.
Cependant, un peu de temps passe et il s'avère que le débutant court plus vite, saute plus haut et est généralement plus fort. Et il mange plus de mouches que ses voisins rétrogrades. Et puis ces mêmes voisins commencent à comprendre qu'il ne sert à rien de se disputer avec cet ancien maladroit. Il vaut mieux être ami avec lui, et encore mieux organiser une symbiose. Vous verrez qu'il y aura plus de mouches.
La technologie GPGPU (General-Purpose Graphics Processing Units - processeur graphique à usage général) n'a longtemps existé que dans les calculs théoriques d'universitaires intelligents. Sinon comment? Proposer de changer radicalement le processus informatique développé au fil des décennies en confiant le calcul de ses branches parallèles à une carte vidéo, seuls les théoriciens en sont capables.
Le logo de la technologie CUDA nous rappelle qu'elle a grandi dans les profondeurs de
Graphiques 3D.
Mais la technologie GPGPU n’allait pas rester longtemps dans les pages des revues universitaires. Après avoir gonflé ses meilleures qualités, elle a attiré l'attention des fabricants. C'est ainsi qu'est né CUDA - une implémentation de GPGPU sur les processeurs graphiques GeForce fabriqués par nVidia.
Grâce à CUDA, les technologies GPGPU sont devenues courantes. Et maintenant, seuls les développeurs de systèmes de programmation les plus myopes et couverts d'une épaisse couche de paresse ne déclarent pas de support pour CUDA avec leur produit. Les publications informatiques ont considéré comme un honneur de présenter les détails de la technologie dans de nombreux articles scientifiques de vulgarisation, et les concurrents se sont immédiatement mis à la recherche de modèles et de compilateurs croisés pour développer quelque chose de similaire.
La reconnaissance publique est un rêve non seulement pour les starlettes en herbe, mais aussi pour les technologies nouvellement nées. Et CUDA a eu de la chance. Elle est bien connue, on parle et on écrit sur elle.
Ils écrivent simplement comme s’ils continuaient à discuter du GPGPU dans de grosses revues scientifiques. Ils bombardent le lecteur avec un tas de termes comme « grille », « SIMD », « distorsion », « hôte », « texture et mémoire constante ». Ils le plongent tout en haut dans les organigrammes des GPU nVidia, le conduisent sur des chemins sinueux d'algorithmes parallèles et (le geste le plus fort) affichent de longues listes de codes en langage C. En conséquence, il s'avère qu'à l'entrée de l'article nous avons un nouveau lecteur avec un désir ardent de comprendre CUDA, et à la sortie nous avons le même lecteur, mais avec une tête gonflée remplie d'un fouillis de faits, de diagrammes , code, algorithmes et termes.
Pendant ce temps, le but de toute technologie est de nous faciliter la vie. Et CUDA fait un excellent travail avec ça. Les résultats de son travail convaincront tout sceptique mieux que des centaines de schémas et d’algorithmes.
Pas partout
CUDA est pris en charge par des supercalculateurs hautes performances
nVidia Tesla.
Et pourtant, avant d’examiner les résultats des travaux de CUDA visant à faciliter la vie de l’utilisateur moyen, il convient d’en comprendre toutes les limites. Comme avec un génie : n'importe quel désir, mais un. CUDA a aussi son talon d'Achille. L’un d’eux concerne les limitations des plates-formes sur lesquelles il peut fonctionner.
La liste des cartes vidéo nVidia prenant en charge CUDA est présentée dans une liste spéciale appelée Produits compatibles CUDA. La liste est assez impressionnante, mais facile à classer. Le support de CUDA n'est pas refusé :
Modèles nVidia GeForce des séries 8e, 9e, 100e, 200e et 400e avec un minimum de 256 Mo de mémoire vidéo intégrée. La prise en charge s'étend aux cartes de bureau et mobiles.
La grande majorité des cartes vidéo de bureau et mobiles sont des nVidia Quadro.
Toutes les solutions de la série de netbooks nvidia ION.
Solutions de supercalculateurs HPC (High Performance Computing) hautes performances et nVidia Tesla utilisées à la fois pour l'informatique personnelle et pour l'organisation de systèmes de cluster évolutifs.
Par conséquent, avant d'utiliser des produits logiciels basés sur CUDA, il convient de consulter cette liste de favoris.
En plus de la carte vidéo elle-même, un pilote approprié est requis pour prendre en charge CUDA. C'est le lien entre les processeurs centraux et graphiques, agissant comme une sorte d'interface logicielle pour accéder au code du programme et aux données du trésor multicœur du GPU. Pour vous assurer de ne pas commettre d'erreur, nVidia vous recommande de visiter la page des pilotes et d'obtenir la dernière version.
... mais le processus lui-même
Comment fonctionne CUDA ? Comment expliquer le processus complexe de calcul parallèle sur une architecture matérielle GPU particulière sans plonger le lecteur dans l'abîme des termes spécifiques ?
Vous pouvez essayer de le faire en imaginant comment le processeur central exécute le programme en symbiose avec le processeur graphique.
