Bonjour les amis.
Vous avez sûrement déjà oublié le goût de mes articles. Le matériel précédent datait d'il y a assez longtemps, même si j'avais promis de publier des articles plus souvent que d'habitude.
DANS Dernièrement la quantité de travail a augmenté. Création d'un nouveau projet (site d'information), travail sur sa mise en page, sa conception, collecte noyau sémantique et a commencé à publier du matériel.
Aujourd'hui, il y aura du matériel très volumineux et important pour ceux qui exploitent leur site Web depuis plus de 6 à 7 mois (dans certains sujets depuis plus d'un an) un grand nombre de articles (100 en moyenne) et n'a pas encore atteint le niveau minimum de 500-1000 visites par jour. Les chiffres sont réduits au minimum.
L'importance du noyau sémantique
Dans certains cas, une mauvaise croissance du site Web est causée par une mauvaise optimisation technique du site Web. Plus de cas où le contenu est de mauvaise qualité. Mais il y a encore plus de cas où les textes ne sont pas du tout rédigés conformément aux demandes - personne n'a besoin du matériel. Mais il y a aussi une très grande partie des personnes qui créent un site Web, optimisent tout correctement, rédigent des textes de haute qualité, mais après 5 à 6 mois, le site ne commence à attirer que les 20 à 30 premiers visiteurs issus de la recherche. A un rythme lent, au bout d'un an, il y a déjà 100 à 200 visiteurs et le chiffre des revenus est nul.
Et bien que tout ait été fait correctement, il n'y a pas d'erreurs, et les textes sont parfois même plusieurs fois de meilleure qualité que ceux des concurrents, mais d'une manière ou d'une autre, cela ne fonctionne pas, pour ma vie. Nous commençons à attribuer ce problème au manque de liens. Bien sûr, les liens stimulent le développement, mais ce n’est pas le plus important. Et sans eux, vous pouvez avoir 1000 visites sur le site en 3-4 mois.
Beaucoup diront que ce ne sont que des bavardages inutiles et que vous n’obtiendrez pas de tels chiffres si rapidement. Mais si l’on y regarde de plus près, de tels chiffres ne sont pas précisément atteints sur les blogs. Les sites d'information (pas les blogs), créés pour des revenus et un retour sur investissement rapides, après environ 3-4 mois, il est tout à fait possible d'atteindre un trafic quotidien de 1 000 personnes, et après un an de 5 000 à 10 000. Les chiffres dépendent bien entendu de la compétitivité de la niche, de son volume et du volume du site lui-même pour la période spécifiée. Mais si vous prenez un créneau avec assez peu de concurrence et un volume de 300 à 500 matériaux, de tels chiffres dans les délais impartis sont tout à fait réalisables.
Pourquoi exactement les blogs n’obtiennent-ils pas des résultats aussi rapides ? La principale raison est le manque de noyau sémantique. De ce fait, les articles sont rédigés pour une seule demande spécifique et presque toujours pour une demande très compétitive, ce qui empêche la page d'atteindre le TOP en peu de temps.
Sur les blogs, en règle générale, les articles sont rédigés à l'effigie des concurrents. Nous avons 2 blogs lisibles. On voit qu'ils ont un trafic décent, on commence à analyser leur plan de site et à publier des textes pour les mêmes requêtes, qui ont déjà été réécrites des centaines de fois et sont très compétitives. En conséquence, nous obtenons un contenu de très haute qualité sur le site, mais il est peu performant dans les recherches, car... demande beaucoup d'âge. Nous nous demandons pourquoi mon contenu est le meilleur, mais n’atteint pas le TOP ?
C'est pourquoi j'ai décidé d'écrire des documents détaillés sur le noyau sémantique du site, afin que vous puissiez collecter une liste de requêtes et, ce qui est très important, rédiger des textes pour de tels groupes. mots clés, qui sans acheter de liens et en seulement 2-3 mois a atteint le TOP (bien sûr, si le contenu est de haute qualité).
Le matériel sera difficile pour la plupart si vous n’avez jamais rencontré ce problème de la manière correcte. Mais l’essentiel ici est de commencer. Dès que vous commencez à jouer, tout devient immédiatement clair.
Permettez-moi de faire une remarque très importante. Cela concerne ceux qui ne sont pas prêts à investir dans la qualité avec leurs pièces durement gagnées et qui essaient toujours de trouver des failles gratuites. Vous ne pouvez pas collecter gratuitement une sémantique de haute qualité, et c’est fait connu. Par conséquent, dans cet article, je décris le processus de collecte d'une sémantique de qualité maximale. Aucun moyens gratuits sinon il n'y aura pas de failles dans ce post ! Il faudra nécessairement nouveau poste, où je vous parlerai d'outils gratuits et autres avec lesquels vous pouvez collecter de la sémantique, mais pas dans son intégralité et sans la bonne qualité. Par conséquent, si vous n’êtes pas prêt à investir dans les bases de votre site Web, alors ce materiel tu n'as besoin de rien !
Malgré le fait que presque tous les blogueurs écrivent un article à ce sujet. noyau, je peux dire avec certitude qu'il n'existe pas de didacticiels gratuits normaux sur Internet sur ce sujet. Et si c’est le cas, alors personne ne pourrait donner une image complète de ce que devrait être le résultat.
Le plus souvent, la situation se termine par l'écriture de matériel pour débutants et par la collecte du noyau sémantique, ainsi que par l'utilisation d'un service de collecte de statistiques sur les requêtes de recherche de Yandex (wordstat.yandex.ru). En fin de compte, vous devez vous rendre sur ce site, saisir des requêtes sur votre sujet, le service affichera une liste de phrases incluses dans votre clé saisie - c'est toute la technique.
Mais en fait, ce n’est pas ainsi que le noyau sémantique est assemblé. Dans le cas décrit ci-dessus, vous n'aurez tout simplement pas de noyau sémantique. Vous recevrez des demandes déconnectées et elles porteront toutes sur la même chose. Par exemple, prenons ma niche « création de sites Web ».
Quelles sont les principales requêtes que l’on peut citer sans hésiter ? En voici quelques-uns :
- Comment créer un site internet;
- Promotion de sites Web ;
- Création de site web;
- Promotion du site Web, etc.
Les demandes sont à peu près la même chose. Leur signification se résume à seulement deux concepts : la création et la promotion d’un site internet.
Après une telle vérification, le service wordstat affichera de nombreuses requêtes de recherche incluses dans les requêtes principales et elles porteront également sur la même chose. Leur seule différence résidera dans les formes de mots modifiées (ajout de quelques mots et modification de la disposition des mots dans la requête avec changement des terminaisons).
Certainement, une certaine quantité de Il sera possible d'écrire des textes, puisque les demandes peuvent être différentes même dans cette version. Par exemple:
- Comment créer un site WordPress ;
- Comment créer un site Web Joomla ;
- Comment créer un site internet sur un hébergement gratuit ;
- Comment promouvoir un site Web gratuitement ;
- Comment promouvoir un site Web de service, etc.
Bien entendu, du matériel distinct peut être attribué à chaque demande. Mais une telle compilation du noyau sémantique du site ne réussira pas, car il n'y aura pas de divulgation complète des informations sur le site dans la niche sélectionnée. Tout le contenu portera sur seulement 2 sujets.
Parfois, les blogueurs débutants décrivent le processus de compilation d'un noyau sémantique comme l'analyse de requêtes individuelles dans le service d'analyse de requêtes Yandex Wordstat. Nous saisissons une requête distincte qui ne concerne pas le sujet dans son ensemble, mais uniquement un article spécifique (par exemple, comment optimiser un article), nous obtenons sa fréquence, et la voici - le noyau sémantique est assemblé . Il s'avère que de cette manière, nous devons identifier mentalement tous les sujets d'articles possibles et les analyser.
Les deux options ci-dessus sont incorrectes, car... ne fournissent pas un noyau sémantique complet et vous obligent à revenir constamment à sa compilation (deuxième option). De plus, vous n'aurez pas entre vos mains le vecteur de développement du site et ne pourrez pas en premier lieu publier des documents qui devraient être publiés parmi les premiers.
Concernant la première option, lorsque j'ai acheté une fois des cours sur la promotion de sites Web, j'ai constamment vu exactement cette explication pour collecter le noyau des requêtes pour un site Web (saisir les clés principales et copier toutes les requêtes du service dans un document texte). En conséquence, j'étais constamment tourmenté par la question « Que faire de telles demandes ? Ce qui suit m'est venu à l'esprit :
- Écrivez de nombreux articles sur la même chose, mais en utilisant des mots-clés différents ;
- Saisissez toutes ces clés dans le champ de description de chaque matériau ;
- Entrez toutes les clés de la famille. noyaux dans le champ de description générale de l’ensemble de la ressource.
Aucune de ces hypothèses n’était correcte, pas plus que, en général, le noyau sémantique du site lui-même.
Dans la version finale de la collecte du noyau sémantique, nous devrions recevoir non seulement une liste de requêtes d'un montant de 10 000, par exemple, mais avoir en main une liste de groupes de requêtes, dont chacun est utilisé pour un article distinct.
Un groupe peut contenir de 1 à 20-30 requêtes (parfois 50 voire plus). Dans ce cas, nous utilisons toutes ces requêtes dans le texte, et à l'avenir, la page générera du trafic pour toutes les requêtes chaque jour si elle atteint 1 à 3 positions dans la recherche. De plus, chaque groupe doit organiser son propre concours afin de savoir s'il est judicieux de publier un texte à ce sujet maintenant ou non. S'il y a beaucoup de concurrence, nous ne pouvons nous attendre à l'effet de la page qu'après 1 à 1,5 ans et avec un travail régulier pour la promouvoir (liens, liens, etc.). Par conséquent, il est préférable de se concentrer sur ces textes en dernier recours, même s'ils ont le plus de trafic.
Réponses aux questions possibles
Question n°1. Il est clair que le résultat est un groupe de requêtes pour écrire du texte, et pas seulement une clé. Dans ce cas, les clés ne seraient-elles pas similaires les unes aux autres et pourquoi ne pas écrire un texte distinct pour chaque demande ?
Question n°2. On sait que chaque page doit être adaptée à un seul mot-clé, mais on obtient ici un groupe entier et, dans certains cas, avec un contenu de requêtes assez important. Comment, dans ce cas, se produit l'optimisation du texte lui-même ? Après tout, s'il y a, par exemple, 20 clés, alors l'utilisation de chacune au moins une fois dans le texte (même grande taille) ressemble déjà à du texte destiné à un moteur de recherche, pas à des personnes.
Répondre. Si nous prenons l'exemple des demandes de la question précédente, alors la première chose à faire pour affiner le matériel sera précisément la demande la plus fréquente (1ère), puisque nous sommes plus intéressés à ce qu'elle atteigne les premières positions. Nous considérons ce mot-clé comme le principal de ce groupe.
L'optimisation de la phrase clé principale se produit de la même manière que lors de l'écriture de texte pour une seule clé (la clé dans l'en-tête du titre, en utilisant le nombre requis de caractères dans le texte et le nombre requis de fois la clé elle-même, si nécessaire).
Concernant les autres clés, nous les saisissons également, mais pas aveuglément, mais sur la base d'une analyse des concurrents, qui peut montrer le nombre moyen de ces clés dans les textes du TOP. Il se peut que pour la plupart des mots-clés, vous obteniez valeurs nulles, ce qui signifie qu'ils ne nécessitent pas d'utilisation dans des occurrences exactes.
Ainsi, le texte est écrit en utilisant uniquement la requête principale directement dans le texte. Bien entendu, d’autres requêtes peuvent également être utilisées si l’analyse des concurrents montre leur présence dans les textes du TOP. Mais il ne s’agit pas de 20 mots-clés dans le texte dans leur occurrence exacte.
Plus récemment, j'ai publié du matériel pour un groupe de 11 clés. Il semble qu'il y ait beaucoup de requêtes, mais dans la capture d'écran ci-dessous, vous pouvez voir que seule la clé principale la plus fréquente a une occurrence exacte - 6 fois. Les phrases clés restantes n'ont pas d'occurrences exactes, mais aussi des occurrences diluées (non visibles sur la capture d'écran, mais cela se voit lors de l'analyse des concurrents). Ceux. ils ne sont pas du tout utilisés.
(1ère colonne – fréquence, 2ème – compétitivité, 3ème – nombre d'impressions)
Dans la plupart des cas, il y aura une situation similaire, où seules quelques touches doivent être utilisées dans une occurrence exacte, et tout le reste sera soit fortement dilué, soit pas utilisé du tout, même dans une occurrence diluée. L'article s'avère lisible et il n'y a aucune indication de se concentrer uniquement sur la recherche.
Question n°3. Cela découle de la réponse à la question n°2. Si les clés restantes du groupe n’ont pas du tout besoin d’être utilisées, comment recevront-elles le trafic ?
Répondre. Le fait est que grâce à la présence de certains mots dans le texte, un moteur de recherche peut déterminer de quoi parle le texte. Étant donné que les mots-clés contiennent certains mots individuels qui se rapportent uniquement à cette clé, ils doivent être utilisés dans le texte un certain nombre de fois sur la base de la même analyse des concurrents.
Ainsi, la clé ne sera pas utilisée dans l'entrée exacte, mais les mots de la clé seront présents individuellement dans le texte et participeront également au classement. De ce fait, pour ces requêtes, le texte sera également retrouvé dans la recherche. Mais dans ce cas, le nombre de mots individuels devrait idéalement être respecté. Les concurrents aideront.
J'ai répondu aux principales questions qui pourraient vous plonger dans la stupeur. J'écrirai davantage sur la façon d'optimiser le texte pour les groupes de demandes dans l'un des documents suivants. Il y aura des informations sur l'analyse des concurrents et sur la rédaction du texte lui-même pour un groupe de clés.
Eh bien, si vous avez encore des questions, posez vos commentaires. Je répondrai à tout.
Commençons maintenant à compiler le noyau sémantique du site.
Très important. Je ne pourrai pas décrire l'ensemble du processus tel qu'il est réellement dans cet article (je devrai faire un webinaire complet de 2-3 heures ou un mini-cours), donc je vais essayer d'être bref, mais à la fois informatif et abordant le plus de points possible. Par exemple, je ne décrirai pas en détail la configuration du logiciel KeyCollector. Tout sera raccourci, mais aussi clair que possible.
Passons maintenant en revue chaque point. Commençons. Tout d’abord, la préparation.
Que faut-il pour collecter un noyau sémantique ?

Avant de créer le noyau sémantique du site, nous mettrons en place un collecteur de clés pour collecter correctement les statistiques et analyser les requêtes.
Configuration de KeyCollector
Vous pouvez saisir les paramètres en cliquant sur l'icône dans le menu supérieur du logiciel.

