L'article d'aujourd'hui expliquera comment les variables peuvent être liées les unes aux autres. Grâce à la corrélation, nous pouvons déterminer s'il existe une relation entre la première et la deuxième variable. J'espère que vous trouverez cette activité aussi amusante que les précédentes !
La corrélation mesure la force et la direction de la relation entre x et y. La figure montre Divers types corrélations sous forme de nuages de points de paires ordonnées (x, y). Traditionnellement, la variable x est placée sur l'axe horizontal et la variable y est placée sur l'axe vertical.

Le graphique A est un exemple de corrélation linéaire positive : à mesure que x augmente, y augmente également, et de manière linéaire. Le graphique B nous montre un exemple de corrélation linéaire négative, où à mesure que x augmente, y diminue linéairement. Dans le graphique C, nous voyons qu’il n’y a pas de corrélation entre x et y. Ces variables ne s’influencent en aucune façon.
Enfin, le graphique D est un exemple de relations non linéaires entre variables. À mesure que x augmente, y diminue d’abord, puis change de direction et augmente.
Le reste de l'article se concentre sur les relations linéaires entre les variables dépendantes et indépendantes.
Coefficient de corrélation
Le coefficient de corrélation, r, nous fournit à la fois la force et la direction de la relation entre les variables indépendantes et dépendantes. Les valeurs de r varient entre - 1,0 et + 1,0. Lorsque r est positif, la relation entre x et y est positive (graphique A sur la figure), et lorsque r est négatif, la relation est également négative (graphique B). Coefficient de corrélation proche de valeur nulle, indique qu'il n'y a aucune relation entre x et y graphique C).
La force de la relation entre x et y est déterminée selon que le coefficient de corrélation est proche de - 1,0 ou de +- 1,0. Étudiez le dessin suivant.

Le graphique A montre une corrélation positive parfaite entre x et y à r = + 1,0. Graphique B - corrélation négative idéale entre x et y à r = - 1,0. Les graphiques C et D sont des exemples de relations plus faibles entre les variables dépendantes et indépendantes.
Le coefficient de corrélation, r, détermine à la fois la force et la direction de la relation entre les variables dépendantes et indépendantes. Les valeurs r vont de - 1,0 (forte relation négative) à + 1,0 (forte relation positive). Lorsque r = 0, il n'y a aucun lien entre les variables x et y.
Nous pouvons calculer le coefficient de corrélation réel à l’aide de l’équation suivante :

Bien bien! Je sais que cette équation ressemble à un désordre effrayant personnages étranges, mais avant de paniquer, appliquons-y l'exemple de note d'examen. Disons que je souhaite déterminer s'il existe une relation entre le nombre d'heures qu'un étudiant consacre à l'étude des statistiques et la note obtenue à l'examen final. Le tableau ci-dessous nous aidera à décomposer cette équation en plusieurs calculs simples et à les rendre plus gérables.

![]()

Comme vous pouvez le constater, il existe une très forte corrélation positive entre le nombre d’heures consacrées à l’étude d’une matière et la note obtenue à l’examen. Les enseignants seront très heureux de le savoir.
Quel est l’avantage d’établir des relations entre des variables similaires ? Excellente question. Si une relation existe, nous pouvons prédire les résultats de l'examen en fonction de Un certain montant heures consacrées à l’étude du sujet. En termes simples, plus la connexion est forte, plus notre prédiction sera précise.
Utiliser Excel pour calculer les coefficients de corrélation
Je suis sûr que lorsque vous examinerez ces terribles calculs de coefficients de corrélation, vous serez vraiment ravi de savoir que Programme Excel peut faire tout ce travail pour vous en utilisant la fonction CORREL avec les caractéristiques suivantes :
CORREL (tableau 1 ; tableau 2),
tableau 1 = plage de données pour la première variable,
tableau 2 = plage de données pour la deuxième variable.
Par exemple, la figure montre la fonction CORREL utilisée pour calculer le coefficient de corrélation pour l'exemple de note d'examen.

