Ce matériel discutera de ces objets de base de données Microsoft SQL Server Comment indices Vous apprendrez ce que sont les index, quels types d'index existent, comment les créer, les optimiser et les supprimer.
Que sont les index dans une base de données ?
Indice est un objet de base de données qui est une structure de données composée de clés construites à partir d'une ou plusieurs colonnes d'une table ou d'une vue, et de pointeurs qui correspondent à l'endroit où les données spécifiées sont stockées. Les index sont conçus pour récupérer plus rapidement les lignes d'une table ; en d'autres termes, ils permettent une recherche rapide des données dans une table, ce qui améliore considérablement les performances des requêtes et des applications. Les index peuvent également être utilisés pour garantir que les lignes d'une table sont uniques, garantissant ainsi l'intégrité des données.
Types d'index dans Microsoft SQL Server
Les types d'index suivants existent dans Microsoft SQL Server :
- En cluster (En cluster) est un index qui stocke les données de la table triées par valeur de clé d'index. Une table ne peut avoir qu'un seul index clusterisé car les données ne peuvent être triées que dans un seul ordre. Si possible, chaque table doit avoir un index clusterisé ; si une table n'a pas d'index clusterisé, la table est appelée " en tas" Un index clusterisé est créé automatiquement lorsque vous créez des contraintes PRIMARY KEY ( clé primaire) et UNIQUE si un index clusterisé sur la table n'a pas encore été défini. Si vous créez un index clusterisé sur une table ( des tas) qui contient des index non clusterisés, ils doivent tous être reconstruits après leur création.
- Non clusterisé (Non clusterisé) est un index qui contient la valeur d'une clé et un pointeur vers une ligne de données contenant la valeur de cette clé. Une table peut avoir plusieurs index non clusterisés. Des index non clusterisés peuvent être créés sur des tables avec ou sans index clusterisé. C'est ce type d'index qui est utilisé pour améliorer les performances des requêtes fréquemment utilisées, car les index non clusterisés permettent une recherche et un accès rapides aux données par valeurs clés ;
- Filtrable (Filtré) est un index non cluster optimisé qui utilise un prédicat de filtre pour indexer un sous-ensemble de lignes dans une table. S'il est bien conçu, ce type d'index peut améliorer les performances des requêtes et également réduire les coûts de maintenance et de stockage de l'index par rapport aux index de table complète ;
- Unique (Unique) est un index qui garantit qu'il n'y a pas de doublons ( identique) valeurs de la clé d'index, garantissant ainsi l'unicité des lignes pour cette clé. Les index clusterisés et non clusterisés peuvent être uniques. Si vous créez un index unique sur plusieurs colonnes, l'index garantit que chaque combinaison de valeurs dans la clé est unique. Lorsque vous créez des contraintes PRIMARY KEY ou UNIQUE, le serveur SQL crée automatiquement un index unique sur les colonnes clés. Un index unique ne peut être créé que si la table n'a actuellement aucune valeur en double dans les colonnes clés ;
- De colonne (Magasin de colonnes) est un index basé sur la technologie de stockage de données en colonnes. Ce type d'index est efficace pour les grands entrepôts de données, car il peut augmenter les performances des requêtes vers l'entrepôt jusqu'à 10 fois et également réduire la taille des données jusqu'à 10 fois, puisque les données de l'index Columnstore sont compressées. Il existe à la fois des index de colonnes clusterisés et des index non clusterisés ;
- Texte intégral (Texte intégral) est un type spécial d'index qui fournit une prise en charge efficace des recherches de mots complexes sur les données de chaînes de caractères. Le processus de création et de maintenance d'un index de texte intégral est appelé " remplissage" Il existe des types de remplissage tels que : le remplissage complet et le remplissage basé sur le suivi des modifications. Par défaut, SQL Server remplit entièrement un nouvel index de texte intégral immédiatement après sa création, mais cela peut nécessiter une quantité importante de ressources, en fonction de la taille de la table. Il est donc possible de retarder le remplissage complet. L'amorçage basé sur le suivi des modifications est utilisé pour conserver l'index de texte intégral une fois qu'il est initialement entièrement amorcé ;
- Spatial (Spatial) est un index qui vous permet d'utiliser plus efficacement des opérations spécifiques sur des objets spatiaux dans des colonnes de type de données géométrie ou géographie. Ce type d'index ne peut être créé que sur une colonne spatiale, et la table sur laquelle l'index spatial est défini doit contenir une clé primaire ( CLÉ PRIMAIRE);
- XML est un autre type spécial d'index conçu pour les colonnes avec un type de données XML. L'index XML améliore l'efficacité du traitement des requêtes sur les colonnes XML. Il existe deux types d'index XML : primaire et secondaire. Un index XML principal indexe toutes les balises, valeurs et chemins stockés dans une colonne XML. Il ne peut être créé que si la table possède un index clusterisé sur la clé primaire. Un index XML secondaire ne peut être créé que si la table possède un index XML primaire et qu'il est utilisé pour améliorer les performances des requêtes sur un certain type d'accès à la colonne XML, à cet égard, il existe plusieurs types d'index secondaires : PATH , VALEUR et PROPRIÉTÉ ;
- Il existe également des index spéciaux pour les tables optimisées en mémoire ( OLTP en mémoire) tels que : Hash ( Hacher) des index optimisés en mémoire et des index non clusterisés créés pour les analyses de plage et les analyses ordonnées.
Création et suppression d'index dans Microsoft SQL Server
Avant de commencer à créer un index, il est nécessaire de bien le concevoir afin de l'utiliser efficacement, car des index mal conçus peuvent ne pas améliorer les performances, mais plutôt les réduire. Par exemple, la présence d'un grand nombre d'index sur une table réduit les performances des instructions INSERT, UPDATE, DELETE et MERGE, car lorsque les données de la table changent, tous les index doivent être mis à jour en conséquence. Nous examinerons les recommandations générales pour la conception d'index dans un article séparé, mais passons maintenant directement à l'examen du processus de création et de suppression d'index.
Note! Mon serveur SQL est Microsoft SQL Server 2016 Express.
Création d'index
Il existe deux manières de créer des index dans Microsoft SQL Server : la première consiste à utiliser l'interface graphique de l'environnement SQL Server Management Studio (SSMS), et la seconde utilise le langage Transact-SQL, nous analyserons les deux méthodes.
Données sources pour exemples
Imaginons que nous ayons une table de produits appelée TestTable, qui comporte trois colonnes :
- ProductId – identifiant du produit ;
- ProductName – nom du produit ;
- CategoryID – catégorie de produit.
Exemple de création d'un index clusterisé
Comme je l'ai déjà dit, un index clusterisé est créé automatiquement si, par exemple, lors de la création d'une table, on spécifie une colonne spécifique comme clé primaire ( CLÉ PRIMAIRE), mais puisque nous ne l'avons pas fait, regardons un exemple de création vous-même d'un index clusterisé.
Pour créer un index clusterisé, nous pouvons spécifier une clé primaire pour la table, et ainsi l'index clusterisé sera créé automatiquement, ou nous pouvons créer un index clusterisé séparément.
Par exemple, créons simplement un index clusterisé, sans créer de clé primaire. Nous allons d’abord faire cela en utilisant Management Studio.
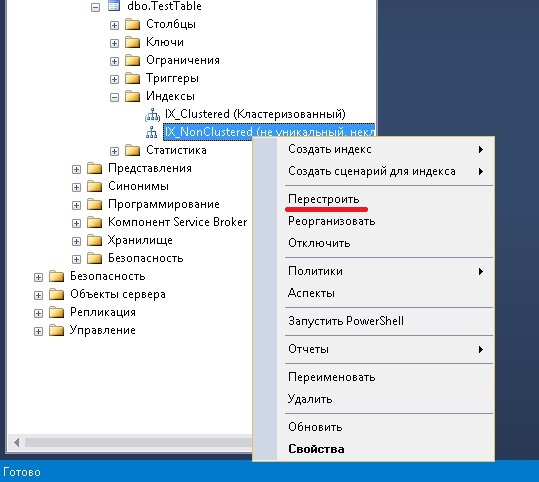
Ouvrez SSMS et recherchez la table souhaitée dans le navigateur d'objets et faites un clic droit sur l'élément " Index", sélectionner " Créer un index" et type d'index, dans notre cas " En cluster».

La forme " Nouvel indice", où nous devons préciser le nom du nouvel index ( il doit être unique dans la table), on indique également si cet index sera unique ; si l'on parle de l'identifiant du produit dans la table des produits, alors, bien sûr, il doit être unique. Sélectionnez ensuite la colonne ( clé d'index), sur la base duquel nous créerons un index clusterisé, c'est-à-dire les lignes de données du tableau seront triées en utilisant le " Ajouter».

Après avoir renseigné tous les paramètres nécessaires, cliquez sur « D'ACCORD", éventuellement un index clusterisé sera créé.