Tout d’abord, qu’est-ce qui concerne l’analyse.
Je voudrais noter les paramètres « Nombre de flux » et « Utiliser l'adresse IP principale ». Le nombre de fils pour assembler un petit noyau ne nécessite pas un grand nombre. 2 à 4 fils suffisent. Plus il y a de threads, plus il faut de serveurs proxy. Idéalement, 1 proxy pour 1 thread. Mais vous pouvez aussi avoir 1 proxy pour 2 flux (c'est ainsi que je l'ai analysé).
Concernant le deuxième paramètre, en cas d'analyse en 1-2 threads, vous pouvez utiliser votre adresse IP principale. Mais seulement si c'est dynamique, parce que... Si un entrepreneur individuel statique est banni, vous perdrez l'accès au moteur de recherche Yandex. Mais néanmoins, la priorité est toujours donnée à l'utilisation d'un serveur proxy, car il vaut mieux se protéger.
Dans l'onglet des paramètres d'analyse Yandex.Direct, il est important d'ajouter vos comptes Yandex. Plus il y en a, mieux c'est. Vous pouvez les enregistrer vous-même ou les acheter, comme je l'ai écrit plus tôt. Je les ai achetés parce que c'est plus facile pour moi de dépenser 100 roubles pour 30 comptes.
Vous pouvez l'ajouter depuis le tampon en copiant au préalable la liste des comptes au format souhaité, ou en la chargeant à partir d'un fichier.
Les comptes doivent être spécifiés au format « login:mot de passe », sans spécifier l'hôte lui-même dans le login (sans @yandex.ru). Par exemple, « artem_konovalov:jk8ergvgkhtf ».
De plus, si nous utilisons plusieurs serveurs proxy, il est préférable de les attribuer à des comptes spécifiques. Il serait suspect qu'au début la demande provienne d'un serveur et d'un compte, et que la prochaine fois qu'une demande soit faite à partir du même compte Yandex, le serveur proxy soit différent.
À côté des comptes se trouve une colonne « Proxy IP ». À côté de chaque compte, nous entrons un proxy spécifique. S'il y a 20 comptes et 2 serveurs proxy, alors il y aura 10 comptes avec un proxy et 10 avec un autre. S'il y a 30 comptes, alors 15 avec un serveur et 15 avec un autre. Je pense que vous comprenez la logique.
Si nous n’utilisons qu’un seul proxy, cela ne sert à rien de l’ajouter à chaque compte.
J'ai parlé un peu plus tôt du nombre de threads et de l'utilisation de l'adresse IP principale.
L'onglet suivant est "Réseau", où vous devez saisir les serveurs proxy qui seront utilisés pour l'analyse.
Vous devez saisir un proxy tout en bas de l'onglet. Vous pouvez les charger depuis le tampon dans le format souhaité. Je l'ai ajouté de manière simple. Dans chaque colonne de la ligne, j'ai saisi les informations sur le serveur qui vous sont fournies lors de votre achat.
Ensuite, nous configurons les paramètres d'exportation. Puisque nous devons recevoir toutes les requêtes avec leurs fréquences dans un fichier sur l'ordinateur, nous devons définir certains paramètres d'exportation afin qu'il n'y ait rien de superflu dans le tableau.
Tout en bas de l'onglet (surligné en rouge), vous devez sélectionner les données que vous souhaitez exporter vers le tableau :
- Phrase;
- Source;
- Fréquence "!" ;
- Meilleure forme phrases (vous n’êtes pas obligé de les mettre).
Il ne reste plus qu'à configurer la solution anti-captcha. L'onglet s'appelle « Antikapcha ». Sélectionnez le service que vous utilisez et entrez la clé spéciale qui se trouve dans le compte de service.
Une clé spéciale pour travailler avec le service est fournie dans une lettre après l'enregistrement, mais elle peut également être extraite du compte lui-même dans l'élément « Paramètres - paramètres du compte ».
Ceci termine les paramètres de KeyCollector. Après avoir effectué les modifications, n'oubliez pas de sauvegarder les paramètres en cliquant sur le gros bouton en bas « Enregistrer les modifications ».
Lorsque tout est fait et que nous sommes prêts à analyser, nous pouvons commencer à considérer les étapes de collecte du noyau sémantique, puis parcourir chaque étape dans l'ordre.
Étapes de collecte du noyau sémantique
Il est impossible d’obtenir un noyau sémantique complet et de qualité en utilisant uniquement des requêtes de base. Vous devez également analyser les demandes et les matériaux des concurrents. Par conséquent, l’ensemble du processus de compilation du noyau se compose de plusieurs étapes, elles-mêmes divisées en sous-étapes.
- La base;
- Analyse de la concurrence;
- Extension liste prête des étapes 1 à 2 ;
- Collection des meilleures formes de mots pour les requêtes des étapes 1 à 3.
Étape 1 – fondation
Lors de la collecte du noyau à ce stade, vous devez :
- Générer une liste principale de demandes dans le créneau ;
- Expansion de ces requêtes ;
- Nettoyage.
Étape 2 – concurrents
En principe, l'étape 1 fournit déjà un certain volume de noyau, mais pas entièrement, car il nous manque peut-être quelque chose. Et les concurrents de notre niche nous aideront à trouver les trous manquants. Voici les étapes à suivre :
- Collecte des concurrents en fonction des demandes de l'étape 1 ;
- Analyser les requêtes des concurrents (analyse du plan du site, statistiques open liveinternet, analyse des domaines et des concurrents dans SpyWords) ;
- Nettoyage.
Étape 3 – expansion
Beaucoup de gens s’arrêtent dès la première étape. Quelqu'un arrive au 2ème, mais il existe un certain nombre de requêtes supplémentaires qui peuvent également compléter le noyau sémantique.
- Nous combinons les demandes des étapes 1 et 2 ;
- Nous laissons 10% des mots les plus fréquents de la liste entière, qui contiennent au moins 2 mots. Il est important que ces 10 % ne dépassent pas 100 phrases, car un grand nombre vous obligera à approfondir le processus de collecte, de nettoyage et de regroupement. Nous devons assembler le noyau dans un rapport vitesse/qualité (perte de qualité minimale à vitesse maximale) ;
- Nous étendons ces requêtes en utilisant le service Rookee (tout est dans KeyCollector) ;
- Nettoyage.
Étape 4 – collecter les meilleures formes de mots
Le service Rookee peut déterminer la meilleure forme de mot (correcte) pour la plupart des requêtes. Cela devrait également être utilisé. Le but n'est pas de déterminer le mot le plus correct, mais de trouver d'autres requêtes et leurs formes. De cette façon, vous pouvez générer un autre pool de requêtes et les utiliser lors de la rédaction de textes.
- Regrouper les demandes des 3 premières étapes ;
- Collection des meilleures formes de mots basées sur celles-ci ;
- Ajout des meilleures formes de mots à la liste pour toutes les requêtes combinées des étapes 1 à 3 ;
- Nettoyage;
- Exportez la liste terminée dans un fichier.
Comme vous pouvez le constater, tout n’est pas si rapide, et surtout pas si simple. Je n'ai décrit qu'un plan normal pour compiler un noyau afin d'obtenir une liste de clés de haute qualité en sortie et de ne rien perdre ou d'en perdre le moins possible.
Je propose maintenant de parcourir chaque point séparément et de tout étudier de A à Z. Il y a beaucoup d'informations, mais cela en vaut la peine si vous avez besoin d'un noyau sémantique de très haute qualité pour le site.
Étape 1 – fondation
Tout d’abord, nous créons une liste de requêtes de niche de base. En règle générale, il s’agit d’expressions de 1 à 3 mots qui décrivent un problème de niche spécifique. A titre d'exemple, je propose de prendre la niche « Médecine », et plus précisément la sous-niche des maladies cardiaques.
Quelles principales demandes pouvons-nous identifier ? Bien sûr, je n’écrirai pas tout, mais j’en donnerai quelques-uns.
- Maladies cardiaques
- Crise cardiaque;
- Ischémie cardiaque ;
- Arythmie ;
- Hypertension;
- Maladie cardiaque;
- Angine, etc.
En termes simples, ce sont des noms courants pour désigner des maladies. Il peut y avoir beaucoup de demandes de ce type. Plus vous pouvez en faire, mieux c'est. Mais vous ne devriez pas y entrer pour le spectacle. Cela n'a aucun sens d'écrire des phrases plus spécifiques à partir des phrases générales, par exemple :
- Arythmie ;
- L'arythmie provoque ;
- Traitement de l'arythmie ;
- Symptômes d'arythmie.
L'essentiel n'est que la première phrase. Cela ne sert à rien d'indiquer le reste, car... ils apparaîtront dans la liste lors de l'expansion en utilisant l'analyse de la colonne de gauche de Yandex Wordstat.
Pour rechercher des expressions courantes, vous pouvez utiliser à la fois les sites concurrents (plan du site, noms de rubriques...) et l'expérience d'un spécialiste de ce créneau.

L'analyse prendra un certain temps, en fonction du nombre de requêtes dans le créneau. Toutes les demandes sont par défaut placées dans un nouveau groupe appelé "Nouveau groupe 1", si ma mémoire est bonne. Je renomme généralement les groupes pour comprendre lequel est responsable de quoi. Le menu de gestion des groupes est situé à droite de la liste des demandes.
La fonction Renommer se trouve dans le menu contextuel lorsque vous cliquez avec le bouton droit. Ce menu sera également nécessaire pour créer d'autres groupes dans les deuxième, troisième et quatrième étapes.
Par conséquent, vous pouvez immédiatement ajouter 3 groupes supplémentaires en cliquant sur la première icône « + » afin que le groupe soit créé dans la liste immédiatement après le précédent. Il n'est pas encore nécessaire d'y ajouter quoi que ce soit. Laissez-les tranquilles.
J'ai nommé les groupes comme ceci :
- Concurrents - il est clair que ce groupe contient une liste de demandes que j'ai collectées auprès des concurrents ;
- 1-2 est une liste combinée de requêtes des 1ère (liste principale des requêtes) et 2ème (requêtes des concurrents), afin de ne laisser que 10 % des requêtes composées d'au moins 2 mots et d'en collecter des extensions ;
- 1-3 – liste combinée des demandes des première, deuxième et troisième étapes (prolongations). Nous collectons également les meilleures formes de mots de ce groupe, bien qu'il serait plus judicieux de les rassembler dans un nouveau groupe (par exemple, les meilleures formes de mots), puis, après les avoir nettoyés, de les déplacer vers le groupe 1-3.
Après avoir terminé l'analyse de Yandex.wordstat, vous recevez une grande liste d'expressions clés qui, en règle générale (si la niche est petite), se situeront dans plusieurs milliers. Une grande partie de ces demandes sont des déchets et des demandes factices et devront être nettoyées. Certaines choses seront automatiquement triées à l'aide de la fonctionnalité KeyCollector, tandis que d'autres devront être pelletées à la main et assises pendant un moment.
Lorsque toutes les demandes sont collectées, vous devez collecter leurs fréquences exactes. La fréquence globale est collectée lors de l'analyse, mais la fréquence exacte doit être collectée séparément.
Pour collecter des statistiques sur le nombre d'impressions, vous pouvez utiliser deux fonctions :
- Avec l'aide de Yandex Direct - les statistiques sont rapidement collectées par lots, mais il existe des limites (par exemple, les phrases de plus de 7 mots ne fonctionneront pas, même avec des symboles) ;
- Utilisation de l'analyse dans Yandex Wordstat - très lentement, les phrases sont analysées une par une, mais il n'y a aucune restriction.
Tout d'abord, collectez des statistiques à l'aide de Direct, afin que cela soit le plus rapide possible, et pour les phrases pour lesquelles il n'a pas été possible de déterminer des statistiques à l'aide de Direct, nous utilisons Wordstat. En règle générale, il restera peu de phrases de ce type et elles seront collectées rapidement.
Les statistiques d'impression sont collectées à l'aide de Yandex.Direct en cliquant sur le bouton approprié et en attribuant les paramètres nécessaires.
Après avoir cliqué sur le bouton « Obtenir des données », un avertissement peut s'afficher indiquant que Yandex Direct n'est pas activé dans les paramètres. Vous devrez accepter d'activer l'analyse à l'aide de Direct afin de commencer à déterminer les statistiques de fréquence.
Vous verrez immédiatement comment se déroulent les packs dans la colonne « Fréquence » ! » des indicateurs d'impression précis pour chaque phrase commenceront à être enregistrés.
Le processus de réalisation d'une tâche peut être vu dans l'onglet « Statistiques » tout en bas du programme. Lorsque la tâche est terminée, vous verrez une notification d'achèvement sur l'onglet Journal des événements et la barre de progression de l'onglet Statistiques disparaîtra.
Après avoir collecté le nombre d'impressions à l'aide de Yandex Direct, nous vérifions s'il existe des phrases pour lesquelles la fréquence n'a pas été collectée. Pour cela, triez la colonne « Fréquence ! » (cliquez dessus) pour que les valeurs les plus petites ou les plus grandes apparaissent en haut.
Si tous les zéros sont en haut, alors toutes les fréquences sont collectées. S'il y a des cellules vides, cela signifie que les impressions pour ces phrases n'ont pas été déterminées. La même chose s'applique lors du tri par kill, alors seulement vous devrez regarder le résultat tout en bas de la liste des requêtes.
Vous pouvez également commencer à collecter à l'aide de Yandex Wordstat en cliquant sur l'icône et en sélectionnant le paramètre de fréquence requis.

Après avoir sélectionné le type de fréquence, vous verrez comment les cellules vides commencent progressivement à se remplir.
Important : ne vous inquiétez pas s'il reste des cellules vides après la fin de la procédure. Le fait est qu'ils seront vides si leur fréquence exacte est inférieure à 30. Nous définissons cela dans les paramètres d'analyse de Keycollector. Ces phrases peuvent être mises en évidence en toute sécurité (ainsi que fichiers réguliers dans l'Explorateur Windows) et supprimez-le. Les phrases seront surlignées en bleu, faites un clic droit et sélectionnez « Supprimer les lignes sélectionnées ».
Lorsque toutes les statistiques ont été collectées, vous pouvez commencer le nettoyage, ce qui est très important à faire à chaque étape de la collecte du noyau sémantique.
La tâche principale est de supprimer les phrases qui ne sont pas liées au sujet, de supprimer les phrases avec des mots vides et de se débarrasser des requêtes trop faibles en fréquence.
Idéalement, ce dernier n'est pas nécessaire, mais si nous sommes en train de le compiler. noyaux pour utiliser des phrases même avec une fréquence minimale de 5 impressions par mois, cela augmentera le noyau de 50 à 60 pour cent (ou peut-être même 80 %) et nous obligera à creuser profondément. Nous devons obtenir vitesse maximum avec des pertes minimes.
Si nous voulons obtenir le noyau sémantique le plus complet du site, mais en même temps le collecter pendant environ un mois (nous n'avons aucune expérience du tout), alors prenons des fréquences de 4 à 5 impressions mensuelles. Mais il est préférable (si vous êtes débutant) de laisser des demandes comportant au moins 30 impressions par mois. Oui, nous allons perdre un peu, mais c'est le prix à payer pour une vitesse maximale. Et au fur et à mesure que le projet grandit, il sera possible de recevoir à nouveau ces demandes et de les utiliser pour rédiger de nouveaux documents. Et ce n'est qu'à la condition que tout cela. le noyau a déjà été rédigé et il n'y a pas de sujets d'articles.
Le même collecteur de clés vous permet de filtrer les demandes par nombre d'impressions et d'autres paramètres de manière entièrement automatique. Au départ, je recommande de faire exactement cela, et de ne pas supprimer les phrases inutiles et les phrases avec des mots vides, car... il sera beaucoup plus facile de le faire lorsque le volume central total à ce stade deviendra minime. Qu'est-ce qui est plus simple, pelleter 10 000 phrases ou 2 000 ?
Les filtres sont accessibles à partir de l'onglet Données en cliquant sur le bouton Modifier les filtres.