Considérez la candidature dansMSEXCELLERTest du chi carré de Pearson pour tester des hypothèses simples.
Après avoir obtenu des données expérimentales (c'est-à-dire lorsqu'il existe des échantillon) on choisit généralement la loi de distribution qui décrit le mieux la variable aléatoire représentée par un échantillonnage. La vérification de la qualité de la description des données expérimentales par la loi de distribution théorique sélectionnée est effectuée à l'aide de critères d'accord. Hypothèse nulle, il existe généralement une hypothèse sur l'égalité de la distribution d'une variable aléatoire avec une loi théorique.
Regardons d'abord l'application Test d'adéquation de Pearson X 2 (chi carré) par rapport à des hypothèses simples (les paramètres de la distribution théorique sont considérés comme connus). Puis - , lorsque seule la forme de la distribution est précisée, et les paramètres de cette distribution et la valeur statistiques X2 sont évalués/calculés sur la base des mêmes échantillons.
Note: Dans la littérature anglophone, la procédure de candidature Test d'adéquation de Pearson X2 a un nom Le test d'ajustement du chi carré.
Rappelons la procédure de test des hypothèses :
- basé échantillons la valeur est calculée statistiques, ce qui correspond au type d’hypothèse testée. Par exemple, pour utilisé t-statistiques(si inconnu);
- soumis à la vérité hypothèse nulle, la répartition de ce statistiques est connu et peut être utilisé pour calculer des probabilités (par exemple, pour t-statistiques Ce );
- calculé sur la base échantillons signification statistiques par rapport à la valeur critique pour une valeur donnée ();
- hypothèse nulle rejeter si valeur statistiques supérieure à critique (ou si la probabilité d'obtenir cette valeur statistiques() moins niveau de signification, ce qui est une approche équivalente).
Réalisons tests d'hypothèses pour diverses distributions.
Boîtier discret
Supposons que deux personnes jouent aux dés. Chaque joueur possède son propre jeu de dés. Les joueurs lancent à tour de rôle 3 dés à la fois. Chaque tour est remporté par celui qui obtient le plus de six à la fois. Les résultats sont enregistrés. L’un des joueurs, après 100 tours, soupçonnait que les dés de son adversaire étaient asymétriques, car il gagne souvent (il lance souvent des six). Il a décidé d’analyser la probabilité d’un tel nombre d’issues ennemies.
Note: Parce que Il y a 3 cubes, vous pouvez alors en lancer 0 à la fois ; 1; 2 ou 3 six, c'est-à-dire une variable aléatoire peut prendre 4 valeurs.
De la théorie des probabilités, nous savons que si les dés sont symétriques, alors la probabilité d'obtenir des six obéit. Par conséquent, après 100 tours, les fréquences des six peuvent être calculées à l'aide de la formule
=BINOM.DIST(A7,3,1/6,FALSE)*100
La formule suppose que dans la cellule A7 contient le nombre correspondant de six lancés en un tour.
Note: Les calculs sont donnés en exemple de fichier sur la feuille Discrète.
En comparaison observé(Observé) et fréquences théoriques(Attendu) pratique à utiliser.

Si les fréquences observées s'écartent significativement de la distribution théorique, hypothèse nulle sur la distribution d'une variable aléatoire selon une loi théorique doit être rejetée. Autrement dit, si les dés de l'adversaire sont asymétriques, alors les fréquences observées seront « significativement différentes » de distribution binomiale.
Dans notre cas, à première vue, les fréquences sont assez proches et sans calculs il est difficile de tirer une conclusion sans ambiguïté. En vigueur Test d'adéquation de Pearson X 2, de sorte qu'au lieu de l'affirmation subjective « substantiellement différent », qui peut être faite sur la base d'une comparaison histogrammes, utilisez une affirmation mathématiquement correcte.
Nous utilisons le fait qu'en raison de loi grands nombres fréquence observée (Observée) avec un volume croissant échantillons n tend vers la probabilité correspondant à la loi théorique (dans notre cas, loi binomiale). Dans notre cas, la taille de l’échantillon n est de 100.
Présentons test statistiques, que l'on note X 2 :