Sur le plan architectural, l'unité centrale de traitement (CPU) et son homologue graphique (GPU) sont conçus différemment. Si l'on fait une analogie avec le monde de l'industrie automobile, alors le CPU est un break, un de ceux qu'on appelle une « grange ». Cela ressemble à une voiture de tourisme, mais en même temps (du point de vue des développeurs) « c’est un Suisse, un faucheur et un joueur de pipe ». Remplit à la fois le rôle d’un petit camion, d’un bus et d’une berline hypertrophiée. Break, en somme. Il comporte peu de cœurs de cylindre, mais ils gèrent presque toutes les tâches et l'impressionnante mémoire cache est capable de stocker un tas de données.
Mais le GPU est une voiture de sport. Il n’y a qu’une seule fonction : amener le pilote à la ligne d’arrivée le plus rapidement possible. Par conséquent, pas de grande mémoire de coffre, pas de sièges supplémentaires. Mais il y a des centaines de fois plus de cœurs de cylindre que de processeur.
Grâce à CUDA, les développeurs de programmes GPGPU n'ont pas besoin de se plonger dans les complexités de la programmation
développement de moteurs graphiques tels que DirectX et OpenGL
Contrairement au processeur central, qui est capable de résoudre n'importe quelle tâche, y compris graphique, mais avec des performances moyennes, le processeur graphique est adapté à une solution à grande vitesse d'une tâche : transformer un tas de polygones à l'entrée en un tas de pixels à le résultat. De plus, ce problème peut être résolu en parallèle en utilisant des centaines de cœurs de calcul relativement simples dans le GPU.
Alors, quel genre de tandem peut-il y avoir entre un break et une voiture de sport ? CUDA fonctionne à peu près comme ceci : le programme s'exécute sur le CPU jusqu'à ce qu'il y ait une section de code qui peut être exécutée en parallèle. Ensuite, au lieu d’être exécuté lentement sur deux (voire huit) cœurs du processeur le plus cool, il est transféré sur des centaines de cœurs GPU. Dans le même temps, le temps d'exécution de cette section est considérablement réduit, ce qui signifie que le temps d'exécution de l'ensemble du programme est également réduit.
Technologiquement, rien ne change pour le programmeur. Le code des programmes CUDA est écrit en langage C. Plus précisément, dans son dialecte spécial « C with streams » (C with streams). Développée à Stanford, cette extension du langage C s'appelle Brook. L'interface qui transfère le code Brook au GPU est le pilote d'une carte vidéo prenant en charge CUDA. Il organise l'ensemble du processus de traitement de cette section du programme afin que, pour le programmeur, le GPU ressemble à un coprocesseur CPU. Très similaire à l’utilisation d’un coprocesseur mathématique aux débuts de l’informatique personnelle. Avec l'avènement de Brook, des cartes vidéo prenant en charge CUDA et de leurs pilotes, tout programmeur est désormais en mesure d'accéder au GPU dans ses programmes. Mais avant, ce chamanisme appartenait à un cercle restreint de personnes sélectionnées qui passaient des années à perfectionner les techniques de programmation pour les moteurs graphiques DirectX ou OpenGL.
Dans le tonneau de ce miel prétentieux - les louanges de CUDA - il vaut la peine de mettre un frein à la pommade, c'est-à-dire des restrictions. Tous les problèmes qui doivent être programmés ne peuvent pas être résolus à l'aide de CUDA. Il ne sera pas possible d'accélérer la résolution des tâches de bureau courantes, mais vous pouvez faire confiance à CUDA pour calculer le comportement de milliers de combattants du même type dans World of Warcraft. Mais c’est une tâche inventée. Regardons des exemples de ce que CUDA résout déjà de manière très efficace.
Œuvres justes
CUDA est une technologie très pragmatique. Après avoir implémenté son support dans ses cartes vidéo, nVidia s'attendait à juste titre à ce que la bannière CUDA soit reprise par de nombreux passionnés tant dans le milieu universitaire que dans le commerce. Et c’est ce qui s’est passé. Les projets basés sur CUDA vivent et apportent des avantages.
NVIDIA PhysX
Lorsqu'ils font la publicité de leur prochain chef-d'œuvre de jeu, les fabricants mettent souvent l'accent sur son réalisme 3D. Mais aussi réel que soit le monde du jeu 3D, si les lois élémentaires de la physique, telles que la gravité, la friction et l'hydrodynamique, ne sont pas mises en œuvre correctement, le mensonge se fera instantanément sentir.
L'une des capacités du moteur physique NVIDIA PhysX est le travail réaliste avec les tissus.
La mise en œuvre d’algorithmes pour la simulation informatique des lois physiques fondamentales est une tâche très exigeante en main-d’œuvre. Les entreprises les plus connues dans ce domaine sont la société irlandaise Havok avec son physique multiplateforme Havok Physics et le californien Ageia - l'ancêtre du premier processeur physique au monde (PPU - Physics Processing Unit) et du moteur physique PhysX correspondant. Le premier d'entre eux, bien qu'acquis par Intel, travaille désormais activement dans le domaine de l'optimisation du moteur Havok pour les cartes vidéo ATI et les processeurs AMD. Mais Ageia, avec son moteur PhysX, est devenu partie intégrante de nVidia. Dans le même temps, nVidia a résolu le problème assez difficile de l'adaptation de PhysX à la technologie CUDA.