De même, on pourrait créer un index clusterisé à l'aide d'une instruction T-SQL INDICE DE CRÉATURE, par exemple, comme ça
CRÉER UN INDEX CLUSTERÉ UNIQUE IX_Clustered ON TestTable (ProductId ASC) ALLER
Ou, comme nous l'avons déjà dit, nous pourrions également utiliser une instruction pour créer une clé primaire, par exemple
ALTER TABLE TestTable AJOUTER UNE CONTRAINTE PK_TestTable CLÉ PRIMAIRE CLUSTERED (ProductId ASC) GO
Exemple de création d'un index non clusterisé avec des colonnes incluses
Regardons maintenant un exemple de création d'un index non clusterisé, dans lequel nous indiquerons les colonnes qui ne seront pas clés, mais seront incluses dans l'index. Ceci est utile dans les cas où vous créez un index pour une requête spécifique, par exemple, afin que l'index couvre complètement la requête, c'est-à-dire contenait toutes les colonnes ( c'est ce qu'on appelle « Demander une couverture »). La couverture des requêtes améliore les performances car l'optimiseur de requêtes peut trouver toutes les valeurs de colonne dans l'index sans accéder aux données de la table, ce qui réduit le nombre d'opérations d'E/S disque. Mais rappelez-vous que l'inclusion de colonnes non clés dans l'index entraîne une augmentation de la taille de l'index, c'est-à-dire le stockage de l'index nécessitera plus d'espace disque et peut également entraîner une réduction des performances des opérations INSERT, UPDATE, DELETE et MERGE sur la table de base.
Afin de créer un index non clusterisé à l'aide de l'interface graphique de Management Studio, nous trouvons également la table souhaitée et l'élément Index, seulement dans ce cas nous sélectionnons « Créer -> Index non clusterisé».

Après avoir ouvert le formulaire " Nouvel indice"on précise le nom de l'index, on ajoute une ou plusieurs colonnes clés à l'aide du bouton " Ajouter", par exemple, pour notre scénario de test, spécifions le CategoryID.


Dans Transact-SQL, cela ressemblerait à ceci.
CRÉER UN INDEX NON CLUSTERED IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Exemple de suppression d'un index dans Microsoft SQL Server
Afin de supprimer un index, vous pouvez faire un clic droit sur l'index souhaité et cliquer sur " Supprimer", puis confirmez vos actions en cliquant sur " D'ACCORD».

ou vous pouvez également utiliser les instructions INDICE DE BAISSE, Par exemple
DROP INDEX IX_NonClustered ON TestTable
Il convient de noter que l'instruction DROP INDEX ne s'applique pas aux index créés en créant des contraintes PRIMARY KEY et UNIQUE. Dans ce cas, pour supprimer l'index, vous devez utiliser l'instruction ALTER TABLE avec la clause DROP CONSTRAINT.
Optimisation des index dans Microsoft SQL Server
À la suite de la mise à jour, de l'ajout ou de la suppression de données dans les tables SQL, le serveur apporte automatiquement les modifications correspondantes aux index, mais au fil du temps, toutes ces modifications peuvent provoquer une fragmentation des données dans l'index, c'est-à-dire ils finiront par être dispersés dans la base de données. La fragmentation des index entraîne une diminution des performances des requêtes, il est donc périodiquement nécessaire d'effectuer des opérations de maintenance des index, à savoir la défragmentation, telles que des opérations de réorganisation et de reconstruction des index.
Quand utiliser la réorganisation d’index et quand reconstruire ?
Pour répondre à cette question, vous devez d'abord déterminer le degré de fragmentation de l'index, car en fonction de la fragmentation de l'index, l'une ou l'autre méthode de défragmentation sera préférable et plus efficace. Vous pouvez utiliser la fonction de table système pour déterminer le degré de fragmentation de l'index sys.dm_db_index_physical_stats, qui renvoie des informations détaillées sur la taille et la fragmentation des index. Par exemple, à l'aide de la requête suivante, vous pouvez connaître le degré de fragmentation de l'index pour toutes les tables de la base de données actuelle.
SELECT OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS Fragmentation FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS T1 LEFT JOIN sys. index AS T2 ON T1.object_id = T2.object_id ET T1.index_id = T2.index_id
Dans ce cas, nous nous intéressons à la colonne avg_fragmentation_in_percent, c'est à dire. pourcentage de fragmentation logique.
- Si le degré de fragmentation est inférieur à 5 %, la réorganisation ou la reconstruction de l'index ne doit pas du tout être lancée ;
- Si le degré de fragmentation est de 5 à 30 %, il est alors logique de lancer une réorganisation de l'index, car cette opération utilise un minimum de ressources système et ne nécessite pas de verrous à long terme ;
- Si le degré de fragmentation est supérieur à 30 %, alors il est nécessaire de reconstruire l'index, car cette opération, avec une fragmentation importante, donne un effet plus important que l'opération de réorganisation de l'index.
Personnellement, je peux ajouter ce qui suit si vous avez une petite entreprise et que la base de données ne nécessite pas une sortie maximale 24 heures sur 24, c'est-à-dire Puisqu'il ne s'agit pas d'une base de données super active, vous pouvez effectuer périodiquement en toute sécurité l'opération de reconstruction des index, sans même déterminer le degré de fragmentation.
Réorganisation des index
Réorganisation de l'index est un processus de défragmentation d'index qui défragmente les index clusterisés et non clusterisés au niveau feuille sur les tables et les vues en réorganisant physiquement les pages au niveau feuille selon l'ordre logique ( de gauche à droite) nœuds finaux.
Vous pouvez utiliser l'outil graphique SSMS ou l'instruction Transact-SQL pour réorganiser l'index.
Réorganiser un index à l'aide de Management Studio

Réorganisation d'un index à l'aide de Transact-SQL
ALTER INDEX IX_NonClustered ON TestTable RÉORGANISER ALLER
Reconstruction des index
Reconstruire l'index est un processus qui supprime l'ancien index et en crée un nouveau, éliminant ainsi la fragmentation.
Vous pouvez utiliser deux méthodes pour reconstruire les index.
D'abord. Utilisation de l'instruction ALTER INDEX avec la clause REBUILD. Cette instruction remplace l'instruction DBCC DBREINDEX. Il s’agit généralement de la méthode utilisée pour reconstruire les index en masse.
Exemple
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
Et la seconde, en utilisant l'instruction CREATE INDEX avec la clause DROP_EXISTING. Peut être utilisé, par exemple, pour reconstruire un index en changeant sa définition, c'est-à-dire ajouter ou supprimer des colonnes clés.
Exemple
CRÉER UN INDEX NON CLUSTERED IX_NonClustered ON TestTable (CategoryID ASC) AVEC (DROP_EXISTING = ON) GO
La fonctionnalité de reconstruction est également disponible dans Management Studio. Faites un clic droit sur l'index souhaité " Reconstruire».
Ceci conclut le matériel sur les bases des index dans Microsoft SQL Server. Si vous êtes intéressé par le langage T-SQL, je vous recommande de lire mon livre « The T-SQL Programmer's Way », bonne chance !
L'un des moyens les plus importants pour atteindre une productivité élevée serveur SQL est l’utilisation d’index. Un index accélère le processus de requête en fournissant un accès rapide aux lignes de données d'une table, tout comme un index dans un livre vous aide à trouver rapidement les informations dont vous avez besoin. Dans cet article, je vais donner un bref aperçu des index dans serveur SQL et expliquez comment ils sont organisés dans la base de données et comment ils contribuent à accélérer les requêtes dans la base de données.Les index sont créés sur les colonnes de table et de vue. Les index fournissent un moyen de rechercher rapidement des données en fonction des valeurs de ces colonnes. Par exemple, si vous créez un index sur une clé primaire, puis recherchez une ligne de données à l'aide des valeurs de clé primaire, alors serveur SQL trouvera d'abord la valeur de l'index, puis utilisera l'index pour trouver rapidement la ligne entière de données. Sans index, une analyse complète de toutes les lignes de la table sera effectuée, ce qui peut avoir un impact significatif sur les performances.
Vous pouvez créer un index sur la plupart des colonnes d'une table ou d'une vue. L'exception concerne principalement les colonnes avec des types de données pour stocker des objets volumineux ( LOB), tel que image, texte ou varchar(max). Vous pouvez également créer des index sur des colonnes conçues pour stocker des données au format XML, mais ces index sont structurés légèrement différemment des index standard et leur prise en compte dépasse le cadre de cet article. De plus, l'article ne parle pas magasin de colonnes index. Au lieu de cela, je me concentre sur les index les plus couramment utilisés dans les bases de données. serveur SQL.