Je recommande d'afficher d'abord toutes les requêtes dont la fréquence est inférieure à 30 et de les déplacer vers un nouveau groupe afin de ne pas les supprimer, car elles pourraient être utiles à l'avenir. Si nous appliquons simplement un filtre pour afficher des phrases avec une fréquence supérieure à 30, alors après le prochain lancement de KeyCollector, nous devrons réappliquer le même filtre, puisque tout est réinitialisé. Bien sûr, vous pouvez enregistrer le filtre, mais vous devrez quand même l'appliquer en revenant constamment à l'onglet « Données ».
Pour nous épargner ces actions, nous ajoutons une condition dans l'éditeur de filtres afin que seules les phrases dont la fréquence est inférieure à 30 soient affichées.



À l'avenir, vous pourrez sélectionner un filtre en cliquant sur la flèche à côté de l'icône de la disquette.
Ainsi, après application du filtre, seules les phrases avec une fréquence inférieure à 30 resteront dans la liste des requêtes, c'est-à-dire 29 et moins. De plus, la colonne filtrée sera surlignée en couleur. Dans l'exemple ci-dessous, vous ne verrez qu'une fréquence de 30, car... Je montre tout cela en utilisant l'exemple d'un noyau déjà prêt et tout est nettoyé. N'y prêtez aucune attention. Tout devrait être comme je le décris dans le texte.

Pour transférer, vous devez sélectionner toutes les phrases de la liste. Cliquez sur la première phrase, faites défiler jusqu'en bas de la liste, maintenez la touche « Shift » enfoncée et cliquez une fois sur la dernière phrase. De cette façon, toutes les phrases sont mises en évidence et marquées d’un fond bleu.
apparaîtra petite fenêtre, où vous devez sélectionner exactement le mouvement.
Vous pouvez désormais supprimer le filtre de la colonne de fréquence afin qu'il ne reste que les requêtes avec une fréquence de 30 et plus.

Nous avons franchi une certaine étape de nettoyage automatique. Ensuite, vous devrez bricoler la suppression des phrases inutiles.
Tout d’abord, je suggère de spécifier des mots vides pour supprimer toutes les phrases les contenant. Idéalement, bien sûr, cela se fait immédiatement au stade de l'analyse afin qu'ils ne se retrouvent pas dans la liste, mais ce n'est pas critique, car la suppression des mots vides se fait automatiquement à l'aide de KeyCollector.
La principale difficulté est de dresser une liste de mots vides, car... Ils sont différents pour chaque sujet. Par conséquent, que nous ayons nettoyé les mots vides au début ou maintenant n'est pas si important, car nous devons trouver tous les mots vides, ce qui est une tâche laborieuse et pas si rapide.
Sur Internet, vous pouvez trouver des listes thématiques générales, qui incluent les mots les plus courants comme « abstrait, gratuit, téléchargement, p...rn, en ligne, image, etc. ».
Tout d’abord, je suggère d’utiliser une liste de sujets généraux pour réduire davantage le nombre de phrases. Dans l'onglet « Collecte de données », cliquez sur le bouton « Mots vides » et ajoutez-les dans une liste.
Dans la même fenêtre, cliquez sur le bouton « Marquer les phrases dans le tableau » pour marquer toutes les phrases contenant les mots vides saisis. Mais il est nécessaire que toute la liste des phrases du groupe soit décochée, afin qu'après avoir cliqué sur le bouton, seules les phrases avec des mots vides restent marquées. Il est très simple de décocher toutes les phrases.

Lorsqu'il ne reste que des phrases marquées avec des mots vides, nous les supprimons ou les déplaçons vers un nouveau groupe. Je l'ai supprimé pour la première fois, mais c'est toujours une priorité de créer un groupe « Avec des mots vides » et d'y déplacer toutes les phrases inutiles.
Après le nettoyage, il y avait encore moins de phrases. Mais ce n'est pas tout, car... il nous a encore manqué quelque chose. Tant les mots vides eux-mêmes que les expressions qui ne sont pas liées à l’objet de notre site. Il peut s’agir de demandes commerciales pour lesquelles les textes ne peuvent pas être écrits, ou bien des textes peuvent être écrits, mais ils ne répondront pas aux attentes de l’utilisateur.
Des exemples de telles requêtes peuvent être liés au mot « acheter ». Sûrement, lorsqu'un utilisateur recherche quelque chose avec ce mot, il souhaite déjà accéder au site où il le vend. Nous écrirons du texte pour une telle phrase, mais le visiteur n'en aura pas besoin. Nous n’avons donc pas besoin de telles demandes. Nous les recherchons manuellement.
Nous parcourons lentement et soigneusement la liste restante des requêtes jusqu'à la toute fin, recherchant de telles expressions et découvrant de nouveaux mots vides. Si vous trouvez un mot qui est utilisé plusieurs fois, ajoutez-le simplement au mot déjà utilisé. liste existante mots vides et cliquez sur le bouton « Marquer les phrases dans le tableau ». A la fin de la liste, lorsque nous avons marqué toutes les requêtes inutiles lors de la vérification manuelle, nous supprimons les phrases marquées et la première étape de compilation du noyau sémantique est terminée.
Nous avons obtenu un certain noyau sémantique. Il n'est pas encore tout à fait complet, mais il permettra déjà de rédiger le maximum de textes possibles.
Il ne reste plus qu'à y ajouter une petite partie des demandes qui auraient pu nous échapper. Les étapes suivantes vous y aideront.
Étape 2 – concurrents
Au tout début, nous avons dressé une liste d’expressions courantes liées au créneau. Dans notre cas, il s'agissait de :
- Maladies cardiaques
- Crise cardiaque;
- Ischémie cardiaque ;
- Arythmie ;
- Hypertension;
- Maladie cardiaque;
- Angine, etc.
Tous appartiennent spécifiquement au créneau « Maladies cardiaques ». En utilisant ces expressions, vous devez rechercher des sites concurrents sur ce sujet.
Nous saisissons chacune des phrases et recherchons des concurrents. Il est important qu'il ne s'agisse pas de sites thématiques généraux (dans notre cas, des sites médicaux à vocation générale, c'est-à-dire sur toutes les maladies). Ce qu’il faut, ce sont des projets de niche. Dans notre cas, il s'agit uniquement du cœur. Eh bien, peut-être aussi à propos des navires, parce que... le cœur est relié au système vasculaire. Je pense que vous voyez l'idée.
Si notre niche est « Recettes de salades à la viande », alors à l'avenir, ce sont les seuls sites que nous devrions rechercher. S'ils ne sont pas là, essayez de trouver des sites uniquement sur les recettes, et pas en général sur la cuisine, où tout est sur tout.
S'il existe un site thématique général (médecine générale, féminine, sur tous types de construction et de réparation, cuisine, sport), alors vous devrez beaucoup souffrir, tant au niveau de la constitution du noyau sémantique lui-même, car vous devrez travailler longtemps et fastidieusement - collecter la liste principale des demandes, attendre longtemps le processus d'analyse, nettoyer et regrouper.
Si sur la 1ère, et parfois même sur la 2ème page, vous ne trouvez pas de sites thématiques étroits de concurrents, alors essayez d'utiliser non pas les requêtes principales que nous avons générées avant l'analyse elle-même à la 1ère étape, mais les requêtes de la liste entière après analyse. Par exemple:
- Comment traiter l'arythmie avec des remèdes populaires ;
- Symptômes d'arythmie chez les femmes, etc.
Le fait est que de telles requêtes (arythmie, maladie cardiaque, maladie cardiaque...) sont très compétitives et il est presque impossible d'atteindre le TOP pour elles. Ainsi, dans les premières positions, et peut-être même dans les pages, vous ne trouverez de manière tout à fait réaliste que des portails thématiques généraux sur tout, compte tenu de leur énorme autorité aux yeux de moteurs de recherche, âge et masse de référence.
Il est donc logique d’utiliser des expressions moins fréquentes composées de plus de mots pour trouver des concurrents.
Nous devons analyser leurs requêtes. Vous pouvez utiliser le service SpyWords, mais sa fonction d'analyse des requêtes est disponible sur un forfait payant, ce qui est assez cher. Par conséquent, pour un noyau, il ne sert à rien d'augmenter le tarif de ce service. Si vous devez collecter plusieurs cœurs au cours d'un mois, par exemple 5 à 10, vous pouvez alors acheter un compte. Mais encore une fois - seulement si vous disposez d'un budget pour le tarif PRO.
Vous pouvez également utiliser les statistiques Liveinternet si elles sont ouvertes à la consultation. Très souvent, les propriétaires le rendent ouvert aux annonceurs, mais ferment la section « expressions de recherche », ce qui est exactement ce dont nous avons besoin. Mais il existe encore des sites où cette rubrique est ouverte à tous. Très rare, mais disponible.
Le plus d'une manière simple est une vue banale des sections et des plans du site. Parfois, nous pouvons manquer non seulement certaines expressions de niche bien connues, mais également des demandes spécifiques. Il n'y a peut-être pas beaucoup de matériel sur eux et vous ne pouvez pas créer une section distincte pour eux, mais ils peuvent ajouter quelques dizaines d'articles.
Lorsque nous avons trouvé une autre liste de nouvelles expressions à collecter, nous lançons la même collection d'expressions de recherche à partir de la colonne de gauche de Yandex Wordstat, comme lors de la première étape. Nous venons de le lancer déjà, étant dans le deuxième groupe « Concurrents », afin que des demandes y soient spécifiquement ajoutées.
- Après l'analyse, nous collectons les fréquences exactes des expressions de recherche ;
- Nous définissons un filtre et déplaçons (supprimons) les requêtes avec une fréquence inférieure à 30 vers un groupe distinct ;
- Nous nettoyons les déchets (mots vides et requêtes qui ne sont pas liées à la niche).
Ainsi, nous avons reçu une autre petite liste de requêtes et le noyau sémantique est devenu plus complet.
Étape 3 – expansion
Nous avons déjà un groupe appelé « 1-2 ». Nous y copions les phrases des groupes « Liste principale des demandes » et « Concurrents ». Il est important de copier et de ne pas bouger, afin que toutes les phrases restent dans les groupes précédents, juste au cas où. Ce sera plus sûr de cette façon. Pour ce faire, dans la fenêtre de transfert de phrases, vous devez sélectionner l'option « copier ».
Nous avons reçu toutes les demandes des étapes 1 et 2 en un seul groupe. Il ne faut désormais laisser dans ce groupe que 10 % des requêtes les plus fréquentes du nombre total et qui contiennent au moins 2 mots. De plus, il ne devrait pas y avoir plus de 100 pièces. Nous le réduisons pour ne pas nous enterrer dans le processus de collecte de la carotte pendant un mois.
Tout d'abord, nous appliquons un filtre dans lequel nous définissons la condition afin qu'au moins des expressions de 2 mots soient affichées.

Nous marquons toutes les phrases dans la liste restante. En cliquant sur la colonne « Fréquence ! », nous trions les phrases par ordre décroissant de nombre d'impressions, afin que les plus fréquentes soient en haut. Ensuite, sélectionnez les premiers 10 % du nombre de requêtes restantes, décochez-les (bouton droit de la souris - décochez les lignes sélectionnées) et supprimez les phrases marquées afin qu'il ne reste que ces 10 %. N'oubliez pas que si vos 10 % font plus de 100 mots, alors on s'arrête à la ligne 100, il n'en faut pas plus.
Nous effectuons maintenant l'expansion à l'aide de la fonction keycollector. Le service Rookee vous y aidera.

Nous indiquons les paramètres de collecte comme dans la capture d'écran ci-dessous.

Le service collectera toutes les extensions. Parmi les nouvelles phrases, il peut y avoir des touches très longues, ainsi que des symboles, il ne sera donc pas possible pour tout le monde de collecter la fréquence via Yandex Direct. Ensuite, vous devrez collecter des statistiques à l'aide du bouton de Wordstat.
Après réception des statistiques, nous supprimons les demandes avec des impressions mensuelles inférieures à 30 et effectuons un nettoyage (mots vides, déchets, mots-clés non adaptés à la niche).
La scène est terminée. Nous avons reçu une autre liste de demandes.
Étape 4 – collecter les meilleures formes de mots
Comme je l’ai dit plus tôt, le but n’est pas de déterminer la forme de phrase qui sera la plus correcte.
Dans la plupart des cas (d'après mon expérience), la collecte des meilleures formes de mots pointera vers la même expression que celle figurant dans la liste de recherche. Mais, sans aucun doute, il y aura aussi des requêtes pour lesquelles une nouvelle forme de mot sera indiquée, qui n'est pas encore dans le noyau sémantique. Il s’agit de requêtes clés supplémentaires. À ce stade, nous atteignons le noyau jusqu'à l'exhaustivité maximale.
Lors de l'assemblage du noyau, cette étape a donné lieu à 107 demandes supplémentaires.
Tout d'abord, nous copions les clés dans le groupe « 1-3 » des groupes « Requêtes principales », « Concurrents » et « 1-2 ». La somme de toutes les demandes de toutes les étapes précédemment complétées doit être obtenue. Ensuite, nous utilisons le service Rookee en utilisant le même bouton que l'extension. Choisissez simplement une autre fonction.

La collecte va commencer. Les phrases seront ajoutées à une nouvelle colonne « Meilleure forme de phrase ».

La meilleure forme ne sera pas déterminée pour toutes les phrases, puisque le service Rookee ne connaît tout simplement pas toutes les meilleures formes. Mais pour la majorité, le résultat sera positif.
Une fois le processus terminé, vous devez ajouter ces phrases à la liste entière afin qu'elles se trouvent dans la même colonne « Phrase ». Pour ce faire, sélectionnez toutes les phrases dans la colonne « Meilleure forme de phrase », copiez (bouton droit de la souris - copier), puis cliquez sur le gros bouton vert « Ajouter des phrases » et saisissez-les.
Il est très simple de s'assurer que les phrases apparaissent dans la liste générale. Étant donné que l'ajout de phrases au tableau comme celui-ci se produit tout en bas, nous faisons défiler tout en bas de la liste et dans la colonne « Source », nous devrions voir l'icône du bouton d'ajout.