où O l est la fréquence observée des événements que la variable aléatoire a pris dans certains cas valeurs valides, E l est la fréquence théorique correspondante (Attendue). L est le nombre de valeurs que peut prendre une variable aléatoire (dans notre cas c'est 4).
Comme le montre la formule, ceci statistiques est une mesure de la proximité des fréquences observées par rapport aux fréquences théoriques, c'est-à-dire il peut être utilisé pour estimer les « distances » entre ces fréquences. Si la somme de ces « distances » est « trop grande », alors ces fréquences sont « significativement différentes ». Il est clair que si notre cube est symétrique (c'est-à-dire applicable loi binomiale), alors la probabilité que la somme des « distances » soit « trop grande » sera faible. Pour calculer cette probabilité, nous devons connaître la distribution statistiques X2 ( statistiques X 2 calculé sur la base du hasard échantillons, c'est donc une variable aléatoire et a donc son propre distribution de probabilité).
De l’analogue multidimensionnel Théorème intégral de Moivre-Laplace on sait que pour n->∞ notre variable aléatoire X 2 est asymptotiquement à L - 1 degrés de liberté.
Donc si la valeur calculée statistiques X 2 (la somme des « distances » entre les fréquences) sera supérieure à une certaine valeur limite, nous aurons alors des raisons de rejeter hypothèse nulle. Identique à vérifier hypothèses paramétriques, la valeur limite est réglée via niveau de signification. Si la probabilité que la statistique X2 prenne une valeur inférieure ou égale à celle calculée ( p-signification), sera moindre niveau de signification, Que hypothèse nulle peut être rejeté.
Dans notre cas, la valeur statistique est de 22,757. La probabilité que la statistique X2 prenne une valeur supérieure ou égale à 22,757 est très faible (0,000045) et peut être calculée à l'aide des formules
=CHI2.DIST.PH(22.757,4-1) ou
=CHI2.TEST(Observé ; Attendu)
Note: La fonction CHI2.TEST() est spécifiquement conçue pour tester la relation entre deux variables catégorielles (voir).
La probabilité 0,000045 est nettement inférieure à la normale niveau de signification 0,05. Ainsi, le joueur a toutes les raisons de soupçonner son adversaire de malhonnêteté ( hypothèse nulle son honnêteté est niée).

Lors de l'utilisation critère X 2 il faut s'assurer que le volume échantillons n était suffisamment grand, sinon l'approximation de la distribution ne serait pas valide statistiques X 2. On pense généralement que pour cela, il suffit que les fréquences observées (Observées) soient supérieures à 5. Si ce n'est pas le cas, alors les petites fréquences sont combinées en une ou ajoutées à d'autres fréquences, et la valeur combinée se voit attribuer un total probabilité et, par conséquent, le nombre de degrés de liberté est réduit X2 distributions.
Afin d'améliorer la qualité de l'application critère X 2(), il faut réduire les intervalles de partition (augmenter L et, par conséquent, augmenter le nombre degrés de liberté), cependant, cela est empêché par la limitation du nombre d'observations incluses dans chaque intervalle (db>5).
Cas continu
Test d'adéquation de Pearson X2 peut également être appliqué en cas de .
Considérons un certain échantillon, composé de 200 valeurs. Hypothèse nulle stipule que échantillon fait à partir de .
Note: Variables aléatoires dans exemple de fichier sur la feuille continue généré à l'aide de la formule =NORM.ST.INV(RAND()). Donc de nouvelles valeurs échantillons sont générés à chaque recalcul de la feuille.
La pertinence de l’ensemble de données existant peut être évaluée visuellement.