Un index est constitué d'un ensemble de pages, de nœuds d'index, qui sont organisés dans une structure arborescente - arbre équilibré. Cette structure est de nature hiérarchique et commence par un nœud racine en haut de la hiérarchie et des nœuds feuilles, les feuilles, en bas, comme le montre la figure : 
Lorsque vous interrogez une colonne indexée, le moteur de requête démarre en haut du nœud racine et descend jusqu'aux nœuds intermédiaires, chaque couche intermédiaire contenant des informations plus détaillées sur les données. Le moteur de requête continue de parcourir les nœuds d'index jusqu'à ce qu'il atteigne le niveau inférieur avec les feuilles d'index. Par exemple, si vous recherchez la valeur 123 dans une colonne indexée, le moteur de requête déterminera d'abord la page au premier niveau intermédiaire au niveau racine. Dans ce cas, la première page pointe vers une valeur de 1 à 100, et la seconde de 101 à 200, le moteur de requête accédera donc à la deuxième page de ce niveau intermédiaire. Ensuite, vous verrez que vous devez vous tourner vers la troisième page du niveau intermédiaire suivant. À partir de là, le sous-système de requête lira la valeur de l'index lui-même à un niveau inférieur. Les feuilles d'index peuvent contenir soit les données de la table elles-mêmes, soit simplement un pointeur vers les lignes contenant des données dans la table, selon le type d'index : index clusterisé ou index non clusterisé.
Index clusterisé
Un index clusterisé stocke les lignes de données réelles dans les feuilles de l'index. En revenant à l'exemple précédent, cela signifie que la ligne de données associée à la valeur clé de 123 sera stockée dans l'index lui-même. Une caractéristique importante d'un index clusterisé est que toutes les valeurs sont triées dans un ordre spécifique, croissant ou décroissant. Par conséquent, une table ou une vue ne peut avoir qu’un seul index clusterisé. De plus, il convient de noter que les données d'une table ne sont stockées sous forme triée que si un index clusterisé a été créé sur cette table.Une table qui n'a pas d'index clusterisé est appelée un tas.
Index non clusterisé
Contrairement à un index clusterisé, les feuilles d'un index non clusterisé contiennent uniquement ces colonnes ( clé) par lequel cet index est déterminé, et contient également un pointeur vers les lignes contenant des données réelles dans le tableau. Cela signifie que le système de sous-requêtes nécessite une opération supplémentaire pour localiser et récupérer les données requises. Le contenu du pointeur de données dépend de la manière dont les données sont stockées : table clusterisée ou tas. Si un pointeur pointe vers une table clusterisée, il pointe vers un index clusterisé qui peut être utilisé pour rechercher les données réelles. Si un pointeur fait référence à un tas, il pointe alors vers un identifiant de ligne de données spécifique. Les index non clusterisés ne peuvent pas être triés comme les index clusterisés, mais vous pouvez créer plusieurs index non clusterisés sur une table ou une vue, jusqu'à 999. Cela ne signifie pas que vous devez créer autant d'index que possible. Les index peuvent améliorer ou dégrader les performances du système. En plus de pouvoir créer plusieurs index non clusterisés, vous pouvez également inclure des colonnes supplémentaires ( colonne incluse) dans son index : les feuilles de l'index stockeront non seulement la valeur des colonnes indexées elles-mêmes, mais aussi les valeurs de ces colonnes supplémentaires non indexées. Cette approche vous permettra de contourner certaines des restrictions imposées à l'index. Par exemple, vous pouvez inclure une colonne non indexable ou contourner la limite de longueur d'index (900 octets dans la plupart des cas).Types d'index
En plus d'être clusterisé ou non clusterisé, l'index peut en outre être configuré en tant qu'index composite, index unique ou index de couverture.Index composé
Un tel index peut contenir plusieurs colonnes. Vous pouvez inclure jusqu'à 16 colonnes dans un index, mais leur longueur totale est limitée à 900 octets. Les index clusterisés et non clusterisés peuvent être composites.Indice unique
Cet index garantit que chaque valeur de la colonne indexée est unique. Si l'index est composite, l'unicité s'applique à toutes les colonnes de l'index, mais pas à chaque colonne individuelle. Par exemple, si vous créez un index unique sur les colonnes NOM Et NOM DE FAMILLE, alors le nom complet doit être unique, mais des doublons dans le prénom ou le nom sont possibles.Un index unique est automatiquement créé lorsque vous définissez une contrainte de colonne : contrainte de clé primaire ou de valeur unique :
- Clé primaire
Lorsque vous définissez une contrainte de clé primaire sur une ou plusieurs colonnes alors serveur SQL crée automatiquement un index clusterisé unique si aucun index clusterisé n'a été créé précédemment (dans ce cas, un index unique non clusterisé est créé sur la clé primaire) - Unicité des valeurs
Quand on définit une contrainte sur l'unicité des valeurs alors serveur SQL crée automatiquement un index non clusterisé unique. Vous pouvez spécifier qu'un index clusterisé unique soit créé si aucun index clusterisé n'a encore été créé sur la table
Indice de couverture
Un tel index permet à une requête spécifique d'obtenir immédiatement toutes les données nécessaires à partir des feuilles de l'index sans accès supplémentaire aux enregistrements de la table elle-même.Conception d'index
Aussi utiles que puissent être les index, ils doivent être conçus avec soin. Étant donné que les index peuvent occuper un espace disque important, vous ne souhaitez pas créer plus d’index que nécessaire. De plus, les index sont automatiquement mis à jour lorsque la ligne de données elle-même est mise à jour, ce qui peut entraîner une surcharge de ressources supplémentaire et une dégradation des performances. Lors de la conception d'index, plusieurs considérations concernant la base de données et les requêtes sur celle-ci doivent être prises en compte.Base de données
Comme indiqué précédemment, les index peuvent améliorer les performances du système car ils fournissent au moteur de requête un moyen rapide de trouver des données. Cependant, vous devez également prendre en compte la fréquence à laquelle vous comptez insérer, mettre à jour ou supprimer des données. Lorsque vous modifiez des données, les index doivent également être modifiés pour refléter les actions correspondantes sur les données, ce qui peut réduire considérablement les performances du système. Tenez compte des directives suivantes lors de la planification de votre stratégie d'indexation :- Pour les tables fréquemment mises à jour, utilisez le moins d’index possible.
- Si la table contient une grande quantité de données mais que les modifications sont mineures, utilisez autant d'index que nécessaire pour améliorer les performances de vos requêtes. Cependant, réfléchissez bien avant d'utiliser des index sur de petites tables, car... Il est possible que l'utilisation d'une recherche par index prenne plus de temps que la simple analyse de toutes les lignes.
- Pour les index clusterisés, essayez de conserver les champs aussi courts que possible. La meilleure approche consiste à utiliser un index clusterisé sur des colonnes qui ont des valeurs uniques et n'autorisent pas NULL. C'est pourquoi une clé primaire est souvent utilisée comme index clusterisé.
- Le caractère unique des valeurs d'une colonne affecte les performances de l'index. En général, plus vous avez de doublons dans une colonne, plus l'index est performant. En revanche, plus il y a de valeurs uniques, meilleures sont les performances de l’indice. Utilisez un index unique autant que possible.
- Pour un index composite, tenez compte de l'ordre des colonnes dans l'index. Colonnes utilisées dans les expressions OÙ(Par exemple, OÙ Prénom = "Charlie") doit être le premier dans l'index. Les colonnes suivantes doivent être répertoriées en fonction du caractère unique de leurs valeurs (les colonnes avec le plus grand nombre de valeurs uniques viennent en premier).
- Vous pouvez également spécifier un index sur les colonnes calculées si elles répondent à certaines exigences. Par exemple, les expressions utilisées pour obtenir la valeur d'une colonne doivent être déterministes (renvoie toujours le même résultat pour un ensemble donné de paramètres d'entrée).
Requêtes de base de données
Une autre considération lors de la conception d'index concerne les requêtes exécutées sur la base de données. Comme indiqué précédemment, vous devez tenir compte de la fréquence à laquelle les données changent. De plus, les principes suivants doivent être utilisés :- Essayez d'insérer ou de modifier autant de lignes que possible dans une seule requête, plutôt que de le faire dans plusieurs requêtes uniques.
- Créez un index non clusterisé sur les colonnes fréquemment utilisées comme termes de recherche dans vos requêtes. OÙ et les connexions dans REJOINDRE.
- Pensez à indexer les colonnes utilisées dans les requêtes de recherche de lignes pour obtenir des correspondances de valeurs exactes.
Et maintenant, en fait :
14 questions sur les index dans SQL Server que vous étiez gêné de poser
Pourquoi une table ne peut-elle pas avoir deux index clusterisés ?
Vous voulez une réponse courte ? Un index clusterisé est une table. Lorsque vous créez un index clusterisé sur une table, le moteur de stockage trie toutes les lignes de la table par ordre croissant ou décroissant, selon la définition de l'index. Un index clusterisé n'est pas une entité distincte comme les autres index, mais un mécanisme permettant de trier les données dans une table et de faciliter un accès rapide aux lignes de données.Imaginons que vous disposiez d'un tableau contenant l'historique des transactions de vente. Le tableau Ventes comprend des informations telles que l'ID de commande, la position du produit dans la commande, le numéro de produit, la quantité de produit, le numéro et la date de commande, etc. Vous créez un index clusterisé sur les colonnes Numéro de commande Et Id de ligne, triés par ordre croissant comme indiqué ci-dessous T-SQL code:
CRÉER UN INDEX CLUSTERÉ UNIQUE ix_oriderid_lineid ON dbo.Sales(OrderID, LineID);
Lorsque vous exécutez ce script, toutes les lignes de la table seront physiquement triées d'abord par la colonne OrderID, puis par LineID, mais les données elles-mêmes resteront dans un seul bloc logique, la table. Pour cette raison, vous ne pouvez pas créer deux index clusterisés. Il ne peut y avoir qu'une seule table avec une seule donnée et cette table ne peut être triée qu'une seule fois dans un ordre spécifique.