Cela est devenu possible grâce aux statistiques. Il a été statistiquement prouvé que, quelle que soit la complexité du rendu d'un GPU, certains de ses cœurs restent inactifs. C'est sur ces cœurs que tourne le moteur PhysX.
Grâce à CUDA, la part du lion des calculs liés à la physique du monde du jeu a commencé à être effectuée sur la carte vidéo. La puissance libérée du processeur central a été utilisée pour résoudre d'autres problèmes de gameplay. Le résultat ne s’est pas fait attendre. Selon les experts, le gain de performances dans le gameplay avec PhysX fonctionnant sur CUDA a augmenté d'au moins un ordre de grandeur. La probabilité de réaliser les lois physiques a également augmenté. CUDA s'occupe du calcul de routine de la mise en œuvre du frottement, de la gravité et d'autres éléments qui nous sont familiers pour les objets multidimensionnels. Désormais, non seulement les héros et leur équipement s'intègrent parfaitement aux lois du monde physique que nous connaissons, mais aussi la poussière, le brouillard, l'onde de souffle, les flammes et l'eau.
Version CUDA du package de compression de texture NVIDIA Texture Tools 2
Aimez-vous les objets réalistes dans les jeux modernes ? Cela vaut la peine de remercier les développeurs de textures. Mais plus la texture est réelle, plus son volume est important. Plus cela occupe une mémoire précieuse. Pour éviter cela, les textures sont pré-compressées et décompressées dynamiquement selon les besoins. Et la compression et la décompression sont de purs calculs. Pour travailler avec des textures, nVidia a publié le package NVIDIA Texture Tools. Il prend en charge la compression et la décompression efficaces des textures DirectX (le format dit HF). La deuxième version de ce package prend en charge les algorithmes de compression BC4 et BC5 implémentés dans la technologie DirectX 11. Mais l'essentiel est que NVIDIA Texture Tools 2 inclut la prise en charge de CUDA. Selon nVidia, cela permet de multiplier par 12 les performances dans les tâches de compression et de décompression de texture. Cela signifie que les images de jeu se chargeront plus rapidement et raviront le joueur par leur réalisme.
Le package NVIDIA Texture Tools 2 est conçu pour fonctionner avec CUDA. Le gain de performances lors de la compression et de la décompression des textures est évident.
L'utilisation de CUDA peut améliorer considérablement l'efficacité de la vidéosurveillance.
Traitement du flux vidéo en temps réel
Quoi qu’on en dise, le monde actuel, du point de vue de l’espionnage, est bien plus proche du monde du Big Brother d’Orwell qu’il n’y paraît. Les automobilistes et les visiteurs des lieux publics ressentent le regard des caméras vidéo.
Des fleuves d'informations vidéo se déversent dans les centres de leur traitement et... se jettent dans un lien étroit - une personne. Dans la plupart des cas, il est la dernière autorité à surveiller le monde de la vidéo. De plus, l’autorité n’est pas la plus efficace. Cligne des yeux, se laisse distraire et essaie de s'endormir.
Grâce à CUDA, il est devenu possible de mettre en œuvre des algorithmes de suivi simultané de plusieurs objets dans un flux vidéo. Dans ce cas, le processus se déroule en temps réel et la vidéo atteint une vitesse de 30 ips. Par rapport à la mise en œuvre d'un tel algorithme sur les processeurs multicœurs modernes, CUDA offre des performances deux ou trois fois supérieures, et cela, voyez-vous, c'est beaucoup.
Conversion vidéo, filtrage audio
Le convertisseur vidéo Badaboom est le premier à utiliser CUDA pour accélérer la conversion.
C'est agréable de regarder un nouveau produit de location vidéo en qualité FullHD et sur grand écran. Mais vous ne pouvez pas emporter un grand écran avec vous sur la route, et le codec vidéo FullHD aura le hoquet sur le processeur basse consommation d'un gadget mobile. La conversion vient à la rescousse. Mais la plupart de ceux qui l'ont rencontré dans la pratique se plaignent du long temps de conversion. Cela est compréhensible, le processus est routinier, adapté à la parallélisation, et son exécution sur le CPU n'est pas très optimale.
Mais CUDA y fait face avec brio. Le premier signe est le convertisseur Badaboom d'Elevental. Les développeurs de Badaboom ont pris la bonne décision en choisissant CUDA. Les tests montrent qu'il convertit un film standard d'une heure et demie au format iPhone/iPod Touch en moins de vingt minutes. Et ceci malgré le fait qu'en utilisant uniquement le CPU, ce processus prend plus d'une heure.
Aide CUDA et les mélomanes professionnels. N'importe lequel d'entre eux donnerait un demi-royaume pour un crossover FIR efficace - un ensemble de filtres qui divisent le spectre sonore en plusieurs bandes. Ce processus demande beaucoup de travail et, avec un volume important de matériel audio, oblige l'ingénieur du son à « fumer » pendant plusieurs heures. La mise en œuvre d'un crossover FIR basé sur CUDA accélère son fonctionnement des centaines de fois.