Comme le montre le diagramme, les valeurs de l'échantillon s'adaptent assez bien le long de la ligne droite. Cependant, comme pour tests d'hypothèses en vigueur Test d'ajustement du Pearson X 2.
Pour ce faire, nous divisons la plage de changement de la variable aléatoire en intervalles avec un pas de 0,5. Calculons les fréquences observées et théoriques. Nous calculons les fréquences observées à l'aide de la fonction FREQUENCY(), et les fréquences théoriques à l'aide de la fonction NORM.ST.DIST().
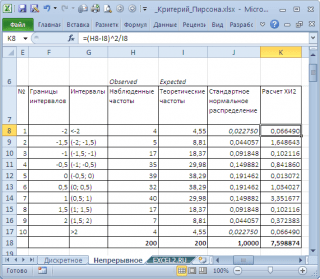
Note: Idem que pour cas discret, il faut s'assurer que échantillonétait assez grand et l'intervalle comprenait> 5 valeurs.
Calculons la statistique X2 et comparons-la avec la valeur critique pour un niveau de signification(0,05). Parce que nous avons divisé la plage de changement d'une variable aléatoire en 10 intervalles, le nombre de degrés de liberté est alors 9. La valeur critique peut être calculée à l'aide de la formule
=CHI2.OBR.PH(0,05;9) ou
=CHI2.OBR(1-0,05;9)
Le diagramme ci-dessus montre que la valeur statistique est de 8,19, ce qui est nettement plus élevé valeur critique – hypothèse nulle n'est pas rejeté.
Ci-dessous, où échantillon a pris une signification improbable et basée sur critères Consentement de Pearson X 2 l'hypothèse nulle a été rejetée (même si les valeurs aléatoires ont été générées à l'aide de la formule =NORM.ST.INV(RAND()), fournissant échantillon depuis distribution normale standard).

Hypothèse nulle rejeté, bien que visuellement les données soient situées assez près d'une ligne droite.
Prenons également comme exemple échantillon de U(-3; 3). Dans ce cas, même à partir du graphique, il est évident que hypothèse nulle devrait être rejeté.