Si une table clusterisée offre de nombreux avantages, alors pourquoi utiliser un tas ?
Tu as raison. Les tables clusterisées sont excellentes et la plupart de vos requêtes fonctionneront mieux sur les tables dotées d'un index clusterisé. Mais dans certains cas, vous souhaiterez peut-être laisser les tables dans leur état naturel et intact, c'est-à-dire sous la forme d'un tas et créez uniquement des index non clusterisés pour que vos requêtes continuent de s'exécuter.Comme vous vous en souvenez, le tas stocke les données dans un ordre aléatoire. En règle générale, le sous-système de stockage ajoute des données à une table dans l'ordre dans lequel elles sont insérées, mais le sous-système de stockage aime également déplacer les lignes pour un stockage plus efficace. Par conséquent, vous n’avez aucune possibilité de prédire dans quel ordre les données seront stockées.
Si le moteur de requête doit rechercher des données sans bénéficier d'un index non clusterisé, il effectuera une analyse complète de la table pour trouver les lignes dont il a besoin. Sur de très petites tables, cela ne pose généralement pas de problème, mais à mesure que la taille du tas augmente, les performances diminuent rapidement. Bien sûr, un index non clusterisé peut aider en utilisant un pointeur vers le fichier, la page et la ligne où les données requises sont stockées - c'est généralement une bien meilleure alternative à une analyse de table. Malgré cela, il est difficile de comparer les avantages d’un index clusterisé en termes de performances des requêtes.
Cependant, le tas peut contribuer à améliorer les performances dans certaines situations. Considérons un tableau avec de nombreuses insertions mais peu de mises à jour ou de suppressions. Par exemple, une table stockant un journal est principalement utilisée pour insérer des valeurs jusqu'à ce qu'elle soit archivée. Sur le tas, vous ne verrez pas la pagination et la fragmentation des données comme vous le feriez avec un index clusterisé, car les lignes sont simplement ajoutées à la fin du tas. Trop diviser les pages peut avoir un impact significatif sur les performances, et pas dans le bon sens. En général, le tas vous permet d'insérer des données de manière relativement simple et vous n'aurez pas à gérer les frais de stockage et de maintenance qu'avec un index clusterisé.
Mais le manque de mise à jour et de suppression des données ne doit pas être considéré comme la seule raison. La manière dont les données sont échantillonnées est également un facteur important. Par exemple, vous ne devez pas utiliser de tas si vous interrogez fréquemment des plages de données ou si les données que vous interrogez doivent souvent être triées ou regroupées.
Tout cela signifie que vous ne devriez envisager d'utiliser le tas que lorsque vous travaillez avec de très petites tables ou que toute votre interaction avec la table se limite à l'insertion de données et que vos requêtes sont extrêmement simples (et que vous utilisez des index non clusterisés). de toute façon). Sinon, restez fidèle à un index clusterisé bien conçu, tel qu'un index défini sur un simple champ clé ascendant, comme une colonne largement utilisée avec IDENTITÉ.
Comment modifier le facteur de remplissage de l'index par défaut ?
Changer le facteur de remplissage de l'index par défaut est une chose. Comprendre comment fonctionne le taux de défaut est une autre affaire. Mais d’abord, prenons quelques pas en arrière. Le facteur de remplissage de l'index détermine la quantité d'espace sur la page pour stocker l'index au niveau inférieur (niveau feuille) avant de commencer à remplir une nouvelle page. Par exemple, si le coefficient est fixé à 90, alors lorsque l'index grandit, il occupera 90 % de la page puis passera à la page suivante.Par défaut, la valeur du facteur de remplissage de l'index est dans serveur SQL est 0, ce qui équivaut à 100. Par conséquent, tous les nouveaux index héritent automatiquement de ce paramètre, sauf si vous spécifiez spécifiquement une valeur dans votre code différente de la valeur standard du système ou si vous modifiez le comportement par défaut. Vous pouvez utiliser Studio de gestion de serveur SQL pour ajuster la valeur par défaut ou exécuter une procédure stockée système sp_configure. Par exemple, l'ensemble suivant T-SQL Les commandes fixent la valeur du coefficient à 90 (vous devez d'abord passer en mode paramètres avancés) :
EXEC sp_configure "afficher les options avancées", 1 ; ALLEZ RECONFIGURER ; GO EXEC sp_configure "facteur de remplissage", 90 ; ALLEZ RECONFIGURER ; ALLER
Après avoir modifié la valeur du facteur de remplissage de l'index, vous devez redémarrer le service serveur SQL. Vous pouvez maintenant vérifier la valeur définie en exécutant sp_configure sans le deuxième argument spécifié :
EXEC sp_configure "facteur de remplissage" GO
Cette commande doit renvoyer une valeur de 90. Par conséquent, tous les index nouvellement créés utiliseront cette valeur. Vous pouvez tester cela en créant un index et en recherchant la valeur du facteur de remplissage :
UTILISER AdventureWorks2012 ; -- votre base de données GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Dans cet exemple, nous avons créé un index non clusterisé sur une table Personne dans la base de données AventureWorks2012. Après avoir créé l'index, nous pouvons obtenir la valeur du facteur de remplissage à partir des tables système sys.indexes. La requête doit renvoyer 90.
Cependant, imaginons que nous supprimions l'index et le recréions, mais que nous spécifiions maintenant une valeur de facteur de remplissage spécifique :
CRÉER UN INDEX NON CLUSTERÉ ix_people_lastname ON Person.Person(LastName) AVEC (fillfactor=80); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Cette fois, nous avons ajouté des instructions AVEC et possibilité facteur de remplissage pour notre opération de création d'index CRÉER UN INDICE et spécifié la valeur 80. Opérateur SÉLECTIONNER renvoie maintenant la valeur correspondante.
Jusqu’à présent, tout a été assez simple. Là où vous pouvez vraiment vous brûler dans tout ce processus, c'est lorsque vous créez un index qui utilise une valeur de coefficient par défaut, en supposant que vous connaissez cette valeur. Par exemple, quelqu'un bricole les paramètres du serveur et est si têtu qu'il fixe le facteur de remplissage de l'index à 20. Pendant ce temps, vous continuez à créer des index, en supposant que la valeur par défaut est 0. Malheureusement, vous n'avez aucun moyen de connaître le remplissage de l'index. facteur jusqu'à ce que vous ne créiez pas d'index, puis vérifiez la valeur comme nous l'avons fait dans nos exemples. Sinon, vous devrez attendre le moment où les performances des requêtes chuteront tellement que vous commencerez à soupçonner quelque chose.
Un autre problème dont vous devez être conscient est la reconstruction des index. Comme pour la création d'un index, vous pouvez spécifier la valeur du facteur de remplissage de l'index lorsque vous le reconstruisez. Cependant, contrairement à la commande create index, la reconstruction n'utilise pas les paramètres par défaut du serveur, malgré ce que cela peut paraître. De plus, si vous ne spécifiez pas spécifiquement la valeur du facteur de remplissage d'index, alors serveur SQL utilisera la valeur du coefficient avec lequel cet indice existait avant sa restructuration. Par exemple, l'opération suivante MODIFIER L'INDEX reconstruit l'index que nous venons de créer :
ALTER INDEX ix_people_lastname ON Person.Person REBUILD ; GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Lorsque nous vérifions la valeur du facteur de remplissage, nous obtiendrons une valeur de 80, car c'est ce que nous avons spécifié lors de la dernière création de l'index. La valeur par défaut est ignorée.
Comme vous pouvez le constater, modifier la valeur du facteur de remplissage de l'index n'est pas si difficile. Il est beaucoup plus difficile de connaître la valeur actuelle et de comprendre quand elle sera appliquée. Si vous spécifiez toujours spécifiquement le coefficient lors de la création et de la reconstruction des index, vous connaissez toujours le résultat spécifique. À moins que vous ayez à vous soucier de vous assurer que quelqu'un d'autre ne bousille pas à nouveau les paramètres du serveur, ce qui entraînerait la reconstruction de tous les index avec un facteur de remplissage d'index ridiculement bas.
Est-il possible de créer un index clusterisé sur une colonne contenant des doublons ?
Oui et non. Oui, vous pouvez créer un index clusterisé sur une colonne clé contenant des valeurs en double. Non, la valeur d'une colonne clé ne peut pas rester dans un état non unique. Laisse-moi expliquer. Si vous créez un index clusterisé non unique sur une colonne, le moteur de stockage ajoute un uniquificateur à la valeur en double pour garantir l'unicité et donc pouvoir identifier chaque ligne de la table clusterisée.Par exemple, vous pouvez décider de créer un index clusterisé sur une colonne contenant des données client Nom de famille en gardant le nom de famille. La colonne contient les valeurs Franklin, Hancock, Washington et Smith. Ensuite, vous insérez à nouveau les valeurs Adams, Hancock, Smith et Smith. Mais la valeur de la colonne clé doit être unique, donc le moteur de stockage modifiera la valeur des doublons pour qu'ils ressemblent à ceci : Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 et Smith5678.