L'avenir de CUDA
Ayant fait de la technologie GPGPU une réalité, CUDA ne se repose pas sur ses lauriers. Comme cela arrive partout, le principe de réflexion fonctionne dans CUDA : désormais non seulement l'architecture des processeurs vidéo nVidia influence le développement des versions du SDK CUDA, mais la technologie CUDA elle-même oblige nVidia à reconsidérer l'architecture de ses puces. Un exemple d’une telle réflexion est la plateforme nVidia ION. Sa deuxième version est spécialement optimisée pour résoudre les problèmes CUDA. Cela signifie que même avec des solutions matérielles relativement peu coûteuses, les consommateurs bénéficieront de toute la puissance et des capacités brillantes de CUDA.
– un ensemble d'interfaces logicielles de bas niveau ( API) pour créer des jeux et autres applications multimédia hautes performances. Inclut un support haute performance 2D- Et 3D-périphériques graphiques, sonores et d'entrée.
Direct3D (D3D) – interface d’affichage en trois dimensions primitives(corps géométriques). Inclus dans .
OpenGL(de l'anglais Bibliothèque graphique ouverte, littéralement - bibliothèque graphique ouverte) est une spécification qui définit une interface de programmation multiplateforme indépendante du langage de programmation pour l'écriture d'applications utilisant des infographies bidimensionnelles et tridimensionnelles. Comprend plus de 250 fonctions pour dessiner des scènes 3D complexes à partir de simples primitives. Utilisé pour créer des jeux vidéo, de la réalité virtuelle et de la visualisation dans la recherche scientifique. Sur la plateforme les fenêtres rivalise avec .
OpenCL(de l'anglais Langage informatique ouvert, littéralement – un langage ouvert de calculs) – cadre(cadre de système logiciel) pour écrire des programmes informatiques liés au calcul parallèle sur divers graphiques ( GPU) Et ( ). Vers le cadre OpenCL comprend un langage de programmation et une interface de programmation d'application ( API). OpenCL fournit un parallélisme au niveau des instructions et au niveau des données et constitue une implémentation de la technique GPGPU.
GPGPU(abrégé de l'anglais) Unités de traitement graphique à usage général, littéralement - GPU usage général) est une technique d'utilisation d'une unité de traitement graphique (GPU) ou d'une carte vidéo pour l'informatique générale qui est généralement effectuée par un ordinateur.
Ombreur(Anglais) shader) – un programme pour construire des ombres sur des images synthétisées, utilisé dans les graphiques tridimensionnels pour déterminer les paramètres finaux d'un objet ou d'une image. Comprend généralement des descriptions arbitrairement complexes de l'absorption et de la diffusion de la lumière, du mappage de texture, de la réflexion et de la réfraction, de l'ombrage, du déplacement de surface et des effets de post-traitement. Les surfaces complexes peuvent être visualisées à l'aide de formes géométriques simples.
Le rendu(Anglais) le rendu) – visualisation, en infographie, du processus d'obtention d'une image à partir d'un modèle à l'aide d'un logiciel.
SDK(abrégé de l'anglais) Kit de développement logiciel) – un ensemble d’outils de développement logiciel.
CPU(abrégé de l'anglais) Unité centrale de traitement, littéralement – dispositif informatique central/principal/principal) – central (micro) ; un dispositif qui exécute les instructions de la machine ; un élément matériel chargé d'effectuer des opérations de calcul (spécifiées par le système d'exploitation et le logiciel d'application) et de coordonner le fonctionnement de tous les appareils.
GPU(abrégé de l'anglais) Unité de traitement graphique, littéralement – dispositif informatique graphique) – processeur graphique ; un appareil ou une console de jeu distinct qui effectue un rendu graphique (visualisation). Les GPU modernes sont très efficaces pour traiter et afficher les infographies de manière réaliste. Le processeur graphique des adaptateurs vidéo modernes est utilisé comme accélérateur graphique 3D, mais dans certains cas, il peut également être utilisé pour des calculs ( GPGPU).
Problèmes CPU
Pendant longtemps, l'augmentation des performances des modèles traditionnels s'est principalement produite en raison d'une augmentation constante de la fréquence d'horloge (environ 80 % des performances étaient déterminées par la fréquence d'horloge) avec une augmentation simultanée du nombre de transistors sur une puce. . Cependant, une nouvelle augmentation de la fréquence d'horloge (à une fréquence d'horloge supérieure à 3,8 GHz, les puces surchauffent tout simplement !) se heurte à un certain nombre de barrières physiques fondamentales (puisque le processus technologique s'approche presque de la taille d'un atome : , et la taille d'un atome de silicium est d'environ 0,543 nm) :
Premièrement, à mesure que la taille des cristaux diminue et que la fréquence d’horloge augmente, le courant de fuite des transistors augmente. Cela entraîne une augmentation de la consommation d'énergie et des émissions de chaleur ;
Deuxièmement, les avantages des vitesses d'horloge plus élevées sont partiellement annulés par la latence d'accès à la mémoire, car les temps d'accès à la mémoire ne suivent pas l'augmentation des vitesses d'horloge ;
Troisièmement, pour certaines applications, les architectures série traditionnelles deviennent inefficaces à mesure que les vitesses d'horloge augmentent en raison de ce que l'on appelle le « goulot d'étranglement de von Neumann », une limitation des performances résultant du flux de calcul séquentiel. Dans le même temps, les délais de transmission des signaux résistifs-capacitifs augmentent, ce qui constitue un goulot d'étranglement supplémentaire associé à une augmentation de la fréquence d'horloge.