Critère Consentement de Pearson X 2 confirme également que hypothèse nulle devrait être rejeté.
TRAVAUX DE LABORATOIRE
ANALYSE DE CORRÉLATION DANSEXCELLER
1.1 Analyse de corrélation dans MS Excel
L'analyse de corrélation consiste à déterminer le degré de connexion entre deux variables aléatoires X et Y. Le coefficient de corrélation est utilisé comme mesure d'une telle connexion. Le coefficient de corrélation est estimé à partir d'un échantillon de n paires d'observations liées (x i, y i) de la population commune de X et Y. Pour évaluer le degré de relation entre les valeurs de X et Y, mesurées dans des échelles quantitatives, il est utilisé coefficient de corrélation linéaire(coefficient de Pearson), qui suppose que les échantillons X et Y sont normalement distribués.
Le coefficient de corrélation varie de -1 (relation linéaire inverse stricte) à 1 (relation proportionnelle directe stricte). Lorsqu'il est défini sur 0, il n'y a pas de relation linéaire entre les deux échantillons.
Classification générale des corrélations (d'après Ivanter E.V., Korosov A.V., 1992) :
Il existe plusieurs types de coefficients de corrélation, selon les variables X et Y, qui peuvent être mesurés à différentes échelles. C'est ce fait qui détermine le choix du coefficient de corrélation approprié (voir tableau 13) :
Dans MS Excel, une fonction spéciale est utilisée pour calculer les coefficients de corrélation linéaire des paires CORREL (tableau1 ; tableau2),
|
№ sujets | ||
Exemple 1: 10 écoliers ont passé des tests de pensée visuelle-figurative et verbale. Le temps moyen nécessaire pour résoudre les tâches de test a été mesuré en secondes. Le chercheur s'intéresse à la question : existe-t-il une relation entre le temps nécessaire pour résoudre ces problèmes ? La variable X désigne le temps moyen pour résoudre les tests visuels-figuratifs et la variable Y désigne le temps moyen pour résoudre les tâches de test verbal.
R.  solution: Pour identifier le degré de relation, il est tout d'abord nécessaire de saisir les données dans un tableau MS Excel (voir tableau, Fig. 1). Ensuite, la valeur du coefficient de corrélation est calculée. Pour ce faire, placez le curseur dans la cellule C1. Dans la barre d'outils, cliquez sur le bouton Insérer une fonction (fx).
solution: Pour identifier le degré de relation, il est tout d'abord nécessaire de saisir les données dans un tableau MS Excel (voir tableau, Fig. 1). Ensuite, la valeur du coefficient de corrélation est calculée. Pour ce faire, placez le curseur dans la cellule C1. Dans la barre d'outils, cliquez sur le bouton Insérer une fonction (fx).
Dans la boîte de dialogue Assistant de fonctionnalité qui apparaît, sélectionnez une catégorie Statistique et fonction CORREL, puis cliquez sur OK. À l’aide du pointeur de la souris, entrez la plage de données d’échantillon X dans le champ array1 (A1:A10). Dans le champ array2, saisissez la plage de données d'échantillon Y (B1:B10). Cliquez sur OK. Dans la cellule C1, la valeur du coefficient de corrélation apparaîtra - 0,54119. Ensuite, vous devez examiner le nombre absolu du coefficient de corrélation et déterminer le type de connexion (étroite, faible, moyenne, etc.)
Riz. 1. Résultats du calcul du coefficient de corrélation
Ainsi, le lien entre le temps de résolution des tâches de test visuel-figuratif et verbal n'a pas été prouvé.
Exercice 1. Les données sont disponibles pour 20 exploitations agricoles. Trouver Coefficient de corrélation entre les rendements des cultures céréalières et la qualité des terres et évaluer leur importance. Les données sont présentées dans le tableau.
Tableau 2. Dépendance du rendement céréalier sur la qualité des terres
|
Numéro de ferme |
Qualité du terrain, score |
Productivité, c/ha |
Tâche 2. Déterminez s'il existe un lien entre la durée de fonctionnement d'un équipement de fitness sportif (milliers d'heures) et le coût de sa réparation (milliers de roubles) :
|
Temps de fonctionnement du simulateur (milliers d'heures) |
Coût des réparations (milliers de roubles) |
1.2 Corrélation multiple dans MS Excel
Avec un grand nombre d'observations, lorsque les coefficients de corrélation doivent être calculés séquentiellement pour plusieurs échantillons, pour plus de commodité, les coefficients obtenus sont résumés dans des tableaux appelés matrices de corrélation.
Matrice de corrélation est un tableau carré dans lequel à l'intersection des lignes et colonnes correspondantes se trouve un coefficient de corrélation entre les paramètres correspondants.
Dans MS Excel, la procédure est utilisée pour calculer des matrices de corrélation Corrélation du paquet L'analyse des données. La procédure permet d'obtenir une matrice de corrélation contenant des coefficients de corrélation entre différents paramètres.
Pour mettre en œuvre la procédure dont vous avez besoin :
1. exécutez la commande Service - Analyse données;
2. dans la liste qui apparaît Outils d'analyse sélectionner une ligne Corrélation et appuyez sur le bouton D'ACCORD;
3. dans la boîte de dialogue qui apparaît, précisez Intervalle de saisie, c'est-à-dire saisir un lien vers les cellules contenant les données analysées. L'intervalle de saisie doit contenir au moins deux colonnes.
4. en coupe Regroupement régler le commutateur en fonction des données saisies (par colonnes ou par lignes) ;
5. indiquer jour de congé intervalle, c'est-à-dire entrez un lien vers la cellule à partir de laquelle les résultats de l'analyse seront affichés. La taille de la plage de sortie sera déterminée automatiquement et un message s'affichera si la plage de sortie peut chevaucher les données source. appuie sur le bouton D'ACCORD.
Une matrice de corrélation sera sortie vers la plage de sortie, dans laquelle à l'intersection de chaque ligne et colonne se trouve un coefficient de corrélation entre les paramètres correspondants. Les cellules de la plage de sortie dont les coordonnées de ligne et de colonne correspondent contiennent la valeur 1 car chaque colonne est plage d'entrée complètement corrélé avec lui-même
Exemple 2. Il existe des données d'observation mensuelles sur les conditions météorologiques et la fréquentation des musées et des parcs (voir tableau 3). Il est nécessaire de déterminer s'il existe une relation entre les conditions météorologiques et la fréquentation des musées et des parcs.
Tableau 3. Résultats des observations
|
Nombre de jours francs |
Nombre de visiteurs du musée |
Nombre de visiteurs du parc |
Solution. Pour effectuer une analyse de corrélation, entrez les données originales dans la plage A1: G3 (Fig. 2). Puis dans le menu Service sélectionner un article Analyse données puis entrez la ligne Corrélation. Dans la boîte de dialogue qui apparaît, précisez Intervalle de saisie(A2:C7). Spécifiez que les données sont examinées en colonnes. Spécifiez la plage de sortie (E1) et appuyez sur le bouton D'ACCORD.
En figue. 33 montre que la corrélation entre les conditions météorologiques et la fréquentation des musées est de -0,92, et entre les conditions météorologiques et la fréquentation des parcs est de 0,97, et entre la fréquentation des parcs et des musées est de 0,92.
Ainsi, à la suite de l'analyse, des dépendances ont été révélées : un fort degré de relation linéaire inverse entre la fréquentation des musées et le nombre de jours ensoleillés et une relation presque linéaire (très forte directe) entre la fréquentation du parc et les conditions météorologiques. Il existe une forte relation inverse entre la fréquentation des musées et celle des parcs.