À première vue, cette approche semble bonne, mais une valeur entière augmente la taille de la clé, ce qui peut devenir un problème s'il y a un grand nombre de doublons, et ces valeurs deviendront la base d'un index non clusterisé ou d'un index étranger. référence clé. Pour ces raisons, vous devez toujours essayer de créer des index clusterisés uniques autant que possible. Si cela n’est pas possible, essayez au moins d’utiliser des colonnes avec un contenu de valeur unique très élevé.
Comment la table est-elle stockée si aucun index clusterisé n’a été créé ?
serveur SQL prend en charge deux types de tables : les tables clusterisées qui ont un index clusterisé et les tables de tas ou simplement des tas. Contrairement aux tables clusterisées, les données sur le tas ne sont en aucun cas triées. Essentiellement, il s'agit d'une pile (tas) de données. Si vous ajoutez une ligne à un tel tableau, le moteur de stockage l'ajoutera simplement à la fin de la page. Lorsque la page est remplie de données, elle sera ajoutée à une nouvelle page. Dans la plupart des cas, vous souhaiterez créer un index clusterisé sur une table pour profiter de la capacité de tri et de la vitesse des requêtes (essayez d'imaginer rechercher un numéro de téléphone dans un carnet d'adresses non trié). Toutefois, si vous choisissez de ne pas créer d'index clusterisé, vous pouvez toujours créer un index non clusterisé sur le tas. Dans ce cas, chaque ligne d'index aura un pointeur vers une ligne de tas. L'index comprend l'ID du fichier, le numéro de page et le numéro de ligne de données.Quelle est la relation entre les contraintes d'unicité de valeur et une clé primaire avec des index de table ?
Une clé primaire et une contrainte unique garantissent que les valeurs d'une colonne sont uniques. Vous ne pouvez créer qu'une seule clé primaire pour une table et elle ne peut pas contenir de valeurs NUL. Vous pouvez créer plusieurs restrictions sur l'unicité d'une valeur pour une table, et chacune d'elles peut avoir un seul enregistrement avec NUL.Lorsque vous créez une clé primaire, le moteur de stockage crée également un index clusterisé unique si aucun index cluster n'a déjà été créé. Cependant, vous pouvez remplacer le comportement par défaut et un index non clusterisé sera créé. Si un index clusterisé existe lorsque vous créez la clé primaire, un index non clusterisé unique sera créé.
Lorsque vous créez une contrainte unique, le moteur de stockage crée un index unique non clusterisé. Cependant, vous pouvez spécifier la création d'un index clusterisé unique si aucun index n'a été créé précédemment.
En général, une contrainte de valeur unique et un index unique sont la même chose.
Pourquoi les index clusterisés et non clusterisés sont-ils appelés B-tree dans SQL Server ?
Les index de base dans SQL Server, clusterisés ou non, sont distribués sur des ensembles de pages appelés nœuds d'index. Ces pages sont organisées selon une hiérarchie spécifique avec une arborescence appelée arbre équilibré. Au niveau supérieur se trouve le nœud racine, en bas se trouvent les nœuds feuilles, avec des nœuds intermédiaires entre les niveaux supérieur et inférieur, comme le montre la figure :Le nœud racine constitue le point d'entrée principal pour les requêtes tentant de récupérer des données via l'index. À partir de ce nœud, le moteur de requête lance une navigation vers le bas de la structure hiérarchique jusqu'au nœud feuille approprié contenant les données.
Par exemple, imaginez qu'une demande ait été reçue pour sélectionner des lignes contenant une valeur clé de 82. Le sous-système de requête commence à fonctionner à partir du nœud racine, qui fait référence à un nœud intermédiaire approprié, dans notre cas 1-100. Du nœud intermédiaire 1-100, il y a une transition vers le nœud 51-100, et de là vers le nœud final 76-100. S'il s'agit d'un index clusterisé, alors la feuille du nœud contient les données de la ligne associée à la clé égale à 82. S'il s'agit d'un index non clusterisé, alors la feuille d'index contient un pointeur vers la table clusterisée ou une ligne spécifique dans le tas.
Comment un index peut-il même améliorer les performances des requêtes si vous devez parcourir tous ces nœuds d'index ?
Premièrement, les index n’améliorent pas toujours les performances. Trop d’index mal créés transforment le système en un bourbier et dégradent les performances des requêtes. Il est plus exact de dire que si les indices sont appliqués avec soin, ils peuvent générer des gains de performances significatifs.Pensez à un énorme livre consacré au réglage des performances serveur SQL(version papier, pas version électronique). Imaginez que vous souhaitiez trouver des informations sur la configuration de Resource Governor. Vous pouvez faire glisser votre doigt page par page à travers tout le livre, ou ouvrir la table des matières et connaître le numéro de page exact avec les informations que vous recherchez (à condition que le livre soit correctement indexé et que le contenu ait les index corrects). Cela vous fera certainement gagner un temps considérable, même s'il vous faudra d'abord accéder à une toute autre structure (l'index) pour obtenir les informations dont vous avez besoin à partir de la structure primaire (le livre).
Comme un index de livre, un index dans serveur SQL vous permet d'exécuter des requêtes précises sur les données dont vous avez besoin au lieu d'analyser complètement toutes les données contenues dans une table. Pour les petites tables, une analyse complète ne pose généralement pas de problème, mais les grandes tables occupent de nombreuses pages de données, ce qui peut entraîner un temps d'exécution de requête important, à moins qu'un index n'existe pour permettre au moteur de requête d'obtenir immédiatement l'emplacement correct des données. Imaginez que vous vous perdez à un carrefour routier à plusieurs niveaux devant une grande métropole sans carte et vous comprendrez l'idée.
Si les index sont si performants, pourquoi ne pas simplement en créer un sur chaque colonne ?
Aucune bonne action ne doit rester impunie. C'est du moins le cas des index. Bien sûr, les index fonctionnent très bien tant que vous exécutez des requêtes de récupération d'opérateur SÉLECTIONNER, mais dès que les appels fréquents aux opérateurs commencent INSÉRER, MISE À JOUR Et SUPPRIMER, donc le paysage change très rapidement.Lorsque vous lancez une demande de données par l'opérateur SÉLECTIONNER, le moteur de requête trouve l'index, se déplace dans sa structure arborescente et découvre les données qu'il recherche. Quoi de plus simple ? Mais les choses changent si vous lancez une instruction de changement comme MISE À JOUR. Oui, pour la première partie de l'instruction, le moteur de requête peut à nouveau utiliser l'index pour localiser la ligne en cours de modification - c'est une bonne nouvelle. Et s'il y a un simple changement dans les données d'une ligne qui n'affecte pas les changements dans les colonnes clés, le processus de modification sera totalement indolore. Mais que se passe-t-il si le changement entraîne le fractionnement des pages contenant les données ou si la valeur d'une colonne clé est modifiée, ce qui entraîne son déplacement vers un autre nœud d'index - cela entraînera éventuellement une réorganisation de l'index affectant tous les index et opérations associés. , ce qui entraîne une baisse généralisée de la productivité.
Des processus similaires se produisent lors de l'appel d'un opérateur SUPPRIMER. Un index peut aider à localiser les données en cours de suppression, mais la suppression des données elle-même peut entraîner un remaniement des pages. Concernant l'opérateur INSÉRER, le principal ennemi de tous les index : vous commencez à ajouter une grande quantité de données, ce qui entraîne des modifications des index et leur réorganisation et tout le monde en souffre.
Tenez donc compte des types de requêtes sur votre base de données lorsque vous réfléchissez au type d’index et au nombre à créer. Plus ne veut pas dire mieux. Avant d'ajouter un nouvel index à une table, considérez non seulement le coût des requêtes sous-jacentes, mais également la quantité d'espace disque consommée, le coût de maintenance des fonctionnalités et des index, ce qui peut entraîner un effet domino sur d'autres opérations. Votre stratégie de conception d'index est l'un des aspects les plus importants de votre implémentation et doit inclure de nombreuses considérations, depuis la taille de l'index, le nombre de valeurs uniques, jusqu'au type de requêtes que l'index prendra en charge.
Est-il nécessaire de créer un index clusterisé sur une colonne avec une clé primaire ?
Vous pouvez créer un index clusterisé sur n'importe quelle colonne qui répond aux conditions requises. Il est vrai qu'un index clusterisé et une contrainte de clé primaire sont faits l'un pour l'autre et constituent une correspondance parfaite, alors comprenez le fait que lorsque vous créez une clé primaire, un index clusterisé sera automatiquement créé si aucun n'a été créé. créé auparavant. Cependant, vous pouvez décider qu’un index clusterisé fonctionnerait mieux ailleurs, et votre décision sera souvent justifiée.L'objectif principal d'un index clusterisé est de trier toutes les lignes de votre table en fonction de la colonne clé spécifiée lors de la définition de l'index. Cela permet une recherche rapide et un accès facile aux données du tableau.