Développement GPU
En parallèle, il y a eu (et il y a encore !) un développement GPU:
…
novembre 2008 – Intel introduit une gamme de 4 cœurs Intel Core i7, qui reposent sur une microarchitecture de nouvelle génération Néhalem. Les processeurs fonctionnent à une fréquence d'horloge de 2,6 à 3,2 GHz. Fabriqué à l'aide d'une technologie de processus de 45 nm.
Décembre 2008 – début des livraisons de 4 cœurs AMD Phenom II 940(nom de code - Déneb). Fonctionne à une fréquence de 3 GHz, produit à l'aide d'une technologie de traitement de 45 nm.
…
Mai 2009 – entreprise DMLA introduit la version GPU ATI Radeon HD 4890 avec la vitesse d'horloge du cœur augmentée de 850 MHz à 1 GHz. C'est le premier graphique processeur fonctionnant à 1 GHz. La puissance de calcul de la puce, grâce à l'augmentation de la fréquence, est passée de 1,36 à 1,6 téraflops. Le processeur contient 800 (!) cœurs de calcul et prend en charge la mémoire vidéo GDDR5, DirectX 10.1, ATI CrossFireX et toutes les autres technologies inhérentes aux modèles de cartes vidéo modernes. La puce est fabriquée sur la base de la technologie 55 nm.
Principales différences GPU
Caractéristiques distinctives GPU(comparé à ) sont:
– une architecture visant au maximum à augmenter la vitesse de calcul des textures et des objets graphiques complexes ;
– puissance de crête typique GPU bien plus haut que ça ;
– grâce à une architecture de convoyeur spécialisée, GPU beaucoup plus efficace dans le traitement des informations graphiques que .
"Crise du genre"
"Crise de genre" pour mûri en 2005 - c'est à ce moment-là qu'ils sont apparus. Mais, malgré le développement de la technologie, l'augmentation de la productivité des industries conventionnelles diminué sensiblement. En même temps des performances GPU continuer à grandir. Ainsi, en 2003, cette idée révolutionnaire s'est cristallisée - utilisez la puissance de calcul des graphiques pour vos besoins. Les GPU sont de plus en plus utilisés pour l'informatique « non graphique » (simulation physique, traitement du signal, mathématiques/géométrie computationnelles, opérations de bases de données, biologie computationnelle, économie computationnelle, vision par ordinateur, etc.).
Le principal problème était qu’il n’existait pas d’interface de programmation standard. GPU. Les développeurs ont utilisé OpenGL ou Direct3D, mais c'était très pratique. société Nvidia(l'un des plus grands fabricants de processeurs graphiques, multimédias et de communication, ainsi que de processeurs multimédias sans fil ; fondé en 1993) a commencé à développer une norme unifiée et pratique - et a introduit la technologie CUDA.
Comment ça a commencé
2006 – Nvidia démontre CUDA™; le début d’une révolution informatique GPU.
2007 – Nvidia architecture des versions CUDA(version originale SDK CUDA a été soumis le 15 février 2007); nomination « Meilleur nouveau produit » du magazine Science populaire et "Choix des lecteurs" de la publication Fil HPC.
2008 – technologie NVIDIACUDA a remporté la catégorie « Excellence Technique » du Magazine PC.
Ce qui s'est passé CUDA
CUDA(abrégé de l'anglais) Calculer une architecture de périphérique unifiée, littéralement - architecture informatique unifiée des appareils) - architecture (un ensemble de logiciels et de matériel) qui vous permet de produire sur GPU calculs à usage général, tandis que GPU agit en fait comme un puissant coprocesseur.
Technologie NVIDIA CUDA™ est le seul environnement de développement dans un langage de programmation C, qui permet aux développeurs de créer des logiciels qui résolvent des problèmes informatiques complexes en moins de temps, grâce à la puissance de traitement des GPU. Des millions de personnes travaillent déjà dans le monde GPU avec le soutien CUDA, et des milliers de programmeurs utilisent déjà des outils (gratuits !) CUDA pour accélérer les applications et résoudre les tâches les plus complexes et les plus gourmandes en ressources - de l'encodage vidéo et audio à l'exploration pétrolière et gazière, en passant par la modélisation de produits, l'imagerie médicale et la recherche scientifique.
CUDA donne au développeur la possibilité, à sa discrétion, d'organiser l'accès à l'ensemble des instructions de l'accélérateur graphique et de gérer sa mémoire, et d'y organiser des calculs parallèles complexes. Prise en charge de l'accélérateur graphique CUDA devient une puissante architecture ouverte programmable, similaire à celle d'aujourd'hui. Tout cela fournit au développeur un accès de bas niveau, distribué et haut débit au matériel, ce qui rend CUDA une base nécessaire pour créer des outils sérieux de haut niveau, tels que des compilateurs, des débogueurs, des bibliothèques mathématiques et des plates-formes logicielles.