Riz. 2. Résultats du calcul de la matrice de corrélation de l'exemple 2
Tâche 3. 10 managers ont été évalués selon la méthode d’expertise des caractéristiques psychologiques de la personnalité d’un manager. 15 experts ont évalué chaque caractéristique psychologique à l'aide d'un système en cinq points (voir tableau 4). Le psychologue s'intéresse à la question de la relation entre ces caractéristiques d'un leader.
Tableau 4. Résultats de l'étude
|
Sujets |
tact |
exigence |
criticité |
Le coefficient de corrélation reflète le degré de relation entre deux indicateurs. Il prend toujours une valeur comprise entre -1 et 1. Si le coefficient se situe autour de 0, alors il n'y a aucun lien entre les variables.
Si la valeur est proche de un (à partir de 0,9 par exemple), alors il existe une forte relation directe entre les objets observés. Si le coefficient est proche de l’autre point extrême de la plage (-1), alors il existe une forte relation inverse entre les variables. Lorsque la valeur se situe entre 0 et 1 ou entre 0 et -1, nous parlons alors d'une connexion faible (directe ou inversée). Cette relation n'est généralement pas prise en compte : on pense qu'elle n'existe pas.
Calcul du coefficient de corrélation dans Excel
Regardons un exemple de méthodes de calcul du coefficient de corrélation, des caractéristiques des relations directes et inverses entre les variables.
Valeurs des indicateurs x et y :
Y est une variable indépendante, x est une variable dépendante. Il faut trouver la force (forte/faible) et la direction (avant/inverse) de la connexion entre eux. La formule du coefficient de corrélation ressemble à ceci :

Pour faciliter la compréhension, décomposons-le en plusieurs éléments simples.


Une forte relation directe est déterminée entre les variables.
La fonction CORREL intégrée évite les calculs complexes. Calculons le coefficient de corrélation de paire dans Excel en l'utilisant. Appelez l'assistant de fonction. Nous trouvons le bon. Les arguments de la fonction sont un tableau de valeurs y et un tableau de valeurs x :

Montrons les valeurs des variables sur le graphique :

Un lien fort entre y et x est visible, car les lignes sont presque parallèles les unes aux autres. La relation est directe : y augmente - x augmente, y diminue - x diminue.
Matrice de coefficients de corrélation de paires dans Excel
La matrice de corrélation est un tableau à l'intersection de lignes et de colonnes dont se situent les coefficients de corrélation entre les valeurs correspondantes. Il est logique de le construire pour plusieurs variables.