La clé primaire d'une table peut être un bon choix car elle identifie de manière unique chaque ligne des tables sans avoir à ajouter de données supplémentaires. Dans certains cas, le meilleur choix sera une clé primaire de substitution, qui est non seulement unique, mais également de petite taille et dont les valeurs augmentent séquentiellement, rendant plus efficaces les index non clusterisés basés sur cette valeur. L'optimiseur de requêtes aime également cette combinaison d'un index clusterisé et d'une clé primaire, car la jointure de tables est plus rapide que la jointure d'une autre manière qui n'utilise pas de clé primaire et son index clusterisé associé. Comme je l'ai dit, c'est un match parfait.
Enfin, il convient de noter que lors de la création d'un index clusterisé, plusieurs aspects doivent être pris en compte : combien d'index non clusterisés seront basés sur celui-ci, à quelle fréquence la valeur de la colonne d'index clé changera et quelle est sa taille. Lorsque les valeurs dans les colonnes d'un index clusterisé changent ou que l'index ne fonctionne pas comme prévu, tous les autres index de la table peuvent être affectés. Un index clusterisé doit être basé sur la colonne la plus persistante dont les valeurs augmentent dans un ordre spécifique mais ne changent pas de manière aléatoire. L'index doit prendre en charge les requêtes sur les données de la table les plus fréquemment consultées, de sorte que les requêtes tirent pleinement parti du fait que les données sont triées et accessibles au niveau des nœuds racine, les feuilles de l'index. Si la clé primaire correspond à ce scénario, utilisez-la. Sinon, choisissez un autre ensemble de colonnes.
Et si vous indexez une vue, est-ce toujours une vue ?
Une vue est une table virtuelle qui génère des données à partir d'une ou plusieurs tables. Il s'agit essentiellement d'une requête nommée qui récupère les données des tables sous-jacentes lorsque vous interrogez cette vue. Vous pouvez améliorer les performances des requêtes en créant un index clusterisé et des index non clusterisés sur cette vue, de la même manière que vous créez des index sur une table, mais la principale mise en garde est que vous créez d'abord un index clusterisé, puis vous pouvez en créer un non clusterisé.Lorsqu'une vue indexée (vue matérialisée) est créée, la définition de la vue elle-même reste une entité distincte. Après tout, ce n'est qu'un opérateur codé en dur SÉLECTIONNER, stocké dans la base de données. Mais pour l’indice, c’est une tout autre histoire. Lorsque vous créez un index clusterisé ou non cluster sur un fournisseur, les données sont physiquement enregistrées sur le disque, tout comme un index classique. De plus, lorsque les données changent dans les tables sous-jacentes, l'index de la vue change automatiquement (cela signifie que vous souhaiterez peut-être éviter d'indexer les vues sur des tables qui changent fréquemment). Dans tous les cas, la vue reste une vue - une vue des tables, mais exécutée pour le moment, avec des index qui lui correspondent.
Avant de pouvoir créer un index sur une vue, celui-ci doit répondre à plusieurs contraintes. Par exemple, une vue ne peut référencer que des tables de base, mais pas d'autres vues, et ces tables doivent se trouver dans la même base de données. Il existe en fait de nombreuses autres restrictions, alors assurez-vous de consulter la documentation pour serveur SQL pour tous les détails sales.
Pourquoi utiliser un index couvrant plutôt qu’un index composite ?
Tout d’abord, assurons-nous de bien comprendre la différence entre les deux. Un index composé est simplement un index régulier contenant plusieurs colonnes. Plusieurs colonnes de clé peuvent être utilisées pour garantir que chaque ligne d'une table est unique, ou vous pouvez avoir plusieurs colonnes pour garantir que la clé primaire est unique, ou vous pouvez essayer d'optimiser l'exécution de requêtes fréquemment invoquées sur plusieurs colonnes. Toutefois, en général, plus un index contient de colonnes clés, moins il sera efficace, ce qui signifie que les index composites doivent être utilisés judicieusement.Comme indiqué, une requête peut grandement bénéficier si toutes les données requises sont immédiatement situées sur les feuilles de l'index, tout comme l'index lui-même. Ce n'est pas un problème pour un index clusterisé car toutes les données sont déjà là (c'est pourquoi il est si important de bien réfléchir lorsque vous créez un index clusterisé). Mais un index non clusterisé sur les feuilles ne contient que des colonnes clés. Pour accéder à toutes les autres données, l'optimiseur de requêtes nécessite des étapes supplémentaires, ce qui peut ajouter une surcharge importante à l'exécution de vos requêtes.
C'est là que l'indice de couverture vient à la rescousse. Lorsque vous définissez un index non clusterisé, vous pouvez spécifier des colonnes supplémentaires pour vos colonnes clés. Par exemple, disons que votre application interroge fréquemment les données des colonnes Numéro de commande Et Date de commande dans la table Ventes:
SELECT OrderID, OrderDate FROM Sales WHERE OrderID = 12345 ;
Vous pouvez créer un index composé non clusterisé sur les deux colonnes, mais la colonne OrderDate ne fera qu'ajouter une surcharge de maintenance de l'index sans servir de colonne clé particulièrement utile. La meilleure solution serait de créer un index de couverture sur la colonne clé Numéro de commande et colonne incluse en plus Date de commande:
CRÉER UN INDEX NON CLUSTERÉ ix_orderid ON dbo.Sales(OrderID) INCLUDE (OrderDate);
Cela évite les inconvénients de l'indexation des colonnes redondantes tout en conservant les avantages du stockage des données dans des feuilles lors de l'exécution de requêtes. La colonne incluse ne fait pas partie de la clé, mais les données sont stockées sur le nœud feuille, la feuille d'index. Cela peut améliorer les performances des requêtes sans aucune surcharge supplémentaire. De plus, les colonnes incluses dans l'index de couverture sont soumises à moins de restrictions que les colonnes clés de l'index.
Le nombre de doublons dans une colonne clé est-il important ?
Lorsque vous créez un index, vous devez essayer de réduire le nombre de doublons dans vos colonnes clés. Ou plus précisément : essayez de maintenir le taux de redoublement aussi bas que possible.Si vous travaillez avec un index composite, la duplication s'applique à toutes les colonnes clés dans leur ensemble. Une seule colonne peut contenir de nombreuses valeurs en double, mais il doit y avoir un minimum de répétitions parmi toutes les colonnes d'index. Par exemple, vous créez un index composé non clusterisé sur des colonnes Prénom Et Nom de famille, vous pouvez avoir plusieurs valeurs John Doe et de nombreuses valeurs Doe, mais vous souhaitez avoir le moins de valeurs John Doe possible, ou de préférence une seule valeur John Doe.
Le rapport d'unicité des valeurs d'une colonne clé est appelé sélectivité de l'index. Plus il y a de valeurs uniques, plus la sélectivité est élevée : un indice unique a la plus grande sélectivité possible. Le moteur de requête aime vraiment les colonnes avec des valeurs de sélectivité élevées, surtout si ces colonnes sont incluses dans les clauses WHERE de vos requêtes les plus fréquemment exécutées. Plus l'index est sélectif, plus le moteur de requête peut réduire rapidement la taille de l'ensemble de données résultant. L'inconvénient, bien sûr, est que les colonnes avec relativement peu de valeurs uniques seront rarement de bons candidats à l'indexation.
Est-il possible de créer un index non clusterisé sur un sous-ensemble spécifique uniquement des données d'une colonne clé ?
Par défaut, un index non cluster contient une ligne pour chaque ligne de la table. Bien sûr, vous pouvez dire la même chose à propos d’un index clusterisé, en supposant qu’un tel index est une table. Mais lorsqu'il s'agit d'un index non clusterisé, la relation un-à-un est un concept important car, à partir de la version SQL Serveur 2008, vous avez la possibilité de créer un index filtrable qui limite les lignes qu'il contient. Un index filtré peut améliorer les performances des requêtes car... il est plus petit et contient des statistiques filtrées et plus précises que toutes les statistiques tabulaires - cela conduit à la création de plans d'exécution améliorés. Un index filtré nécessite également moins d’espace de stockage et des coûts de maintenance inférieurs. L'index est mis à jour uniquement lorsque les données correspondant au filtre changent.De plus, un index filtrable est facile à créer. Chez l'opérateur CRÉER UN INDICE il vous suffit d'indiquer OÙétat du filtre. Par exemple, vous pouvez filtrer toutes les lignes contenant NULL de l'index, comme indiqué dans le code :
CRÉER UN INDEX NON CLUSTERÉ ix_trackingnumber ON Sales.SalesOrderDetail (CarrierTrackingNumber) OÙ CarrierTrackingNumber N'EST PAS NULL ;
Nous pouvons en effet filtrer toutes les données qui ne sont pas importantes dans les requêtes critiques. Mais soyez prudent, car... serveur SQL impose plusieurs restrictions sur les index filtrables, comme l'impossibilité de créer un index filtrable sur une vue, alors lisez attentivement la documentation.