Uralsky, spécialiste leader en technologie Nvidia, comparant GPU Et , dit ceci : « - C'est un SUV. Il conduit toujours et partout, mais pas très vite. UN GPU- C'est une voiture de sport. Sur une mauvaise route, il n'ira nulle part, mais donnez-lui une bonne surface et il montrera toute sa vitesse, dont un SUV n'a même jamais rêvé !.. »
Capacités technologiques CUDA
Et il est conçu pour traduire le code hôte (code principal, code de contrôle) et le code de l'appareil (code matériel) (fichiers avec l'extension .cu) en fichiers objets adaptés au processus d'assemblage du programme final ou de la bibliothèque dans n'importe quel environnement de programmation, par exemple dans NetBeans.
L'architecture CUDA utilise un modèle de mémoire en grille, une modélisation de threads de cluster et des instructions SIMD. Applicable non seulement au calcul graphique haute performance, mais également à divers calculs scientifiques utilisant des cartes vidéo nVidia. Les scientifiques et les chercheurs utilisent largement CUDA dans divers domaines, notamment l'astrophysique, la biologie et la chimie computationnelles, la modélisation de la dynamique des fluides, les interactions électromagnétiques, la tomodensitométrie, l'analyse sismique, etc. CUDA a la capacité de se connecter à des applications utilisant OpenGL et Direct3D. CUDA est un logiciel multiplateforme pour les systèmes d'exploitation tels que Linux, Mac OS X et Windows.
Le 22 mars 2010, nVidia a publié CUDA Toolkit 3.0, qui contenait la prise en charge d'OpenCL.
Équipement
La plate-forme CUDA est apparue pour la première fois sur le marché avec la sortie de la puce NVIDIA G80 de huitième génération et est devenue présente dans toutes les séries ultérieures de puces graphiques, utilisées dans les familles d'accélérateurs GeForce, Quadro et NVidia Tesla.
La première série de matériel prenant en charge le SDK CUDA, le G8x, disposait d'un processeur vectoriel simple précision 32 bits utilisant le SDK CUDA comme API (CUDA prend en charge le type double C, mais sa précision a maintenant été réduite à 32 bits. point flottant). Les processeurs GT200 ultérieurs prennent en charge une précision de 64 bits (SFU uniquement), mais les performances sont nettement moins bonnes que pour une précision de 32 bits (en raison du fait qu'il n'y a que deux SFU par multiprocesseur de flux, alors qu'il existe huit processeurs scalaires). Le GPU organise le multithreading matériel, ce qui permet d'utiliser toutes les ressources du GPU. Ainsi, la perspective s'ouvre de transférer les fonctions de l'accélérateur physique vers l'accélérateur graphique (un exemple de mise en œuvre est nVidia PhysX). Cela ouvre également de larges possibilités d'utilisation du matériel d'infographie pour effectuer des calculs non graphiques complexes : par exemple, en biologie computationnelle et dans d'autres branches scientifiques.
Avantages
Par rapport à l'approche traditionnelle d'organisation de l'informatique générale via des API graphiques, l'architecture CUDA présente les avantages suivants dans ce domaine :
Restrictions
- Toutes les fonctions exécutables sur l'appareil ne prennent pas en charge la récursivité (CUDA Toolkit 3.1 prend en charge les pointeurs et la récursion) et présentent d'autres limitations.
GPU et accélérateurs graphiques pris en charge
La liste des appareils du fabricant d'équipements Nvidia avec une prise en charge totale déclarée de la technologie CUDA est fournie sur le site officiel de Nvidia : CUDA-Enabled GPU Products (anglais).
En fait, les périphériques suivants prennent actuellement en charge la technologie CUDA sur le marché du matériel PC :
| Version de spécification | GPU | Cartes vidéo |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX/Ultra, 9400GT, 9600GT, 9800GT, Tesla C/D/S870, FX4/5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS/GT, 8600GT/GTS, 8800GT/GTS, 9600 GSO, 9800GTX/GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18/3700, 4700x2, 1xxM, 32 /370M, 3/5/770M, 16/17/27/28/36/37/3800M, NVS420/50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C/M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S/M2050/70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF110) GTX 560 TI 448, GTX570, GTX580, GTX590 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 670MX, GTX 660M, GeForce GT 650M, GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Les modèles Tesla C1060, Tesla S1070, Tesla C2050/C2070, Tesla M2050/M2070, Tesla S2050 permettent des calculs GPU avec une double précision.