Les phrases ajoutées à l’aide d’extensions seront marquées d’une icône en forme de main.
Puisque la fréquence des meilleures formes de mots n’a pas été déterminée, cela doit être fait. Comme pour les étapes précédentes, nous collectons le nombre d’impressions. N'ayez pas peur que nous regroupions dans le même groupe où se trouvent les autres demandes. La collection continuera simplement pour les phrases comportant des cellules vides.
Si cela vous convient mieux, vous pouvez d'abord ajouter les meilleures formes de mots non pas au même groupe où elles ont été trouvées, mais à un nouveau, de sorte qu'elles seules soient là. Et déjà dedans, collectez des statistiques, effacez les déchets, etc. Et ensuite seulement, ajoutez les phrases normales restantes à la liste entière.
C'est tout. Le noyau sémantique du site a été assemblé. Mais il reste encore beaucoup de travail. Nous allons continuer.
Avant les étapes suivantes, vous devez télécharger toutes les demandes contenant les données nécessaires dans un fichier Excel sur votre ordinateur. Nous avons défini les paramètres d'exportation plus tôt afin que vous puissiez le faire immédiatement. L'icône d'exportation dans le menu principal de KeyCollector en est responsable.

Lorsque vous ouvrez le fichier, vous devriez obtenir 4 colonnes :
- Phrase;
- Source;
- Fréquence!;
- La meilleure forme de la phrase.
Il s'agit de notre noyau sémantique final, contenant la liste maximale de requêtes pures et nécessaires à la rédaction des futurs textes. Dans mon cas (créneau étroit), il y a eu 1 848 demandes, ce qui équivaut à environ 250 à 300 matériaux. Je ne peux pas le dire avec certitude - je n'ai pas encore complètement dissocié toutes les demandes.
Pour une utilisation immédiate, cela reste une option brute, car... les demandes sont dans un ordre chaotique. Nous devons également les répartir en groupes afin que chacun contienne les clés d'un article. C'est le but ultime.
Dissocier le noyau sémantique
Cette étape se réalise assez rapidement, bien qu'avec quelques difficultés. Le service nous aidera http://kg.ppc-panel.ru/. Il existe d'autres options, mais nous utiliserons celle-ci étant donné qu'avec elle nous ferons tout dans le rapport qualité/vitesse. Ce qu’il faut ici, ce n’est pas de la rapidité, mais avant tout de la qualité.
Une chose très utile à propos du service est qu'il mémorise toutes les actions effectuées dans votre navigateur à l'aide de cookies. Même si vous fermez cette page ou le navigateur dans son ensemble, tout sera enregistré. De cette façon, il n’est pas nécessaire de tout faire en même temps et d’avoir peur que tout soit perdu en un instant. Vous pouvez continuer à tout moment. L'essentiel est de ne pas effacer les cookies de votre navigateur.
Je vais vous montrer comment utiliser le service en utilisant l'exemple de plusieurs requêtes fictives.
Nous allons au service et ajoutons l'intégralité du noyau sémantique (toutes les requêtes du fichier Excel) exporté précédemment. Copiez simplement toutes les clés et collez-les dans la fenêtre comme indiqué dans l'image ci-dessous.
Ils doivent apparaître dans la colonne de gauche « Mots clés ».
Pour la présence de groupes ombrés dans côté droit ne fais pas attention. Ce sont des groupes de mon noyau précédent.
Nous regardons la colonne de gauche. Il y a une liste ajoutée de requêtes et une ligne « Recherche/Filtre ». Nous utiliserons le filtre.
La technologie est très simple. Lorsque nous saisissons une partie d'un mot ou d'une phrase, le service laisse en temps réel dans la liste des requêtes uniquement celles qui contiennent le mot/la phrase saisi dans la requête elle-même.
Voir ci-dessous pour plus de clarté.

Je voulais trouver toutes les requêtes liées à l'arythmie. Je saisis le mot « Arythmie » et le service laisse automatiquement dans la liste des requêtes uniquement celles qui contiennent le mot saisi ou une partie de celui-ci.
Les phrases seront déplacées vers un groupe, qui sera appelé l'une des phrases clés de ce groupe.
Nous avons reçu un groupe contenant tous les mots-clés pour l'arythmie. Pour voir le contenu d'un groupe, cliquez dessus. Un peu plus tard, nous diviserons ce groupe en groupes plus petits, car il existe de nombreuses clés relatives à l'arythmie et elles se trouvent toutes sous des articles différents.
Ainsi, au stade initial du regroupement, vous devez créer de grands groupes combinant un grand nombre de mots-clés d'une même question de niche.
Si nous prenons comme exemple le même sujet des maladies cardiaques, je créerai d'abord un groupe « arythmie », puis « maladies cardiaques », puis « crise cardiaque » et ainsi de suite jusqu'à ce qu'il y ait des groupes pour chaque maladie.
En règle générale, il y aura presque autant de groupes de ce type que d'expressions de niche principales générées lors de la 1ère étape de la collecte du noyau. Mais dans tous les cas, il devrait y en avoir plus, puisqu'il y a aussi des phrases des étapes 2 à 4.
Certains groupes peuvent contenir 1 à 2 clés au total. Cela peut être dû, par exemple, à une maladie très rare et personne ne la connaît ou ne la recherche. C'est pourquoi il n'y a aucune demande.
En général, lorsque les groupes principaux sont créés, il est nécessaire de les décomposer en groupes plus petits, qui serviront à rédiger des articles individuels.
A l'intérieur du groupe, à côté de chaque phrase clé se trouve une croix ; en cliquant dessus, la phrase est supprimée du groupe et revient à la liste de mots clés non regroupés.
C'est ainsi que se produit un regroupement ultérieur. Je vais vous montrer avec un exemple.
Sur l’image, vous pouvez voir qu’il existe des phrases clés liées au traitement de l’arythmie. Si nous voulons les définir dans un groupe distinct pour un article distinct, nous les supprimons du groupe.

Ils apparaîtront dans la liste dans la colonne de gauche.
S'il y a encore des phrases dans la colonne de gauche, alors pour retrouver les clés supprimées du groupe, vous devrez appliquer un filtre (utiliser la recherche). Si la liste est complètement divisée en groupes, seules les demandes supprimées y figureront. Nous les marquons et cliquons sur « Créer un groupe ».

Un autre apparaîtra dans la colonne « Groupes ».
Ainsi, nous répartissons toutes les clés par thème et, in fine, un article séparé est rédigé pour chaque groupe.
La seule difficulté de cette démarche réside dans l’analyse de la nécessité de dissocier certains mots-clés. Le fait est qu'il existe des clés intrinsèquement différentes, mais elles ne nécessitent pas la rédaction de textes séparés, mais des documents détaillés sont rédigés sur de nombreuses questions.
Cela s'exprime clairement dans les sujets médicaux. Si l’on prend l’exemple de l’arythmie, alors cela ne sert à rien de faire les clés « causes de l’arythmie » et « symptômes de l’arythmie ». Les clés du traitement de l’arythmie restent encore incertaines.
Cela sera découvert après avoir analysé les résultats de la recherche. Nous allons à la recherche Yandex et entrons la clé analysée. Si nous constatons que le TOP contient des articles consacrés uniquement aux symptômes de l'arythmie, alors nous séparons cette clé dans un groupe distinct. Mais si les textes du TOP couvrent toutes les questions (traitement, causes, symptômes, diagnostic, etc.), alors le dégroupement dans ce cas n'est pas nécessaire. Nous abordons tous ces sujets dans un seul article.
Si dans Yandex, de tels textes figurent exactement en haut des résultats de recherche, c'est le signe que le dissociation n'en vaut pas la peine.
La même chose peut être illustrée par l’expression clé « causes de la perte de cheveux ». Il peut y avoir « des causes de perte de cheveux chez les hommes » et « ... chez les femmes ». Évidemment, vous pouvez écrire un texte séparé pour chaque touche, basé sur la logique. Mais que dira Yandex ?
Nous entrons dans chaque clé et voyons quels textes s'y trouvent. Il existe des textes détaillés distincts pour chaque touche, puis les touches sont dissociées. Si dans le TOP pour les deux requêtes il y a des documents généraux sur les principales « causes de la perte de cheveux », dans lesquels sont divulguées des questions concernant les femmes et les hommes, alors nous laissons les clés au sein d'un groupe et publions un document où sont révélés les sujets sur toutes les clés. .
C'est important, car ce n'est pas pour rien que le moteur de recherche identifie les textes dans le TOP. Si la première page contient exclusivement des textes détaillés sur une question spécifique, il y a alors une forte probabilité qu'en divisant un vaste sujet en sous-thèmes et en écrivant du matériel sur chacun, vous n'arriverez pas au TOP. Ainsi, un matériau a toutes les chances d'obtenir de bonnes positions pour toutes les demandes et de collecter un bon trafic pour celles-ci.
Dans les domaines médicaux, une grande attention doit être accordée à ce point, ce qui complique et ralentit considérablement le processus de dégroupage.
Tout en bas de la colonne « Groupes » se trouve un bouton « Décharger ». Cliquez dessus et nous obtenons une nouvelle colonne avec un champ de texte contenant tous les groupes, séparés par un retrait de ligne.
Si toutes les clés ne sont pas regroupées, alors dans le champ « Télécharger », il n'y aura aucun espace entre elles. Ils n'apparaissent que lorsque le dégroupage est complètement terminé.
Sélectionnez tous les mots (combinaison de touches Ctrl+A), copiez-les et collez-les dans nouveau Excel déposer.
Ne cliquez en aucun cas sur le bouton « Tout effacer », car absolument tout ce que vous avez fait sera supprimé.
La phase de dégroupage est terminée. Vous pouvez désormais rédiger le texte en toute sécurité pour chaque groupe.
Mais, pour une efficacité maximale, si votre budget ne vous permet pas de tout rédiger. noyau en quelques jours, et il n'y a qu'une possibilité strictement limitée de publication régulière d'un petit nombre de textes (10 à 30 par mois, par exemple), alors il vaut la peine de déterminer la concurrence de tous les groupes. Ceci est important car les groupes les moins compétitifs produisent des résultats dans les 2-3-4 premiers mois après avoir écrit sans aucun lien. Tout ce que vous avez à faire est de rédiger un texte compétitif de haute qualité et de l’optimiser correctement. Alors le temps fera tout pour vous.
Définition de la compétition de groupe
Je tiens d'emblée à préciser qu'une demande ou un groupe de demandes à faible concurrence ne signifie pas qu'ils sont de très micro basse fréquence. La beauté est qu'il existe un nombre assez décent de demandes qui ont une faible concurrence, mais qui en même temps ont haute fréquence, ce qui fait immédiatement apparaître un tel article dans le TOP et attire un trafic important vers un document.
Par exemple, une image très réaliste est celle d'un groupe de requêtes ayant 2 à 5 concurrents et la fréquence est d'environ 300 impressions par mois. Après avoir écrit seulement 10 textes de ce type, une fois qu'ils auront atteint le TOP, nous recevrons au moins 100 visiteurs par jour. Et ce ne sont que 10 textes. 50 articles - 500 visites et ces chiffres sont pris comme plafond, car celui-ci ne prend en compte que le trafic pour les requêtes exactes dans le groupe. Mais le trafic sera également attiré par d’autres requêtes, et pas seulement par celles des groupes.
C'est pourquoi il est si important d'identifier la concurrence. Parfois, vous pouvez voir une situation où il y a 20 à 30 textes sur un site et il y a déjà 1 000 visites. Et le site est jeune et il n'y a pas de liens. Vous savez maintenant à quoi cela est lié.
La concurrence des demandes peut être déterminée gratuitement via le même KeyCollector. C'est très pratique, mais idéalement, cette option n'est pas correcte, car la formule permettant de déterminer la concurrence change constamment avec l'évolution des algorithmes des moteurs de recherche.
Mieux identifier la concurrence grâce au service http://mutagen.ru/. Il est payant, mais se rapproche autant que possible des indicateurs réels.
100 demandes ne coûtent que 30 roubles. Si vous disposez d'un noyau pour 2 000 demandes, la totalité du chèque coûtera 600 roubles. 20 chèques gratuits sont remis par jour (uniquement à ceux qui rechargent leur solde de n'importe quel montant). Vous pouvez évaluer 20 phrases chaque jour jusqu'à ce que vous déterminiez la compétitivité de l'ensemble du noyau. Mais c'est très long et stupide.
Par conséquent, j’utilise le mutagène et je n’ai rien à redire à ce sujet. Parfois, il y a des problèmes liés à la vitesse de traitement, mais ce n'est pas si critique, car même après la fermeture de la page de service, la vérification se poursuit en arrière-plan.
L'analyse elle-même est très simple. Inscrivez-vous sur le site. Nous complétons le solde avec n'importe quel d'une manière pratique et la vérification est disponible à l'adresse principale (mutagen.ru). Nous entrons une phrase dans le champ et son évaluation commence immédiatement.
On voit que pour la requête vérifiée, la compétitivité s'est avérée supérieure à 25. Il s'agit d'un indicateur très élevé et peut être égal à n'importe quel nombre. Le service ne l'affiche pas comme réel, car cela n'a aucun sens car de telles demandes concurrentielles sont presque impossibles à promouvoir.
Le niveau normal de compétition est considéré comme allant jusqu'à 5. Ce sont précisément ces demandes qui sont facilement promues sans gestes inutiles. Des indicateurs légèrement plus élevés sont également tout à fait acceptables, mais les requêtes avec des valeurs supérieures à 5 (par exemple 6-10) doivent être utilisées après avoir déjà écrit des textes pour une concurrence minimale. Importance maximale texte rapide au sommet.
Également lors de l'évaluation, le coût d'un clic dans Yandex.Direct est déterminé. Il peut être utilisé pour estimer vos revenus futurs. Nous prenons en compte les impressions garanties, dont nous pouvons diviser la valeur par 3 en toute sécurité. Dans notre cas, nous pouvons dire qu'un clic sur une publicité Yandex Direct nous rapportera 1 rouble.
Le service détermine également le nombre d'impressions, mais nous ne les regardons pas, puisque la fréquence de type « !request » n'est pas déterminée, mais seulement la « demande ». L'indicateur s'avère inexact.
Cette option d'analyse convient si nous souhaitons analyser une seule demande. Si vous avez besoin d'une vérification massive des phrases clés, il existe un lien spécial sur la page principale en haut du champ de saisie des clés.