Il se peut également que vous puissiez obtenir des résultats similaires en créant une vue indexée. Cependant, un index filtré présente plusieurs avantages, comme la possibilité de réduire les coûts de maintenance et d'améliorer la qualité de vos plans d'exécution. Les index filtrés peuvent également être reconstruits en ligne. Essayez ceci avec une vue indexée.
Et encore un peu du traducteur
Le but de l'apparition de cette traduction sur les pages de Habrahabr était de vous parler ou de vous rappeler le blog SimpleTalk de Porte Rouge.
Il publie de nombreux articles divertissants et intéressants.
Je ne suis affilié à aucun produit de l'entreprise Porte Rouge, ni avec leur vente.
Comme promis, des livres pour ceux qui veulent en savoir plus
Je recommande trois très bons livres de ma part (les liens mènent à allumer versions en magasin Amazone):
 |
Principes fondamentaux de Microsoft SQL Server 2012 T-SQL (référence du développeur) Auteur Itzik Ben-Gan Date de publication : 15 juillet 2012 L'auteur, maître dans son métier, fournit des connaissances de base sur le travail avec des bases de données. Si vous avez tout oublié ou si vous ne l'avez jamais su, cela vaut vraiment la peine d'être lu. | En principe, vous pouvez ouvrir des index simples Ajouter des balises
6. Index et optimisation des performances
Index dans les bases de données : finalité, impact sur les performances, principes de création d'index
6.1 A quoi servent les index ?
Les index sont des structures spéciales dans les bases de données qui vous permettent d'accélérer la recherche et le tri par un champ spécifique ou un ensemble de champs dans une table, et sont également utilisés pour garantir l'unicité des données. Le moyen le plus simple de comparer les index consiste à utiliser les index des livres. S'il n'y a pas d'index, nous devrons alors parcourir tout le livre pour trouver le bon endroit, mais avec un index, la même action peut être effectuée beaucoup plus rapidement.
En règle générale, plus il y a d'index, meilleures sont les performances des requêtes de base de données. Cependant, si le nombre d'index augmente de manière excessive, les performances des opérations de modification des données (insertion/modification/suppression) diminuent et la taille de la base de données augmente, l'ajout d'index doit donc être traité avec prudence.
Quelques principes généraux associés à la création d'index :
· Des index doivent être créés pour les colonnes utilisées dans les jointures, qui sont souvent utilisées pour les opérations de recherche et de tri. Veuillez noter que les index sont toujours créés automatiquement pour les colonnes soumises à une contrainte de clé primaire. Le plus souvent, ils sont créés pour des colonnes avec une clé étrangère (dans Access - automatiquement) ;
· un index doit être automatiquement créé pour les colonnes soumises à une contrainte d'unicité ;
· Il est préférable de créer des index pour les champs dans lesquels il existe un nombre minimum de valeurs répétitives et où les données sont uniformément réparties. Oracle dispose d'index de bits spéciaux pour les colonnes comportant un grand nombre de valeurs en double ; SQL Server et Access ne fournissent pas ce type d'index ;
· si la recherche est constamment effectuée sur un ensemble spécifique de colonnes (simultanément), alors dans ce cas, il peut être judicieux de créer un index composite (uniquement dans SQL Server) - un index pour un groupe de colonnes ;
· Lorsque des modifications sont apportées aux tables, les index superposés à cette table sont automatiquement modifiés. En conséquence, l'index peut devenir très fragmenté, ce qui a un impact sur les performances. Vous devez vérifier périodiquement le degré de fragmentation des index et les défragmenter. Lors du chargement d'une grande quantité de données, il est parfois judicieux de supprimer d'abord tous les index et de les recréer une fois l'opération terminée ;
· Des index peuvent être créés non seulement pour les tables, mais également pour les vues (uniquement dans SQL Server). Avantages - la possibilité de calculer les champs non pas au moment de la demande, mais au moment où de nouvelles valeurs apparaissent dans les tableaux.
Matériel théorique
Les index vous permettent de trouver des informations dans d'énormes bases de données aussi efficacement que possible.
SQL Server 2008 prend en charge deux types d'index de base : clusterisés et non clusterisés. Les deux types d'index sont implémentés sous la forme d'un arbre équilibré (B-tree), dans lequel le niveau feuille se trouve au niveau inférieur de la structure. La différence entre les deux types d'index réside dans le fait qu'un index clusterisé fournit un classement physique des données sur le disque. Un index clusterisé est clairsemé : les pointeurs dans les feuilles du B-tree pointent vers la page de données.
Un index non clusterisé est dense et contient uniquement les colonnes incluses dans la clé d'index. Dans les index denses, les pointeurs dans les feuilles du B-tree pointent vers les lignes des données réelles. Si une table n’a pas d’index cluster défini, elle est appelée table de tas ou non triée. Dans ce dernier cas, la table est physiquement organisée (triée) dans l'ordre dans lequel les nouveaux enregistrements sont ajoutés, contrairement aux tables avec des index clusterisés, qui sont classées par valeurs de clé de tri. On peut dire qu’une table peut être représentée sous l’une des deux formes suivantes, sous forme de tas ou d’index clusterisé.
Index clusterisés
Des index clusterisés peuvent être créés sur la base d'une ou plusieurs colonnes de table. Un tel index est appelé clé d'index et comporte un certain nombre de restrictions :
Les colonnes d'un index clusterisé sont appelées clé de clustering. Un index clusterisé a un impact particulier sur SQL Server car il l'oblige à trier les données d'une table en fonction de la clé de clustering. Étant donné qu’une table ne peut être ordonnée que dans un seul sens, elle ne peut avoir qu’un seul index clusterisé.
Les index clusterisés spécifient l'ordre de tri des données dans une table. Toutefois, les index clusterisés ne fournissent pas d'ordre de tri physique. Un index clusterisé n'organise pas physiquement les données sur le disque, car cela entraînerait de nombreuses E/S disque lorsque les pages sont divisées. Il garantit uniquement que la chaîne de pages indexée est logiquement ordonnée, permettant à SQL Server de naviguer directement dans la chaîne de pages lors de la recherche de données. À mesure que SQL Server parcourt une chaîne de pages indexées, les lignes de données sont lues dans l'ordre de la clé de clustering.
Index non clusterisé
Un index non clusterisé n'impose aucune restriction sur l'ordre des enregistrements dans une table. Vous pouvez donc créer de nombreux index non clusterisés sur la même table, mais ces index ont les mêmes restrictions que les index clusterisés :
Un index peut s'étendre sur un maximum de 16 colonnes ;
La taille maximale de la clé d'index est de 900 octets.
Le niveau feuille d'un index non cluster contient un pointeur vers les données souhaitées. Si la table possède un index clusterisé, le niveau feuille de l'index non clusterisé pointe vers la clé de clustering. S'il n'y a pas d'index clusterisé, les pages au niveau feuille pointent vers des lignes de données dans la table.
La syntaxe générale pour créer un index relationnel est la suivante :
CRÉER UN INDEX nom_index
SUR<объект>(colonne [, … n])
[ ; ]
Index composé
Un index composite peut être créé sur la base de plusieurs champs. Dans ce cas, les restrictions décrites précédemment s'appliquent. Si l'index est construit sur des champs de taille fixe, la somme des longueurs de ces champs ne doit pas dépasser ces 900 octets ; si l'index est construit sur des champs de longueur variable, la somme des tailles maximales des champs peut dépasser 900 octets. , mais la valeur des sommes pour chaque enregistrement ne peut pas dépasser 900 octets. Par exemple, une table comporte deux champs de longueur variable de 500 octets chacun. SQL Server vous permet de créer une clé composite basée sur ces deux champs s'il n'existe aucun enregistrement dont la longueur des deux champs totalise plus de 900 octets. Il convient de prêter attention au fait que l'index composite pour (Colonne1, Colonne2) est différent de (Colonne2, Colonne1), ainsi que des index créés séparément sur ces deux champs.
Fragmentation des index
Les fichiers du système d'exploitation se fragmentent généralement au fil du temps en raison d'écritures répétées. Les index peuvent également être fragmentés, mais la fragmentation des index est différente de la fragmentation des fichiers.
Lorsque vous créez un index, toutes les valeurs des clés d'index sont écrites de manière ordonnée sur les pages d'index. Lorsque vous supprimez une ligne d'une table, SQL Server doit supprimer l'entrée correspondante dans l'index, ce qui crée des trous dans la page d'index. SQL Server ne récupère pas l'espace libéré car le coût de détection et de réutilisation des trous dans l'index est trop élevé. Si la valeur dans la table de base change, SQL Server déplace l'enregistrement du pointeur vers un autre emplacement, ce qui crée un autre trou. Lorsque les pages d'index sont pleines et que le fractionnement des pages est nécessaire, l'index se fragmente à nouveau. Au fil du temps, les index des tables où se produisent les modifications de données se fragmentent.