Caractéristiques et spécifications de différentes versions
| Prise en charge des fonctionnalités (les fonctionnalités non répertoriées sont pris en charge pour toutes les capacités de calcul) |
Capacité de calcul (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
Mots de 32 bits dans la mémoire globale |
Non | Oui | |||
valeurs à virgule flottante dans la mémoire globale |
|||||
| Fonctions atomiques entières opérant sur Mots de 32 bits en mémoire partagée |
Non | Oui | |||
| atomicExch() fonctionnant sur 32 bits valeurs à virgule flottante dans la mémoire partagée |
|||||
| Fonctions atomiques entières opérant sur Mots de 64 bits dans la mémoire globale |
|||||
| Fonctions de vote Warp | |||||
| Opérations à virgule flottante double précision | Non | Oui | |||
| Fonctions atomiques fonctionnant sur 64 bits valeurs entières en mémoire partagée |
Non | Oui | |||
| Addition atomique à virgule flottante opérant sur Mots de 32 bits en mémoire globale et partagée |
|||||
| _bulletin de vote() | |||||
| _threadfence_system() | |||||
| _syncthreads_count(), _syncthreads_and(), _syncthreads_or() |
|||||
| Fonctions surfaciques | |||||
| Grille 3D du bloc de fil | |||||
| Spécifications techniques | Capacité de calcul (version) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Dimensionnalité maximale de la grille des blocs de filetage | 2 | 3 | |||
| Dimension x, y ou z maximale d'une grille de blocs de filetage | 65535 | ||||
| Dimensionnalité maximale du bloc de filetage | 3 | ||||
| Dimension x ou y maximale d'un bloc | 512 | 1024 | |||
| Dimension z maximale d'un bloc | 64 | ||||
| Nombre maximum de threads par bloc | 512 | 1024 | |||
| Taille de chaîne | 32 | ||||
| Nombre maximum de blocs résidents par multiprocesseur | 8 | ||||
| Nombre maximum de warps résidents par multiprocesseur | 24 | 32 | 48 | ||
| Nombre maximum de threads résidents par multiprocesseur | 768 | 1024 | 1536 | ||
| Nombre de registres 32 bits par multiprocesseur | 8K | 16K | 32K | ||
| Quantité maximale de mémoire partagée par multiprocesseur | 16 Ko | 48 Ko | |||
| Nombre de banques de mémoire partagées | 16 | 32 | |||
| Quantité de mémoire locale par thread | 16 Ko | 512 Ko | |||
| Taille de mémoire constante | 64 Ko | ||||
| Ensemble de travail du cache par multiprocesseur pour une mémoire constante | 8 Ko | ||||
| Ensemble de travail du cache par multiprocesseur pour la mémoire de texture | En fonction de l'appareil, entre 6 Ko et 8 Ko | ||||
| Largeur maximale pour la texture 1D |
8192 | 32768 | |||
| Largeur maximale pour la texture 1D référence liée à la mémoire linéaire |
2 27 | ||||
| Largeur maximale et nombre de couches pour une référence de texture en couches 1D |
8192 x 512 | 16384 x 2048 | |||
| Largeur et hauteur maximales pour la 2D référence de texture liée à mémoire linéaire ou tableau CUDA |
65536 x 32768 | 65536 x 65535 | |||
| Largeur, hauteur et nombre maximum de calques pour une référence de texture en couches 2D |
8 192 x 8 192 x 512 | 16384 x 16384 x 2048 | |||
| Largeur, hauteur et profondeur maximales pour une référence de texture 3D liée au linéaire mémoire ou un tableau CUDA |
2048 x 2048 x 2048 | ||||
| Nombre maximum de textures peut être lié à un noyau |
128 | ||||
| Largeur maximale pour une surface 1D référence liée à un tableau CUDA |
Pas prise en charge |
8192 | |||
| Largeur et hauteur maximales pour une 2D référence de surface liée à un tableau CUDA |
8192 x 8192 | ||||
| Nombre maximum de surfaces qui peut être lié à un noyau |
8 | ||||
| Nombre maximum d'instructions par noyau |
2 millions | ||||
Exemple
CudaArray* cu_array; texture< float , 2 >Texas; // Allouer le tableau cudaMalloc( & cu_array, cudaCreateChannelDesc< float>(), largeur hauteur) ; // Copie les données de l'image dans le tableau cudaMemcpy( cu_array, image, width* height, cudaMemcpyHostToDevice) ; // Lie le tableau à la texture cudaBindTexture( tex, cu_array) ; // Exécute le noyau dim3 blockDim(16, 16, 1) ; dim3 gridDim(largeur / blockDim.x, hauteur / blockDim.y, 1) ; noyau<<< gridDim, blockDim, 0 >>> (d_odata, largeur, hauteur) ; cudaUnbindTexture(tex) ; __global__ void kernel(float * odata, int height, int width) ( unsigned int x = blockIdx.x * blockDim.x + threadIdx.x ; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y ; float c = texfetch(tex, x, y) ; odata[ y* largeur+ x] = c; )
Importer pycuda.driver en tant que drv importer numpy drv.init() dev = drv.Device(0) ctx = dev.make_context() mod = drv.SourceModule( """ __global__ void multiplie_them(float *dest, float *a, float *b) ( const int i = threadIdx.x; dest[i] = a[i] * b[i]; ) """) multiplier_them = mod.get_function ("multiply_them" ) a = numpy.random .randn (400 ) .astype (numpy.float32 ) b = numpy.random .randn (400 ) .astype (numpy.float32 ) dest = numpy.zeros_like (a) multiplier_them( drv.Out (dest) , drv.In (a) , drv.In (b) , block= (400 , 1 , 1 ) ) imprimer dest-a*b
CUDA comme matière dans les universités
Depuis décembre 2009, le modèle logiciel CUDA est enseigné dans 269 universités à travers le monde. En Russie, des cours de formation sur CUDA sont dispensés à l'Université polytechnique de Saint-Pétersbourg, Université d'État de Yaroslavl. P. G. Demidov, Moscou, Nijni Novgorod, Saint-Pétersbourg, Tver, Kazan, Novossibirsk, Université technique d'État de Novossibirsk, Universités d'État d'Omsk et de Perm, Université internationale sur la nature de la société et de l'homme "Dubna", Université d'État de l'énergie d'Ivanovo, Université d'État de Belgorod , MSTU eux. Bauman, Université technique chimique russe du nom. Mendeleïev, Centre interrégional de supercalculateurs RAS, . En outre, en décembre 2009, il a été annoncé que le premier centre scientifique et éducatif russe « Parallel Computing », situé dans la ville de Dubna, avait commencé à fonctionner, dont les tâches comprennent la formation et les consultations sur la résolution de problèmes informatiques complexes sur les GPU.