Sur la page suivante, nous créons une nouvelle tâche et ajoutons une liste de clés du noyau sémantique. Nous les retirons du fichier où les clés sont déjà dissociées.
S'il y a suffisamment de fonds sur le solde pour analyse, le contrôle commencera immédiatement. La durée du contrôle dépend du nombre de clés et peut prendre un certain temps. J'ai analysé 2000 phrases pendant environ 1 heure, alors que la deuxième fois, la vérification de seulement 30 clés a pris plusieurs heures.
Immédiatement après le démarrage de l'analyse, vous verrez la tâche dans la liste, où se trouvera une colonne « Statut ». Cela vous aidera à comprendre si la tâche est prête ou non.
De plus, après avoir terminé la tâche, vous pourrez immédiatement télécharger un fichier avec une liste de toutes les phrases et le niveau de compétition pour chacune. Les phrases seront toutes dans le même ordre car elles ont été dissociées. La seule chose est que les espaces entre les groupes seront supprimés, mais ce n'est pas grave, car tout sera intuitif, car chaque groupe contient des clés sur un sujet différent.
De plus, si la tâche n'est pas encore terminée, vous pouvez accéder à la tâche elle-même et voir les résultats du concours pour les demandes déjà terminées. Cliquez simplement sur le nom de la tâche.
A titre d'exemple, je vais montrer le résultat de la vérification d'un groupe de requêtes pour le noyau sémantique. En fait, c’est le groupe pour lequel cet article a été écrit.
Nous constatons que presque toutes les demandes ont un concours maximum de 25 ou plus. Cela signifie que pour ces demandes, soit je ne verrai pas les premières positions, soit je ne les verrai pas pendant très longtemps. Je n’écrirais pas du tout un tel matériel sur le nouveau site.
Maintenant, je l'ai publié uniquement pour créer du contenu de qualité pour le blog. Bien sûr, mon objectif est d’arriver au sommet, mais c’est plus tard. Si le manuel atteint la première page, au moins uniquement pour la requête principale, alors je peux déjà compter sur un trafic important uniquement vers cette page.
La dernière étape consiste à créer le fichier final, que nous examinerons lors du remplissage du site. Le noyau sémantique du site est déjà constitué, mais sa gestion n'est pas encore tout à fait pratique.
Création d'un fichier final avec toutes les données
Nous aurons encore besoin du KeyCollector et également dernier fichier Excel, que nous avons reçu du service mutagène.
Nous ouvrons le fichier précédemment reçu et voyons quelque chose comme ce qui suit.
Nous n'avons besoin que de 2 colonnes du fichier :
- clé;
- concours.
Vous pouvez simplement supprimer tout autre contenu de ce fichier afin de ne conserver que les données nécessaires, ou vous pouvez le créer entièrement. nouveau fichier, faites-y une jolie ligne de titre avec les noms des colonnes, en la mettant en évidence, par exemple, en vert, et copiez les données correspondantes dans chaque colonne.
Ensuite, nous copions l'intégralité du noyau sémantique de ce document et l'ajoutons à nouveau au collecteur de clés. Les fréquences devront être à nouveau collectées. Ceci est nécessaire pour que les fréquences soient collectées dans le même ordre que les phrases clés. Auparavant, nous les collections pour éliminer les déchets, et maintenant pour créer le fichier final. Bien sûr, nous ajoutons des phrases à un nouveau groupe.
Lorsque les fréquences sont collectées, nous exportons le fichier de toute la colonne de fréquences et le copions dans le fichier final, qui comportera 3 colonnes :
- phrase clé;
- compétitivité;
- fréquence.
Il ne reste plus qu’à s’asseoir un peu et à faire le calcul pour chaque groupe :
- Fréquence moyenne du groupe - ce n'est pas l'indicateur de chaque clé qui est important, mais l'indicateur moyen du groupe. Elle est calculée comme la moyenne arithmétique habituelle (dans Excel - la fonction "MOYENNE") ;
- Divisez la fréquence totale du groupe par 3 pour ramener le trafic possible à des chiffres réels.
Pour que vous n'ayez pas à vous soucier de maîtriser les calculs dans Excel, je vous ai préparé un fichier dans lequel il vous suffit de saisir les données dans les colonnes requises et tout sera calculé de manière entièrement automatique. Chaque groupe doit être calculé séparément.
Il y aura un exemple de calcul simple à l’intérieur.
Comme vous pouvez le constater, tout est très simple. Depuis le fichier final, copiez simplement toutes les phrases entières du groupe avec tous les indicateurs et collez-les dans ce fichier à la place des phrases précédentes avec leurs données. Et le calcul se fera automatiquement.
Il est important que les colonnes du fichier final et du mien soient exactement dans cet ordre. D’abord la phrase, puis la fréquence, et ensuite seulement la compétition. Sinon, vous compterez des bêtises.
Ensuite, vous devrez vous asseoir un peu pour créer un autre fichier ou feuille (je recommande) à l'intérieur du fichier avec toutes les données sur chaque groupe. Cette fiche ne contiendra pas toutes les phrases, mais seulement la phrase principale du groupe (nous l'utiliserons pour déterminer de quel type de groupe il s'agit) et les valeurs calculées du groupe à partir de mon dossier. Il s'agit d'une sorte de fichier final contenant des données sur chaque groupe avec des valeurs calculées. C'est ce que je regarde lors du choix des textes à publier.
Vous obtiendrez les mêmes 3 colonnes, mais sans aucun calcul.
Dans le premier, nous insérons la phrase principale du groupe. En principe, tout est possible. Il suffit de le copier et, grâce à une recherche, de trouver l'emplacement de toutes les clés de groupe qui se trouvent sur une autre feuille.
Dans le second nous copions la valeur de fréquence calculée de mon fichier, et dans le troisième nous copions la valeur moyenne de la compétition du groupe. Nous prenons ces chiffres de la ligne « Résultat ».
Le résultat sera le suivant.
C'est la 1ère feuille. La deuxième feuille contient tout le contenu du fichier final, c'est-à-dire toutes les phrases avec des indicateurs de leur fréquence et de leur concurrence.
Examinons maintenant la 1ère feuille. Nous sélectionnons le groupe de clés le plus « rentable ». Nous copions la phrase de la 1ère colonne et la trouvons en utilisant la recherche (Ctrl + F) dans la deuxième feuille, où le reste des phrases du groupe sera situé à côté d'elle.
C'est tout. Le manuel est terminé. À première vue, tout est très compliqué, mais en réalité c'est assez simple. Comme je l'ai déjà dit au tout début de l'article, il suffit de commencer à le faire. À l'avenir, je prévois de créer un manuel vidéo en utilisant ces instructions.
Eh bien, sur cette note, je termine les instructions.
Tous les amis. Si vous avez des suggestions ou des questions, je vous attends dans les commentaires. À plus tard.
P.S. Enregistrez le volume de contenu. Dans Word, il s’est avéré qu’il y avait plus de 50 feuilles de petits caractères. Il était possible non pas de publier un article, mais de créer un livre.
Cordialement, Konstantin Khmelev!
Avant de commencer la promotion SEO, vous devez créer un noyau sémantique du site - une liste de requêtes de recherche que les clients potentiels utilisent lors de la recherche des biens ou des services que nous proposons. Tous les travaux ultérieurs - optimisation interne et travail avec des facteurs externes (achat de liens) sont effectués conformément à la liste de demandes définie à ce stade.
Le coût final de la promotion et même le niveau de conversion attendu (nombre d'appels vers l'entreprise) dépendent également de la bonne collecte du noyau.
Comment grande quantité les entreprises sont promues par le mot choisi, plus la concurrence est élevée et, par conséquent, le coût de la promotion.
De plus, lorsque vous choisissez une liste de requêtes, vous ne devez pas seulement vous fier à vos idées sur les mots utilisés par vos clients potentiels, mais également vous fier à l'opinion des professionnels, car tout le monde n'est pas cher et requêtes populaires avoir conversion élevée et promouvoir certains mots directement liés à votre entreprise peut tout simplement ne pas être rentable, même s'il est possible d'obtenir le résultat idéal sous la forme de TOP-1.
Un noyau sémantique correctement formé, toutes choses égales par ailleurs, garantit que le site est positionné en toute confiance dans les premières positions des résultats de recherche pour un large éventail de requêtes.
Principes de compilation de la sémantique
Les requêtes de recherche sont formées par des personnes – des visiteurs potentiels du site, en fonction de leurs objectifs. Suivre méthodes mathématiques L'analyse statistique intégrée à l'algorithme de travail des robots des moteurs de recherche est difficile, d'autant plus qu'ils sont continuellement affinés, améliorés et donc changent.
La plupart façon efficace Couvrir le nombre maximum de requêtes possibles lors de la constitution du noyau sémantique d'un site, c'est le regarder comme s'il était du point de vue d'une personne faisant une requête dans une recherche.
Le moteur de recherche a été créé pour aider une personne à trouver rapidement la source d'informations la plus appropriée pour une requête de recherche. Le moteur de recherche se concentre avant tout sur un moyen rapide de réduire à plusieurs dizaines d'options de réponse les plus adaptées à la phrase clé (mot) de la demande.
Lors de la constitution d'une liste de ces mots-clés, qui constituera la base de la sémantique du site, le cercle de ses visiteurs potentiels est en effet déterminé.
Étapes de collecte du noyau sémantique :
- Tout d'abord, une liste des principales phrases et mots clés trouvés dans le champ d'information du site et caractérisant son orientation cible est établie. Dans ce cas, vous pouvez utiliser les dernières informations statistiques sur la fréquence des requêtes dans la direction en question provenant du moteur de recherche. En plus des principales variantes de mots et d'expressions, il est également nécessaire d'écrire leurs synonymes et variantes d'autres noms : lessive - détergent. Le service Yandex Wordstat est parfait pour ce travail.

- Vous pouvez également noter les composants du nom de tout produit ou sujet de la demande. Très souvent, les requêtes incluent des mots comportant des fautes de frappe, des fautes d’orthographe ou simplement des mots mal orthographiés en raison du manque d’alphabétisation d’une grande partie des internautes. La prise en compte de cette fonctionnalité peut également attirer des ressources supplémentaires de la part des visiteurs du site, surtout si de nouveaux noms apparaissent.
- Les requêtes les plus courantes, également appelées requêtes haute fréquence, conduisent rarement une personne vers le site qu’elle recherche. Les requêtes basse fréquence, c'est-à-dire les requêtes avec clarification, fonctionnent mieux. Par exemple, la requête Ring renverra un haut et le segment de piston fournira des informations plus spécifiques. Lors de la collecte, il est préférable de se concentrer sur de telles demandes. Cela attirera des visiteurs cibles, c'est-à-dire par exemple des acheteurs potentiels s'il s'agit d'un site commercial.
- Lors de l'établissement d'une liste de mots-clés, il est également conseillé de prendre en compte l'argot répandu, le soi-disant folk, qui est devenu des noms généralement acceptés et stables pour certains objets, concepts, services, etc., par exemple : téléphone portable– téléphone portable – téléphone portable – téléphone portable. La prise en compte de tels néologismes peut dans certains cas donner une augmentation significative public cible.
- En général, lors de l'élaboration d'une liste de clés, il est préférable de se concentrer dans un premier temps spécifiquement sur le public cible, c'est-à-dire les visiteurs du site Web auxquels le produit ou le service est destiné. Le noyau ne doit pas contenir un nom peu connu d'un élément (produit, service) comme option principale, même s'il doit être promu. De tels mots seront extrêmement rarement trouvés dans les requêtes. Il est préférable de les utiliser avec des clarifications ou d'utiliser des noms similaires ou analogues plus populaires.
- Lorsque la sémantique est prête, elle doit être passée à travers une série de filtres pour supprimer les mots-clés obstruants, ce qui signifie qu'ils amènent le mauvais public cible sur le site.
Prise en compte de la sémantique des requêtes associées
- A la liste initiale du noyau sémantique, compilée à partir des clés principales, il convient d'ajouter un certain nombre de clés auxiliaires basse fréquence, qui peuvent inclure des mots importants mais non pris en compte qui ne sont pas venus à l'esprit lors de sa compilation. Le moteur de recherche lui-même vous y aidera. Lorsque vous tapez à plusieurs reprises des expressions clés de la liste sur un sujet, le moteur de recherche lui-même propose des options de réflexion pour les expressions fréquentes dans ce domaine.
- Par exemple, si l'expression « réparation d'ordinateur » est saisie et que la deuxième requête est une matrice, alors le moteur de recherche les percevra comme associées, c'est-à-dire interconnectées dans leur sens, et fournira diverses requêtes fréquentes dans ce domaine pour aide. Avec de telles phrases clés, vous pouvez étendre la sémantique originale.
- Connaissant quelques mots principaux du noyau, avec l'aide d'un moteur de recherche, il peut être considérablement étendu avec des expressions associées. Dans le cas où un moteur de recherche ne produit pas un nombre insuffisant de ces clés supplémentaires, vous pouvez les obtenir en utilisant les méthodes d'un thésaurus - un ensemble de concepts (termes) pour un sujet spécifique du même domaine conceptuel. Les dictionnaires et les ouvrages de référence peuvent être utiles ici.
 Schéma logique de sélection de la sémantique d'un site
Schéma logique de sélection de la sémantique d'un site Constitution d'une liste de demandes et leur rédaction finale
- Les phrases clés qui composent la sémantique générée lors des deux premières étapes nécessitent un filtrage. Parmi ces phrases, il peut y en avoir des inutiles, qui ne feront qu'alourdir le noyau, sans apporter aucun avantage tangible pour attirer le public cible des visiteurs du site. Les phrases obtenues en analysant l'orientation cible du site et développées à l'aide des clés associées sont appelées masques. Il s'agit d'une liste importante qui permet de rendre le site visible, c'est-à-dire que lorsqu'un moteur de recherche fonctionne, en réponse à une requête, ce site sera également affiché dans la liste des sites proposés.
- Vous devez maintenant créer des listes de requêtes de recherche pour chaque masque. Pour ce faire, vous devrez utiliser le moteur de recherche vers lequel ce site est orienté, par exemple Yandex, Rambler, Google ou autres. La liste créée pour chaque masque est sujette à des modifications et à un nettoyage ultérieurs. Ce travail est effectué sur la base de la clarification des informations publiées sur le site, ainsi que des notes réelles des moteurs de recherche.
- Le nettoyage consiste à supprimer les requêtes inutiles, peu informatives et nuisibles. Par exemple, si la liste d'un site Web de matériaux de construction comprend des expressions avec les mots « travaux de cours », alors elles doivent être supprimées, car il est peu probable qu'elles élargissent le public cible. Après le nettoyage et l'édition finale, vous obtiendrez une version de requêtes clés réellement fonctionnelles, dont le contenu promouvra le site dans la zone dite de visibilité des moteurs de recherche. Dans ce cas, le moteur de recherche pourra afficher la page souhaitée à partir du noyau sémantique à l'aide de liens internes du site.
En résumant tout ce qui précède, nous pouvons dire brièvement que la sémantique d'un site est déterminée par le nombre total de formulations de requêtes des moteurs de recherche utilisées et leur fréquence totale dans les statistiques de visites pour une requête spécifique.
Tous les travaux de formation et d'édition de la sémantique peuvent se réduire aux éléments suivants :
- analyse des informations diffusées sur le site, des buts poursuivis par la création de ce site ;
- compiler une liste générale d'expressions possibles sur la base de l'analyse du site ;
- générer une version étendue de mots-clés à l'aide de requêtes associées (masques) ;
- générer une liste d'options de requête pour chaque masque ;
- modifier (nettoyer) la liste pour exclure les phrases sans importance.
Grâce à cet article, vous avez appris ce qu'est le noyau sémantique d'un site Web et comment il doit être compilé.
Le noyau sémantique est un sujet plutôt galvaudé, n’est-ce pas ? Aujourd'hui, nous allons résoudre ce problème ensemble en collectant la sémantique dans cette leçon !
Vous ne me croyez pas ? - voyez par vous-même - entrez simplement l'expression noyau sémantique du site dans Yandex ou Google. Je pense qu'aujourd'hui je vais corriger cette erreur gênante.
Mais vraiment, qu'est-ce que ça fait pour toi - sémantique idéale? Vous pourriez penser que c'est une question stupide, mais en fait ce n'est pas du tout stupide, c'est juste que la plupart des webmasters et propriétaires de sites croient fermement qu'ils savent composer des noyaux sémantiques et que n'importe quel écolier peut faire face à tout cela, et eux-mêmes essaient d'enseigner aux autres... Mais en réalité, tout est bien plus compliqué. Une fois, ils m'ont demandé : que dois-tu faire en premier ? — le site lui-même et son contenu ou sept noyaux, et demandé par une personne qui ne se considère pas comme novice en référencement. Ici cette question et m'a fait comprendre la complexité et l'ambiguïté de ce problème.
Le noyau sémantique est la base des fondations - la toute première étape qui précède le lancement de toute campagne publicitaire sur Internet. Parallèlement à cela, la sémantique du site est le processus le plus fastidieux qui prendra beaucoup de temps, mais qui sera de toute façon plus que payant.
Eh bien... créons son ensemble!
Une courte préface
Pour créer un champ sémantique pour un site Web, nous avons besoin d'un seul et unique programme - Collectionneur de clés . En prenant l'exemple du Collectionneur, j'analyserai l'exemple de la collecte d'un petit groupe familial. En plus du programme payant, il existe également des analogues gratuits comme SlovoEb et autres.
La sémantique est assemblée en plusieurs étapes fondamentales, parmi lesquelles il convient de souligner les suivantes :
- brainstorming - analyse des phrases de base et préparation de l'analyse
- analyse - expansion de la sémantique de base basée sur Wordstat et d'autres sources
- criblage - criblage après analyse
- analyse - analyse de la fréquence, de la saisonnalité, de la concurrence et d'autres indicateurs importants
- raffinement - regroupement, séparation des phrases commerciales et informatives du noyau
Les étapes les plus importantes de la collecte seront abordées ci-dessous !
VIDÉO - compiler un noyau sémantique pour les concurrents
Brainstorming lors de la création d'un noyau sémantique - faire travailler notre cerveau
A ce stade, il faut faire une sélection mentale le noyau sémantique du site et proposer autant d'expressions que possible en fonction de notre sujet. Alors, lancez le collecteur de clés et sélectionnez Analyse Wordstat, comme le montre la capture d'écran :