Pour contrôler le degré de fragmentation de l'index, un paramètre appelé facteur de remplissage est couramment utilisé. Pour éliminer la fragmentation, vous pouvez également utiliser l'instruction ALTER INDEX. Le facteur de remplissage est un paramètre d'index qui spécifie le pourcentage d'espace libre réservé sur chaque page de niveau feuille lorsqu'un index est créé ou reconstruit. L'espace réservé permet d'attribuer des valeurs supplémentaires à l'avenir, réduisant ainsi le nombre de fractionnements de pages. Le facteur de remplissage est mesuré en pourcentages entiers ; par exemple, une valeur de 75 signifie que chaque page feuille créée doit contenir 25 % d'espace libre pour s’adapter aux valeurs futures.
Défragmentation des index
Étant donné que SQL Server ne restitue pas d'espace au système, vous devez périodiquement récupérer de l'espace vide dans l'index pour conserver les avantages en termes de performances qui ont initialement créé l'index. Pour défragmenter les index, utilisez l'instruction ALTER INDEX.
ALTER INDEX ( nom_index | TOUS )
SUR
[ AVEC (
| [ PARTITION =numéro_partition
[ AVEC (
[ PARTITION =numéro_partition ]
[ AVEC (LOB_COMPACTION = ( ON | OFF )) ]
| ENSEMBLE (
Lors de la défragmentation des index, vous pouvez sélectionner les options REBUILD ou REORGANIZE.
Le premier paramètre reconstruit tous les niveaux d'index et remplit les pages en fonction du paramètre de facteur de remplissage. Lorsque vous reconstruisez un index clusterisé, seul cet index est reconstruit, mais si vous spécifiez l'option ALL, l'index clusterisé et tous les index non clusterisés de la table sont reconstruits. Une reconstruction d'index met à jour l'intégralité de la structure B-tree, donc à moins que ONLINE ne soit spécifié, la table est verrouillée jusqu'à ce que la reconstruction soit terminée. Par exemple, afin de reconstruire l'index IX_BillID sur la table BillItem, vous devez exécuter la requête suivante :
MODIFIER L'INDEX IX_BillID
L'option REORGANIZE élimine la défragmentation au niveau feuille uniquement. Les pages intermédiaires et la page racine ne sont pas défragmentées. L'opération REORGANIZE est toujours effectuée en ligne, elle n'entraîne donc pas de verrouillage de table à long terme. Par exemple, pour réorganiser l'index IX_BillID sur la table BillItem, vous exécuterez la requête suivante :
MODIFIER L'INDEX IX_BillID
Travailler avec des index dans MS SQL Server Management Studio
Afin de voir quels index ont été créés, vous devez ouvrir l'onglet Index de la table Bill dans le panneau Explorateur d'objets. Le chemin complet vers l'onglet : Bases de données ® EducationDatabase ® Tables ® [nom de la table] ® Index est illustré dans la figure 1.1. Selon la figure, un index clusterisé PK_Bill a été créé pour cette table.
Vérifiez vous-même les index clusterisés sur toutes les tables de base de données.
Figure 1.1 – Explorateur d'objets, onglet Index développé
Créons un index supplémentaire sur le champ de clé étrangère BillID de la table BillItem. Il existe deux manières de créer un index :
Exécution de la requête CREATE INDEX. Créons une requête dans un nouvel onglet en cliquant sur le bouton Nouvelle requête de la barre d'outils standard. La barre d'outils est illustrée à la figure 1.2.
Figure 1.2 – Barre d'outils
Après avoir ouvert un nouvel onglet, exécutons la requête illustrée dans la figure 1.3. Pour exécuter la requête, vous devez cliquer sur le bouton Exécuter de la barre d'outils (Figure 1.2) ou appuyer sur la touche F5 du clavier.

Utilisation de l'interface graphique de Microsoft SQL Server Management Studio. Dans le menu contextuel, onglet Index, sélectionnez Nouvel index, comme le montre la figure 1.4.

Figure 1.4 – Menu contextuel de l'onglet Index
Dans la fenêtre qui s'ouvre, vous devez spécifier le nom de l'index, les attributs de tri et le type d'index (index XML clusterisé, non clusterisé ou principal). Si une table possède déjà un index clusterisé, lorsque vous essayez de créer un nouvel index clusterisé, le système vous avertira de la possibilité de supprimer l'index existant et d'en créer un nouveau. Lorsque vous créez un index clusterisé, tous les index non clusterisés sont reconstruits.
De plus, dans la fenêtre de création d'index, vous pouvez spécifier un indicateur pour prendre en charge l'unicité des valeurs dans les champs indexés. Avoir un tel index empêchera l'ajout de valeurs en double aux champs indexés.
1. Vérifiez la présence d'index sur les champs clés de la table. Si nécessaire, créez des index clusterisés. Pour créer un nouvel index, utilisez la commande CREATE INDEX, ou dans Microsoft SQL Management Studio, dans la section Tables/table_name/Indexes, utilisez la commande New Index....
2. Créez des index non clusterisés sur les champs de clé étrangère des tables de base de données. Expliquez pourquoi de tels index sont nécessaires ?
3. Créez des index non clusterisés sur les champs d'information : Nom et Date dans toutes les tables de la base de données. Expliquez pourquoi de tels index sont nécessaires ?
4. Pour un index clusterisé et un index basé sur le champ Date de la table des enregistrements d'un reçu, obtenez des informations sur les propriétés étendues des index. Expliquez la signification des informations fournies dans la section Fragmentation de la page Propriétés. Expliquez comment sont calculés la profondeur de l'arbre d'index, le nombre de feuilles et le facteur de fragmentation.
5. Reconstruisez l'index clusterisé sur la table BillItem à l'aide de la commande ALTER INDEX ou de la commande Rebuild du menu contextuel de l'index.
6. Préparer le matériel à inclure dans la présentation du rapport pour le cours Bases de données : cours spécial.
1) Notion d'indice
Indice est un outil qui permet un accès rapide aux lignes du tableau en fonction des valeurs d'une ou plusieurs colonnes.
Il existe une grande variété dans cet opérateur car il n'est pas standardisé, puisque les normes ne traitent pas des problèmes de performances.
2) Création d'index
CRÉER UN INDICE
SUR()
3) Modification et suppression d'index
Pour contrôler l'activité de l'index, l'opérateur est utilisé :
MODIFIER L'INDEX
Pour supprimer un index, utilisez l'opérateur :
INDICE DE BAISSE
a) Règles de sélection des tables
1. Il est conseillé d'indexer les tableaux dans lesquels pas plus de 5 % des lignes sont sélectionnées.
2. Les tables qui n'ont pas de doublons dans la clause WHERE de l'instruction SELECT doivent être indexées.
3. Il n'est pas pratique d'indexer des tableaux fréquemment mis à jour.
4. Il est inapproprié d'indexer des tables qui n'occupent pas plus de 2 pages (pour Oracle, cela représente moins de 300 lignes), car son analyse complète ne prend pas plus de temps.
b) Règles de sélection des colonnes
1. Clés primaires et étrangères – souvent utilisées pour joindre des tables, récupérer des données et effectuer des recherches. Ce sont toujours des index uniques avec une utilité maximale
2. Lorsque vous utilisez les options d'intégrité référentielle, vous avez toujours besoin d'un index sur le FK.
3. Colonnes selon lesquelles les données sont souvent triées et/ou regroupées.
4. Colonnes fréquemment recherchées dans la clause WHERE d'une instruction SELECT.
5. Vous ne devez pas créer d'index sur de longues colonnes descriptives.
c) Principes de création d'index composites
1. Les index composites sont utiles si les colonnes individuelles ont peu de valeurs uniques, mais un index composite offre plus d'unicité.
2. Si toutes les valeurs sélectionnées par l'instruction SELECT appartiennent à un index composite, alors les valeurs sont sélectionnées dans l'index.
3. Un index composé doit être créé si la clause WHERE utilise deux valeurs ou plus combinées avec l'opérateur AND.
d) Il n'est pas recommandé de créer
Il n'est pas recommandé de créer des index sur des colonnes, y compris composites, qui :
1. Rarement utilisé pour rechercher, fusionner et trier les résultats de requêtes.
2. Contenir des valeurs qui changent fréquemment, ce qui nécessite une mise à jour fréquente de l'index, ce qui ralentit les performances de la base de données.
3. Contenir un petit nombre de valeurs uniques (moins de 10 % m/f) ou un nombre prédominant de lignes avec une ou deux valeurs (la ville de résidence du fournisseur est Moscou).
4. Des fonctions ou une expression leur sont appliquées dans la clause WHERE et l'index ne fonctionne pas.
e) Il ne faut pas oublier
Vous devez vous efforcer de réduire le nombre d'index, car un grand nombre d'entre eux réduit la vitesse de mise à jour des données. Ainsi, MS SQL Server recommande de ne pas créer plus de 16 index par table.
En règle générale, les index sont créés à des fins de requête et pour maintenir l'intégrité référentielle.
Si l'index n'est pas utilisé pour les requêtes, il doit alors être supprimé et l'intégrité référentielle doit être garantie à l'aide de déclencheurs.