En Ukraine, des cours sur CUDA sont dispensés à l'Institut d'analyse des systèmes de Kiev.
Liens
Ressources officielles
- Zone CUDA (russe) - site officiel de CUDA
- CUDA GPU Computing (anglais) - forums Web officiels dédiés à l'informatique CUDA
Ressources non officielles
Le matériel de Tom- Dmitri Tchekanov. nVidia CUDA : informatique sur carte vidéo ou mort du CPU ? . Tom's Hardware (22 juin 2008). Archivé
- Dmitri Tchekanov. nVidia CUDA : analyse comparative des applications GPU pour le marché de masse. Tom's Hardware (19 mai 2009). Archivé de l'original le 4 mars 2012. Récupéré le 19 mai 2009.
- Alexeï Berillo. NVIDIA CUDA - calcul non graphique sur GPU. Partie 1 . iXBT.com (23 septembre 2008). Archivé de l'original le 4 mars 2012. Récupéré le 20 janvier 2009.
- Alexeï Berillo. NVIDIA CUDA - calcul non graphique sur GPU. Partie 2 . iXBT.com (22 octobre 2008). - Exemples d'implémentation de NVIDIA CUDA. Archivé de l'original le 4 mars 2012. Récupéré le 20 janvier 2009.
- Boreskov Alexeï Viktorovitch. Bases de CUDA (20 janvier 2009). Archivé de l'original le 4 mars 2012. Récupéré le 20 janvier 2009.
- Vladimir Frolov. Introduction à la technologie CUDA. Magazine en ligne « Infographie et Multimédia » (19 décembre 2008). Archivé de l'original le 4 mars 2012. Récupéré le 28 octobre 2009.
- Igor Oskolkov. NVIDIA CUDA est un billet abordable pour le monde du big computing. Computerra (30 avril 2009). Récupéré le 3 mai 2009.
- Vladimir Frolov. Introduction à la technologie CUDA (1er août 2009). Archivé de l'original le 4 mars 2012. Récupéré le 3 avril 2010.
- GPGPU.ru. Utiliser des cartes vidéo pour l'informatique
- . Centre de calcul parallèle
Remarques
voir également
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Graphique processeurs |
| |||||||
Noyaux CUDA - symbole unités de calcul scalaires en puces vidéo NVIDIA, commençant par G80 (GeForce 8 xxx, Tesla CD-S870, FX4/5600 , 360M). Les puces elles-mêmes sont des dérivés de l'architecture. D'ailleurs, parce que l'entreprise NVIDIA si volontiers entrepris le développement de ses propres processeurs Série Tégra, également basé sur RISQUE architecture. J'ai beaucoup d'expérience avec ces architectures.
CUDA le noyau en contient un un vecteur Et un scalaire unités qui effectuent une opération vectorielle et une opération scalaire par cycle d'horloge, transférant les calculs vers un autre multiprocesseur ou vers un autre pour un traitement ultérieur. Un ensemble de centaines et de milliers de ces cœurs représente une puissance de calcul importante et peut effectuer diverses tâches en fonction des besoins, à condition qu'il existe certains logiciels de support. Application peuvent être variés : décodage de flux vidéo, accélération graphique 2D/3D, cloud computing, analyses mathématiques spécialisées, etc.
Très souvent, combinés Cartes professionnelles NVidia Tesla Et NVidia Quadro, constituent l’épine dorsale des supercalculateurs modernes.
CUDA— les amandes n'ont pas subi de modifications significatives depuis G80, mais leur nombre augmente (avec d'autres blocs - ROP, Unités de texture& etc) et l'efficacité des interactions parallèles entre elles (les modules sont améliorés Giga-fil).

Par exemple:
GeForce
GTX 460 – 336 cœurs CUDA
GTX 580 – 512 cœurs CUDA
8800GTX – 128 cœurs CUDA
Du nombre de processeurs de flux ( CUDA), les performances dans les calculs de shaders augmentent presque proportionnellement (avec une augmentation uniforme du nombre d'autres éléments).
À partir de la puce GK110(NVidiaGeForce GTX 680) - CUDA les cœurs n'ont plus une double fréquence, mais une fréquence commune à tous les autres blocs de puces. Au lieu de cela, leur nombre a augmenté d'environ trois fois par rapport à la génération précédente G110.