Une petite fenêtre s'ouvre devant nous, dans laquelle nous devons saisir autant de phrases que possible sur notre sujet. Comme je l'ai déjà dit, dans cet article, nous allons créer un exemple d'ensemble d'expressions pour ce blog, les phrases pourraient donc être les suivantes :
- blog de référencement
- blog de référencement
- blog sur le référencement
- blog sur le référencement
- promotion
- promotion projet
- promotion
- promotion
- promotion du blog
- promotion du blog
- promotion du blog
- promotion du blog
- promotion avec des articles
- promotion d'articles
- liens miraliens
- travailler à la sape
- acheter des liens
- liens d'achat
- optimisation
- optimisation des pages
- optimisation interne
- auto-promotion
- comment promouvoir une ressource
- comment promouvoir votre site Web
- comment promouvoir soi-même un site Web
- comment promouvoir soi-même un site Web
- auto-promotion
- promotion gratuite
- promotion gratuite
- optimisation du moteur de recherche
- comment promouvoir un site Web dans Yandex
- comment promouvoir un site Web dans Yandex
- promotion sous Yandex
- Promotion Google
- promotion sur Google
- indexage
- accélération de l'indexation
- site de sélection des donneurs
- sélection des donneurs
- promotion par les gardes
- utilisation de gardes
- promotion du blog
- Algorithme Yandex
- Mise à jour des seins
- mise à jour de la base de données de recherche
- Mise à jour Yandex
- des liens pour toujours
- liens éternels
- liens de location
- lien loué
- liens avec paiement mensuel
- compiler un noyau sémantique
- secrets de promotion
- secrets de promotion
- Secrets de référencement
- secrets d'optimisation
Je pense que c'est suffisant, et donc la liste fait une demi-page ;) En général, l'idée est que dans un premier temps, vous devez analyser au maximum votre secteur d'activité et sélectionner autant de phrases que possible qui reflètent le thème du site. . Cependant, si vous avez manqué quelque chose à ce stade, ne désespérez pas : les phrases manquées reviendront certainement dans les prochaines étapes, vous devrez juste faire beaucoup de travail supplémentaire, mais ce n'est pas grave. Nous prenons notre liste et la copions au collecteur de clés. Ensuite, cliquez sur le bouton - Analyser à partir de Yandex.Wordstat:
L'analyse peut prendre beaucoup de temps, vous devez donc être patient. L'assemblage du noyau sémantique prend généralement 3 à 5 jours, et le premier jour sera consacré à la préparation du noyau sémantique de base et à l'analyse.
J'ai écrit des instructions détaillées sur la façon de travailler avec la ressource et de sélectionner des mots-clés. Vous pouvez également vous renseigner sur la promotion de sites Web sur la base de requêtes à faible fréquence.
De plus, je dirai qu'au lieu de réflexion nous pouvons utiliser la sémantique prête à l'emploi des concurrents en utilisant l'un des services spécialisés, par exemple SpyWords. Dans l'interface de ce service nous entrons simplement le mot-clé dont nous avons besoin et voyons les principaux concurrents présents dans le TOP pour cette phrase. De plus, la sémantique du site Web de n’importe quel concurrent peut être entièrement téléchargée à l’aide de ce service.

Ensuite, nous pouvons sélectionner n'importe lequel d'entre eux et extraire ses requêtes, qui resteront à trier des ordures et à utiliser comme sémantique de base pour une analyse ultérieure. Ou nous pouvons le faire encore plus simplement et utiliser .
Nettoyer la sémantique
Dès que l'analyse de Wordstat s'arrête complètement - il est temps d'éliminer le noyau sémantique. Cette étape est très importante, alors traitez-la avec toute l'attention voulue.
Voilà, mon analyse est terminée, mais j'ai les phrases Tant, et par conséquent, filtrer les mots peut nous prendre plus de temps. Par conséquent, avant de procéder à la détermination de la fréquence, vous devez effectuer un premier nettoyage des mots. Nous allons procéder en plusieurs étapes :
1. Filtrons les requêtes à très basse fréquence
Pour ce faire, cliquez sur le symbole de tri par fréquence et commencez à effacer toutes les requêtes avec des fréquences inférieures à 30 :
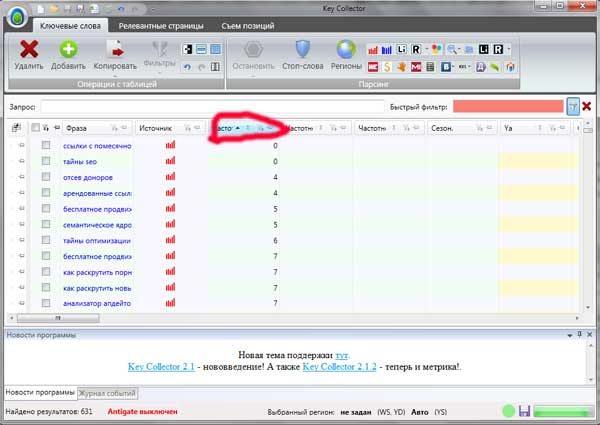
Je pense que vous pouvez facilement gérer ce point.
2. Nous supprimerons les requêtes qui n’ont aucun sens
Certaines requêtes contiennent suffisamment fréquence exacte et une faible concurrence, mais ils Ne correspond pas du tout à notre thème. Ces clés doivent être supprimées avant de vérifier les occurrences exactes de la clé, car la vérification peut prendre beaucoup de temps. Nous supprimerons ces clés manuellement. Ainsi, pour mon blog, les éléments suivants se sont avérés superflus :
cours d'optimisation des moteurs de recherche vendre un site Web promu
Analyse sémantique du noyau
A ce stade, nous devons déterminer les fréquences exactes de nos touches, pour lesquelles vous devez cliquer sur le symbole de la loupe, comme le montre l'image :

Le processus est assez long, vous pouvez donc aller vous préparer du thé)
Une fois la vérification réussie, nous devons continuer à nettoyer notre noyau.
Je vous suggère de supprimer toutes les clés avec une fréquence inférieure à 10 requêtes. De plus, pour mon blog, je supprimerai toutes les requêtes avec des valeurs supérieures à 1 000, car je n'ai pas l'intention d'avancer avec de telles requêtes.
Export et regroupement du noyau sémantique
Ne pensez pas que cette étape sera la dernière. Pas du tout! Nous devons maintenant transférer le groupe résultant vers Excel pour une clarté maximale. Ensuite, nous trierons par page et nous verrons alors de nombreuses lacunes, que nous corrigerons.
Exporter la sémantique du site vers Excel n’est pas du tout difficile. Pour cela, il vous suffit de cliquer sur le symbole correspondant, comme indiqué dans l'image :

Après l'insertion dans Excel, nous verrons l'image suivante :
Les colonnes marquées en rouge doivent être supprimées. Ensuite, nous créons un autre tableau dans Excel, qui contiendra le noyau sémantique final.
Le nouveau tableau comportera 3 colonnes : URLpages, phrase clé et lui fréquence. Pour l'URL, sélectionnez soit une page existante, soit une page qui sera créée dans le futur. Tout d'abord, sélectionnons les clés de la page principale de mon blog :

Après toutes les manipulations, nous voyons l'image suivante. Et plusieurs conclusions s’imposent immédiatement :
- de telles requêtes à haute fréquence devraient avoir une queue beaucoup plus grande de phrases moins fréquentes que ce que nous voyons
- nouvelles de référencement
- une nouvelle clé est apparue que nous n'avions pas prise en compte auparavant - Articles de référencement. Cette clé doit être analysée
Comme je l'ai déjà dit, aucune clé ne peut nous être cachée. La prochaine étape pour nous consiste à réfléchir à ces trois phrases. Après réflexion, nous répétons toutes les étapes en commençant par le tout premier point pour ces clés. Tout cela peut vous sembler trop long et fastidieux, mais c'est comme ça : compiler un noyau sémantique est un travail très responsable et minutieux. Mais un champ bien conçu aidera grandement à la promotion du site Web et pourra grandement économiser votre budget.
Après toutes les opérations effectuées, nous avons pu obtenir de nouvelles clés pour la page principale de ce blog :
- meilleur blog de référencement
- nouvelles de référencement
- Articles de référencement
Et quelques autres. Je pense que la technique est claire pour vous.
Après toutes ces manipulations, nous verrons quelles pages de notre projet doivent être modifiées (), et quelles nouvelles pages doivent être ajoutées. La plupart des clés que nous avons trouvées (avec une fréquence allant jusqu'à 100, et parfois beaucoup plus) peuvent être facilement promues seules.
Élimination définitive
En principe, le noyau sémantique est presque prêt, mais il existe un autre point assez important qui nous aidera à améliorer considérablement notre groupe sémantique. Pour cela, nous avons besoin de Seopult.
*En fait, ici, vous pouvez utiliser n'importe lequel des services similaires qui vous permettent de connaître la concurrence par mots-clés, par exemple Mutagen !
Nous créons donc un autre tableau dans Excel et y copions uniquement les noms des clés (colonne du milieu). Afin de ne pas perdre beaucoup de temps, je vais copier uniquement les clés de la page principale de mon blog :


Ensuite, nous vérifions le coût de réception d'un clic à l'aide de nos mots-clés :

Le coût de la transition pour certaines phrases dépassait 5 roubles. De telles expressions doivent être éliminées de notre noyau.