La matrice des coefficients de corrélation dans Excel est construite à l'aide de l'outil « Corrélation » du package « Analyse des données ».


Une forte relation directe a été trouvée entre les valeurs de y et x1. Entre x1 et x2 il y a une forte Retour. Il n'y a pratiquement aucun lien avec les valeurs de la colonne x3.
Travail de laboratoire n°6. Tester l'hypothèse sur la distribution normale de l'échantillon à l'aide du critère de Pearson.
Le travail de laboratoire est effectué sous Excel 2007.
Le but du travail est de fournir des compétences en traitement de données primaires, en construction d'histogrammes, en sélectionnant une loi de distribution appropriée et en calculant ses paramètres, en vérifiant l'accord entre la loi de distribution empirique et hypothétique à l'aide du test du chi carré de Pearson à l'aide d'Excel.
1. Formation d'un échantillon de distribution normale nombres aléatoires avec des valeurs données d'espérance mathématique et d'écart type.
Données → Analyse des données → Génération de nombres aléatoires → OK.
Riz. 1. Boîte de dialogue L'analyse des données
Dans la fenêtre qui apparaît Génération de nombres aléatoires entrer:
Nombre de variables : 1 ;
Nombre de nombres aléatoires : 100 ;
Distribution: Normale.
Possibilités :
Moyenne = 15 (valeur attendue);
Écart type = 2 (écart-type);
Dispersion aléatoire : ne remplissez pas(ou à remplir selon les instructions du professeur);
Intervalle de sortie : adresse de la première cellule de la colonne du tableau de nombres aléatoires - $ UN$1 . D'ACCORD.

Riz. 2. Boîte de dialogue Génération de nombres aléatoires avec champs de saisie remplis
Suite à l'opération Génération de nombres aléatoires une colonne apparaîtra $ UN1 $ : 100 $ A$ contenant 100 nombres aléatoires.

Riz. 3. Fragment d'une feuille Excel des premiers nombres aléatoires $A$1 : $A$100.
2. Détermination des paramètres d'échantillonnage, statistiques descriptives
Dans le menu principal d'Excel, sélectionnez : Données → Analyse des données → Statistiques descriptives → OK.
Dans la fenêtre qui apparaît Statistiques descriptives entrer:
Intervalle de saisie– 100 nombres aléatoires dans les cellules $ UN$1: $ UN$100 ;
Regroupement- par colonnes ;
Intervalle de sortie– adresse de la cellule à partir de laquelle commence le tableau Statistiques descriptives - $C$1 ;
Statistiques récapitulatives- cocher. D'ACCORD.

Riz. 4. Boîte de dialogue Statistiques descriptives avec les champs de saisie complétés.
Un tableau apparaîtra sur la feuille Excel - Colonne 1

Riz. 5. Tableau Colonne 1 avec données de procédure Statistiques descriptives.
Le tableau contient des statistiques descriptives, notamment :
Moyenne– estimation de l'espérance mathématique ;
Écart-type– estimation de l'écart type ;
Excès Et Asymétrie– estimations d'aplatissement et d'asymétrie.
L'égalité approximative des estimations d'aplatissement et d'asymétrie à zéro, et l'égalité approximative de l'estimation moyenne avec l'estimation médiane donnent des bases préliminaires pour le choixH 0 La répartition des éléments de la population générale est une loi normale.
Intervalle– plage d'échantillonnage;
Le minimum – valeur minimum variable aléatoire dans l'échantillon ;
Maximum– la valeur maximale de la variable aléatoire dans l'échantillon.
Dans une cellule F15 - durée de l'intervalle partiel h, calculé comme suit :
Nombre d'intervalles de regroupement k dans Excel, il est calculé automatiquement à l'aide de la formule
où les parenthèses signifient arrondir à la partie entière du nombre.
Dans la variante considérée n = 100 , ainsi, k = 11 . Vraiment:

Cette formule est inscrite dans la cellule F15: =($D$13-$D$12)/10
Résultats de la procédure Statistiques descriptives sera nécessaire plus tard lors de la construction d’une loi de distribution théorique.