Peut-être que vos préférences seront légèrement différentes, vous pourrez alors exclure les phrases les moins chères ou vice versa. Dans mon cas, j'ai supprimé 7 phrases.
Information utile!
sur la constitution d'un noyau sémantique, en mettant l'accent sur l'élimination des mots-clés les moins compétitifs.
Si vous avez votre propre boutique en ligne - lire, qui décrit comment le noyau sémantique peut être utilisé.
Clustering du noyau sémantique
Je suis sûr que vous avez déjà entendu ce mot en relation avec l'optimisation des moteurs de recherche. Voyons de quel type d'animal il s'agit et pourquoi il est nécessaire lors de la promotion d'un site Web.
Modèle classique promotion sur les moteurs de recherche comme suit:
- Sélection et analyse des requêtes de recherche
- Regroupement des requêtes par pages du site (création de landing pages)
- Préparation de textes SEO pour les landing pages sur la base d'un groupe de requêtes pour ces pages
Le clustering est utilisé pour faciliter et améliorer la deuxième étape de la liste ci-dessus. À la base, le clustering est méthode logicielle, qui sert à simplifier cette étape lorsque l'on travaille avec une grande sémantique, mais tout n'est pas aussi simple qu'il y paraît à première vue.
Pour mieux comprendre la théorie du clustering, vous devriez faire une petite excursion dans l’histoire du référencement :
Il y a quelques années à peine, alors que le terme clustering n'était pas omniprésent, les spécialistes du référencement regroupaient, dans la grande majorité des cas, la sémantique à la main. Mais lors du regroupement d'énormes sémantiques en 1 000, 10 000 et même 100 000 requêtes, cette procédure s'est transformée en un véritable travail acharné pour personne ordinaire. Et puis la méthode de regroupement par sémantique a commencé à être utilisée partout (et aujourd'hui, de nombreuses personnes utilisent cette approche). La méthode de regroupement par sémantique consiste à combiner des requêtes ayant une relation sémantique en un seul groupe. À titre d'exemple, les demandes « acheter une machine à laver » et « acheter une machine à laver jusqu'à 10 000 » ont été regroupées en un seul groupe. Et tout irait bien, mais cette méthode contient un certain nombre de problèmes critiques et pour les comprendre il faut introduire un nouveau terme dans notre récit, à savoir « intention de demande”.
La façon la plus simple de décrire ce terme est de décrire le besoin de l'utilisateur, son désir. L'intention n'est rien de plus que le désir de l'utilisateur qui saisit une requête de recherche.
La base de la sémantique de regroupement est de rassembler en un seul groupe les requêtes qui ont la même intention, ou les intentions les plus proches possibles, et ici deux caractéristiques intéressantes émergent à la fois, à savoir :
- La même intention peut avoir plusieurs requêtes qui n'ont aucune similarité sémantique, par exemple « entretien de la voiture » et « s'inscrire à l'entretien ».
- Les requêtes qui ont une similitude sémantique absolue peuvent contenir des intentions radicalement différentes, par exemple, la situation des manuels scolaires - « téléphone portable » et « téléphones mobiles ». Dans un cas, l’utilisateur souhaite acheter un téléphone et dans l’autre, regarder un film.
Ainsi, regrouper la sémantique par correspondance sémantique ne prend pas en compte l’intention des requêtes. Et les groupes ainsi constitués ne vous permettront pas d'écrire un texte qui atteindra le TOP. Lors du regroupement manuel pour éliminer ce malentendu, des gars avec le métier « d'aide » Spécialiste du référencement» J'ai analysé le problème à la main.
L’essence du clustering est de comparer les résultats générés par les moteurs de recherche à la recherche de modèles. À partir de cette définition, vous devez immédiatement noter que le clustering lui-même n'est pas la vérité ultime, car la sortie générée peut ne pas révéler complètement l'intention (il se peut tout simplement qu'il n'y ait pas de site dans la base de données Yandex qui ait correctement combiné les requêtes en un groupe).
Les mécanismes de clustering sont simples et ressemblent à ceci :
- Le système saisit une par une toutes les requêtes qui lui sont soumises dans les résultats de recherche et mémorise les résultats du TOP
- Après avoir saisi les requêtes une par une et enregistré les résultats, le système recherche des intersections dans les résultats. Si le même site avec le même document (page du site) est dans le TOP pour plusieurs demandes à la fois, alors ces demandes peuvent théoriquement être regroupées en un seul groupe.
- Un paramètre tel que la force de regroupement devient pertinent, qui indique au système exactement combien d'intersections il doit y avoir pour que les demandes puissent être ajoutées à un groupe. Par exemple, une force de regroupement de 2 signifie que les résultats de 2 requêtes différentes doivent contenir au moins deux intersections. Pour faire encore plus simple, au moins deux pages de deux sites différents doivent être simultanément dans le TOP pour l'une et l'autre requête. Exemple ci-dessous.
- Lors du regroupement d'une grande sémantique, la logique des connexions entre les requêtes devient pertinente, sur la base de laquelle on distingue 3 types principaux de clustering : soft, middle et hard. Nous parlerons davantage des types de clustering dans les prochaines entrées de ce journal.
En plus du site, il est important de savoir l'utiliser correctement avec un maximum d'avantages pour les utilisateurs internes et optimisation externe site.
De nombreux articles ont déjà été écrits sur la façon de créer un noyau sémantique, c'est pourquoi, dans le cadre de cet article, je souhaite attirer votre attention sur certaines fonctionnalités et détails qui vous aideront à utiliser correctement le noyau sémantique, et aidant ainsi à promouvoir une boutique en ligne ou un site Web. Mais d’abord, je vais donner brièvement ma définition du noyau sémantique du site.
Quel est le noyau sémantique d’un site ?
Le noyau sémantique d'un site est une liste, un ensemble, un tableau ou un ensemble de mots-clés et d'expressions demandés par les utilisateurs (vos visiteurs potentiels) dans les navigateurs des moteurs de recherche pour trouver les informations qui les intéressent.
Pourquoi un webmaster doit-il créer un noyau sémantique ?
Sur la base de la définition du noyau sémantique, il existe de nombreuses réponses évidentes à cette question.
Il est important que les propriétaires de boutique en ligne sachent comment les acheteurs potentiels tentent de trouver le produit ou le service que le propriétaire de la boutique en ligne souhaite vendre ou fournir. La position de la boutique en ligne dans les résultats de recherche dépend directement de cette compréhension. Plus le contenu d’une boutique en ligne est cohérent avec les requêtes de recherche des consommateurs, plus la boutique en ligne se rapproche du HAUT des résultats de recherche. Cela signifie que la conversion des visiteurs en acheteurs sera plus élevée et de meilleure qualité.
Pour les blogueurs qui participent activement à la monétisation de leurs blogs (gagner de l'argent), il est également important d'être dans le TOP des résultats de recherche sur des sujets pertinents au contenu du blog. Une augmentation du trafic de recherche apporte plus de profit sur les impressions et les clics de la publicité contextuelle sur le site, les impressions et les clics sur blocs d'annonces programmes d'affiliation et croissance des bénéfices pour d'autres types de revenus.
Plus le contenu d’un site est original et utile, plus il se rapproche du TOP. La vie existe principalement sur la première page des résultats des moteurs de recherche. Par conséquent, savoir créer un noyau sémantique est nécessaire pour le référencement de tout site Web ou boutique en ligne.
Parfois, les webmasters et les propriétaires de boutiques en ligne se demandent où trouver du contenu pertinent et de haute qualité ? La réponse vient de la question : vous devez créer du contenu conformément aux demandes des utilisateurs clés. Plus les moteurs de recherche considèrent que le contenu de votre site est pertinent par rapport aux mots-clés des utilisateurs, mieux c'est pour vous. À propos, c'est ici que se pose la réponse à la question : où trouver une variété de sujets de contenu ? C'est simple : en analysant les requêtes de recherche des utilisateurs, vous pouvez découvrir ce qui les intéresse et sous quelle forme. Ainsi, après avoir créé le noyau sémantique du site, vous pouvez rédiger une série d'articles et/ou de descriptions pour les produits de la boutique en ligne, en optimisant chaque page pour un mot-clé spécifique (requête de recherche).
Par exemple, j'ai décidé d'optimiser cet article pour la requête clé « comment créer un noyau sémantique », car la concurrence dans cette demande inférieur à celui de la requête « comment créer un noyau sémantique » ou « comment créer un noyau sémantique ». Ainsi, il m'est beaucoup plus facile d'accéder absolument au TOP des résultats des moteurs de recherche pour cette requête. méthodes gratuites promotion.
Comment créer un noyau sémantique, par où commencer ?
Il existe un certain nombre de services en ligne populaires permettant de constituer un noyau sémantique.
Le service le plus populaire, à mon avis, est les statistiques de mots clés Yandex - http://wordstat.yandex.ru/
Grâce à ce service, vous pouvez collecter la grande majorité des requêtes de recherche sous diverses formes et combinaisons de mots pour n'importe quel sujet. Par exemple, dans la colonne de gauche, nous voyons des statistiques sur le nombre de demandes non seulement pour la phrase clé « noyau sémantique », mais également des statistiques sur diverses combinaisons de cette phrase clé dans différentes conjugaisons et avec des mots dilués et supplémentaires. Dans la colonne de gauche, nous voyons des statistiques sur les expressions de recherche recherchées avec la phrase clé « noyau sémantique ». Ces informations peuvent être précieuses, au moins en tant que source de sujets pour créer du nouveau contenu pertinent pour votre site. Je tiens également à mentionner une caractéristique de ce service : vous pouvez spécifier la région. Grâce à cette option, vous pourrez connaître plus précisément le nombre et la nature des requêtes de recherche dont vous avez besoin pour la région souhaitée.

Un autre service pour compiler un noyau sémantique est les statistiques des requêtes de recherche Rambler - http://adstat.rambler.ru/

À mon avis subjectif, ce service peut être utilisé lorsqu'il y a une bataille pour attirer chaque utilisateur sur votre site. Ici, vous pouvez clarifier certaines requêtes à basse fréquence et à longue traîne ; les demandes des utilisateurs vont d'environ 1 à 5 à 10 par mois, c'est-à-dire très peu. Je ferai immédiatement une réserve qu'à l'avenir, nous examinerons le sujet de la classification des mots-clés et les caractéristiques de chaque groupe du point de vue de leur application. Par conséquent, personnellement, j'utilise rarement ces statistiques, généralement dans les cas où je travaille sur un site hautement spécialisé.
Pour constituer le noyau sémantique du site, vous pouvez également utiliser les astuces qui apparaissent lors de la saisie d’une requête de recherche dans le navigateur du moteur de recherche.


Et une autre option que les résidents d'Ukraine peuvent ajouter à la liste de mots-clés pour le noyau sémantique du site est de consulter les statistiques du site sur - http://top.bigmir.net/

En sélectionnant le sujet souhaité section, nous recherchons des statistiques ouvertes du site le plus visité et le plus pertinent

Comme vous pouvez le constater, les statistiques qui vous intéressent ne sont pas toujours ouvertes et, en règle générale, les webmasters les cachent. Cependant, il peut également fonctionner comme une source supplémentaire de mots-clés.
À propos, un merveilleux article de Globator (Mikhail Shakin) vous apprendra à organiser magnifiquement la liste complète des mots-clés sous forme de tableau dans Excel - http://shakin.ru/seo/keyword-suggestion.html Là, vous pouvez également découvrez comment créer un noyau sémantique pour les projets en anglais.
Que faire ensuite avec la liste de mots-clés ?
Tout d'abord, pour créer un noyau sémantique, je recommande de structurer la liste de mots-clés - en la divisant en groupes conditionnels : mots-clés haute fréquence (HF), moyenne fréquence (MF) et basse fréquence (LF). Il est important que ces groupes incluent des mots-clés très similaires en termes de morphologie et de sujet. Le moyen le plus pratique de procéder est de prendre la forme d’un tableau. Je fais quelque chose comme ça :

La rangée supérieure du tableau contient les requêtes de recherche à haute fréquence (HF) (écrites en rouge). Je les place en tête de colonnes thématiques, dans chaque cellule desquelles j'ai trié les requêtes de recherche moyenne fréquence (MF) et basse fréquence (LF) de la manière la plus homogène possible par thème. Ceux. J'ai lié les groupes de requêtes moyennes et basses fréquences les plus adaptés à chaque requête HF. Chaque cellule de requêtes à moyenne et basse fréquence est un futur article, que j'écris et optimise strictement pour l'ensemble de mots-clés de la cellule. Idéalement, un article devrait correspondre à un mot-clé (requête de recherche), mais c'est un travail très routinier et chronophage, car il peut y avoir des milliers de mots-clés de ce type ! Par conséquent, s'il y en a beaucoup, vous devez mettre en évidence les plus importants pour vous-même et éliminer le reste. En outre, vous pouvez optimiser votre futur article pour 2 à 4 mots-clés de fréquence moyenne et basse.
Pour les boutiques en ligne, les requêtes de recherche à moyenne et basse fréquence sont généralement des noms de produits. Il n’y a donc pas de difficultés particulières dans l’optimisation interne de chaque page d’une boutique en ligne, c’est juste un long processus. Plus ce délai est long, plus il y a de produits dans la boutique en ligne.
J'ai surligné en vert les cellules pour lesquelles j'ai déjà des articles prêts, c'est-à-dire Je ne me tromperai pas avec la liste des articles terminés à l'avenir.
Je vous expliquerai comment optimiser et rédiger des articles pour un site Web dans l'un des prochains articles.
Ainsi, après avoir réalisé un tel tableau, vous pouvez avoir une idée très claire de la manière dont vous pouvez créer le noyau sémantique d'un site.
À la suite de cet article, je tiens à dire que nous avons ici dans une certaine mesure abordé les détails de la question de la promotion d'une boutique en ligne. Après avoir lu certains de mes articles sur la promotion d'une boutique en ligne, vous avez sûrement eu l'idée que la compilation du noyau sémantique d'un site et l'optimisation interne sont des activités interdépendantes et interdépendantes. J'espère avoir pu argumenter sur l'importance et la priorité de la question - comment faire un noyau sémantique site.
Bonjour, chers lecteurs ! Souvent, lors de conversations personnelles avec des webmasters, je constate un manque de compréhension de l'importance des mots-clés pour la promotion des moteurs de recherche. Par conséquent, j'ai décidé d'écrire un article séparé sur ce sujet important. Ce qui s'est passé noyau sémantique du site, ses avantages et ses inconvénients, un exemple de noyau prêt à l'emploi, des conseils pour sa composition correcte - le sujet de cet article. Vous apprendrez pourquoi des mots-clés correctement sélectionnés sont si importants pour une ressource Web en termes de promotion SEO. Vous ressentirez leur importance et leur exclusivité et constaterez la puissance de leur utilisation.
Pourquoi ai-je écrit ce message ? Tout d’abord, mon article est destiné aux webmasters débutants qui viennent tout juste de commencer à comprendre la promotion SEO. Et deuxièmement, dans le top 20 de Yandex, il n'y a pas un seul article qui révélerait en détail à l'utilisateur de recherche l'essence du noyau sémantique. Corrigeons ce bug. J'espère que le moteur de recherche russe en tiendra compte. 🙂
Le concept de noyau sémantique
Ce que c'est
Chacun de nous sait utiliser un annuaire téléphonique. Qu'il s'agisse d'une version alphabet de poche sous forme de carnet ou d'un grand Talmud imprimé de tous les téléphones de la ville, le principe de son utilisation est très simple. Nous recherchons un nom de famille précis pour toutes les coordonnées de la personne que nous recherchons. Pour ce faire, nous devons connaître le nom complet de la personne. Habituellement, connaissant déjà le nom de famille d’une personne, nous pouvons facilement consulter toutes les entrées du répertoire et sélectionner celle dont nous avons besoin. Autrement dit, connaissant un certain mot (nom de famille), nous pouvons obtenir toutes les données sur une personne enregistrées dans le livre.

La sémantique du site fonctionne sur ce principe - nous saisissons une requête de recherche dans le moteur de recherche (analogue au nom pour lequel nous recherchons des contacts dans l'annuaire) et recevons une liste des documents répondant le plus précisément à partir de diverses ressources Web. Ces documents sont des pages individuelles de sites Web ou de blogs dont le contenu est optimisé pour la requête de recherche que nous demandons, appelée mot-clé. Ainsi, le noyau sémantique habituel est un ensemble de requêtes de recherche (mots-clés) qui caractérisent avec précision le sujet d'une ressource Web et le type de son activité (généralement pour les sites commerciaux proposant des services ou des biens sur Internet).

Le noyau sémantique est donc très performant fonction importante— il permet à une ressource Web de recevoir sur ses pages les utilisateurs des moteurs de recherche, nécessaires à l'exécution de diverses tâches. Par exemple, pour un site commercial, ces tâches peuvent consister à vendre des biens ou des services, pour un portail d'informations - à faire de la publicité pour des sources tierces à l'aide de publicités contextuelles ou de bannières, pour un blog - à faire de la publicité. programmes d'affiliation etc. Autrement dit, le noyau est exactement la base nécessaire pour recevoir du trafic de recherche à l'aide de la promotion SEO. Sans un ensemble de mots-clés corrects et de haute qualité, il n'est pas possible d'obtenir un tel trafic.
Par conséquent, si nous voulons utiliser les ressources et les capacités des moteurs de recherche pour promouvoir notre ressource Web, celle-ci doit disposer d'un noyau sémantique compétent. Si nous ne voulons pas recevoir de trafic de recherche, si nous n'avons pas besoin d'un public cible issu de la recherche, alors la présence de sémantique pour notre site n'est pas justifiée. Nous n'avons pas besoin de mots-clés.
Types de noyau sémantique
Dans la promotion sur les moteurs de recherche, il existe un noyau sémantique principal et un noyau secondaire. L'essentiel implique un ensemble de mots-clés principaux à l'aide desquels ce site réalise ses buts et objectifs. Par exemple, il peut s'agir des requêtes de recherche que les acheteurs potentiels de biens ou de services sur un site Web commercial suivent à la suite d'une recherche. Autrement dit, grâce aux demandes du noyau principal, le site ou le blog remplit son objectif. Ce sont les mots-clés qui mènent à la conversion utilisateur régulier de la recherche au client.
Un noyau sémantique secondaire permet à une ressource Web de résoudre des problèmes moins importants ou de recevoir du trafic supplémentaire pour attirer plus de clients potentiels. Dans ce cas, la gamme de mots-clés peut être non seulement le sujet principal du site, mais également des sujets connexes. Généralement utilisé dans un certain nombre de sites commerciaux qui souhaitent convertir les visiteurs avec des articles supplémentaires pour vendre des services ou des produits sur les pages de vente. Par exemple, c’est ce que font de nombreux sites proposant des services de référencement. Sur leurs ressources Web, en plus des principales pages de vente et explicatives, il existe un vaste ensemble de documents supplémentaires qui forment ensemble une option de blog.

Pour les blogueurs, le noyau principal est une liste de mots-clés qui leur apportent du trafic de recherche, car c'est la tâche principale lors de la monétisation d'un blog avec l'aide d'un public cible issu de la recherche. Et un blog n’a généralement pas de sémantique secondaire. Car quelle que soit la tâche du blog, tout le trafic sur toutes les pages promues dans les moteurs de recherche sert à résoudre sa tâche commerciale. Mais, généralement, les mots-clés sur le sujet principal donnent beaucoup plus de conversions commerciales que les mots-clés sur un sujet non essentiel.
Ce qu'il faut savoir lors de la création d'un noyau sémantique
Les mots-clés du noyau sémantique sont sélectionnés en fonction de divers paramètres (fréquence, compétitivité, etc.). J'ai écrit à ce sujet en détail dans. En fonction de ces paramètres, des noyaux sémantiques sont sélectionnés pour les sites commerciaux, les blogs, les portails d'actualités, etc. Le choix de certaines valeurs de ces caractéristiques dépend de trois composantes - de la stratégie de promotion, du montant du budget qui lui est alloué et du sujet du domaine d'activité du site promu.
La stratégie de promotion dicte le plan de sélection des mots-clés, en se concentrant sur la relation des pages promues avec le site et leur qualité. Premièrement, le schéma de liaison des pages est important ici - le nombre et l'importance des documents qui seront promus dans les moteurs de recherche dépendent de leur choix correct... Chaque ressource Web doit avoir son propre schéma, à l'aide duquel il y aura une meilleure répartition des poids parmi les documents promus. Deuxièmement, vous devez connaître le volume de contenu de la page promue (pour quels mots-clés sont sélectionnés) - en fonction du nombre de caractères, l'un ou l'autre nombre de mots-clés est utilisé pour cela.
La possibilité d'utiliser des requêtes compétitives dans le noyau sémantique dépend du montant du budget. Plus un webmaster peut allouer de ressources financières à son projet, meilleurs sont les mots qu'il peut inclure dans sa sémantique. Ce n’est un secret pour personne : les mots-clés promus de la plus haute qualité coûtent toujours cher. argent décent pour être entré dans le top 10 pour eux. Cela signifie que pour promouvoir des pages sur ces requêtes clés L'optimisation interne ne suffit pas - vous devez acheter des liens externes, vous avez besoin de ressources matérielles pour les acheter.
Tout d’abord, le seuil minimum de fréquence des mots clés pouvant être utilisé pour recevoir du trafic de recherche dépend du sujet. Plus le sujet est compétitif et plus il est restreint (en termes de popularité), plus le webmaster porte son regard vers les mots à basse et micro-fréquence (leur fréquence est inférieure à 50-100 selon le sujet). Par exemple, le sujet de mon blog (SEO et web analytique) est très restreint et plus grand nombre Je ne peux pas utiliser de mots-clés pour créer un noyau sémantique. Par conséquent, la plupart des mots-clés de mon blog sont des requêtes de recherche LF et MK avec une fréquence ne dépassant pas 100. Si l'on compare avec sujets populaires(par exemple, la cuisine - les requêtes basse fréquence atteignent 1 000 !), alors vous pouvez facilement comprendre qu'il est très difficile d'obtenir un trafic sérieux sur un petit sujet - vous devez avoir un grand nombre de mots clés basse fréquence (mais pas compétitif). Cela signifie que vous devez disposer d’un grand nombre de pages promues.

Plan de création d'un noyau sémantique
Pour créer un noyau sémantique, vous devez effectuer un certain nombre d'actions séquentielles :
- Sélectionnez les sujets du site Web pour lesquels des mots-clés seront sélectionnés. Ici, vous devez noter tous les domaines d'activité auxquels la ressource Web est dédiée. S'il s'agit d'une boutique en ligne, nous répertorions les principales catégories de produits (généralement, les mots-clés ne sont pas recherchés séparément pour les produits, à moins que le produit n'ait pas de modèle numéroté, mais seulement un modèle général). S'il s'agit d'un blog, tous les sous-thèmes du sujet général, ainsi que les titres individuels des articles importants. Si le site propose des services, alors les futurs mots-clés seront les noms de ces services, etc.
- Sur la base des sujets sélectionnés, créez une liste de masques - requêtes initiales qui seront utilisées pour analyser notre noyau sémantique. Vous pouvez en apprendre davantage sur le concept de liste à partir de. un autre article sur ce sujet, qui décrit.
- Découvrez la région dans laquelle votre site Web est promu. Selon l'emplacement de la ressource, certains mots-clés peuvent avoir différents degrés de concurrence. Plus la région est étroite et précise, plus son importance en termes de promotion est grande. Par exemple, de nombreux mots-clés ne sont pas aussi compétitifs en Russie qu’à Moscou.
- Analysez toutes sortes de requêtes de recherche des moteurs de recherche Yandex et Google (si nécessaire) à l'aide de diverses méthodes (manuelles, Programme clé Collectionneur, analyse de la concurrence, etc.). Options d'analyse décrites, pour lesquelles j'ai écrit en détail guides étape par étape, peut être trouvé via les liens dans le bloc d'articles supplémentaires après cet article.
- Les requêtes de recherche reçues doivent être analysées et celles de la plus haute qualité doivent être conservées. , qui vous permettra d'éliminer les mots factices, sera capable de séparer les mots compétitifs des mots non compétitifs et d'afficher les mots-clés les plus efficaces.
- Répartissez les mots-clés reçus parmi les documents de la ressource Web. Dernière étape de création d'un noyau sémantique, dans laquelle il faut sécuriser vos mots-clés pour chaque page promue, en fonction des conditions de promotion. Grâce à cette répartition, le webmaster peut voir immédiatement la requête principale et les requêtes complémentaires, mais aussi deviner la structure des futurs contenus. Ici, le noyau est divisé en primaire et secondaire (si nécessaire).
Une fois que le noyau sémantique complet du site a été créé, en termes de promotion, il est temps de se charger de l’optimisation interne des pages, puis de créer des liens efficaces.
Exemple de noyau sémantique prêt à l'emploi (table de mots-clés)
Afin que vous puissiez voir le résultat final, j'ai décidé de publier un morceau du noyau sémantique que j'ai commandé. Dans cette capture d'écran, vous verrez un tableau des mots-clés sélectionnés (l'image est cliquable) :

Comme vous pouvez le constater, tous les mots-clés sont répartis entre les articles (la distribution est effectuée par le client lui-même ou par moi moyennant des frais). Vous pouvez immédiatement voir quelles requêtes de recherche du tableau peuvent être utilisées comme requête principale et lesquelles sous la forme de mots-clés supplémentaires. Tout cela permet au client d'implémenter immédiatement et sans délai les mots-clés reçus dans les publications terminées ou de faire un plan approximatif pour les publications futures - tout est clairement et clairement visible.
Où commander un excellent noyau sémantique ?
Si vous souhaitez constituer un noyau sémantique à part entière pour un site Web commercial ou un projet d'information, je vous recommande de contacter.
Avantages et inconvénients du noyau sémantique
Comme dans toute entreprise, la création d’un noyau sémantique a ses côtés positifs et négatifs. Parlons d'abord des inconvénients :
- Pour obtenir un noyau sémantique de haute qualité pour un site Web, diverses options de coûts sont nécessaires. Si vous avez commandé votre liste de mots-clés auprès d'un spécialiste, ces coûts seront alors d'un montant décent. Plus vous commandez de mots, plus vous donnez de roubles. Si vous sélectionnez vous-même des mots-clés, vous pouvez passer beaucoup de temps à apprendre à sélectionner les requêtes les plus efficaces. Mais l'expérience acquise et la qualité des clés rendront les heures passées à collecter le noyau sous la forme d'une excellente conversion et d'un trafic de recherche ciblé.
- Pour sélectionner et analyser les meilleurs mots-clés parmi ceux déjà analysés, des connaissances sont nécessaires. Tous les webmasters n'aborderont pas cette question - après tout, en plus de la connaissance de l'optimisation, vous devez connaître les bases du travail dans Excel et être capable de compter (pour le formatage des données, tout d'abord). Mais, encore une fois, si tout cela se produit, la qualité de votre noyau sémantique sera plusieurs fois supérieure à celle d'un simple ensemble de clés analysées par Wordstat.
Comme vous pouvez le constater, les inconvénients sont peu nombreux, mais ils sont importants. Et si les ressources matérielles ne sont pas si importantes, alors étudier le matériel nécessaire demande du temps, ce qui est le plus apprécié. Après tout, il ne peut pas être retourné... Passons aux avantages :
- L’avantage le plus important est que vous disposez d’une base solide pour promouvoir votre ressource Web. Sans mots-clés, la visibilité d’un site Web ou d’un blog sera très faible, ce qui n’attirera pas beaucoup de trafic de recherche. Cela signifie que les tâches et objectifs assignés ne seront pas atteints. La simple rédaction d’un contenu de haute qualité ne suffit pas pour attirer les utilisateurs des moteurs de recherche. Les moteurs de recherche ont également besoin de la présence de mots-clés dans l’article (dans le texte) et sur la page (dans ses métadonnées). La création d'un noyau sémantique est donc la première étape, sans laquelle la promotion sur les moteurs de recherche est tout simplement irréaliste !
- Grâce à un bon noyau sémantique (bien entendu, en tenant compte de son optimisation interne compétente), les pages promues d'une ressource Web recevront non seulement exactement les utilisateurs cibles de la recherche, mais permettront également au site d'avoir d'excellents facteurs comportementaux. Lors de l'utilisation de mauvais mots clés (ou de leur absence), le taux de rebond augmente sensiblement et le nombre de conversions ciblées diminue.
- Disposant d'un noyau sémantique tout fait, tout webmaster aura une idée de l'avenir de sa ressource web en termes de création de contenu. En regardant les mots-clés, il verra les futurs sujets de ses articles sur le site. Autrement dit, il peut planifier ses activités beaucoup plus efficacement - confier une tâche au rédacteur à l'avance, mieux se préparer aux sauts saisonniers ou proposer la prochaine série de publications.
- En règle générale, un grand nombre d'articles sont créés (localisés) sur un blog. Par conséquent, vous devez rechercher de nombreux mots-clés pour eux. Mais vous ne devriez pas prendre les premiers que vous rencontrez - recherchez les meilleures options, évaluez-les, analysez les paramètres de vos requêtes de recherche. Vous passerez peut-être plus de temps, mais vous obtiendrez des clés de haute qualité qui attireront meilleur trafic qu'une collection des premières requêtes de recherche vues. Fixez-vous pour objectif de rechercher des mots-clés pour un article chaque jour. Après avoir rempli votre main, vous les collecterez beaucoup plus rapidement pour votre noyau, gérant ainsi 3 à 5 messages à la fois.
- Pas besoin d'en lire beaucoup Matériel de référencement, ne vous précipitez pas vers de nouvelles optimisations super-duper et ne cherchez pas le moyen idéal pour créer une sémantique pour votre blog - cela n'existe pas ! Prenez celui que vous comprenez. Et utilisez-le pour sélectionner des mots-clés. Mais ne faites confiance qu’aux documents vérifiés sur SY.
- Cela arrive souvent lorsque nous avons du mal à trouver un sujet pour notre futur article. Surtout du point de vue de la promotion sur les moteurs de recherche, lorsque la priorité est d'obtenir un trafic de recherche maximum. Un noyau sémantique prêt à l'emploi aide à se débarrasser une fois pour toutes de ce problème - sous vos yeux, à tout moment (!), vous pourrez observer les sujets prêts à l'emploi des articles suivants. Et pas seulement : vous pouvez ainsi estimer une future série de publications, qui pourront ensuite devenir votre propre produit d'information. 🙂

Et enfin, le conseil le plus important. Ne recherchez pas de mots-clés volumineux et épais. Cela n’apportera aucun avantage, vous ne ferez que vous créer des problèmes en perdant beaucoup de temps. Tenez compte de mon prochain principe en trois phases de sélection de mots-clés, que j'utilise avec succès sur mon blog (plus de 80 % des mots-clés sont dans le top 30, environ 49 % dans le top 10 dans Yandex et plus de 20 % dans Google - et c'est dans mon sujet de compétition complexe !) :
- Vérifiez les mots analysés résultants que vous avez collectés à votre manière (par exemple, en utilisant Wordstat, le programme Slovoeb, l'analyse des concurrents, etc.) pour la compétitivité - estimez leur coût de promotion (vous pouvez découvrir comment procéder dans mon livre gratuit ou vous pouvez lire dans un article supplémentaire séparé - lien après cet article). Supprimez toutes les requêtes concurrentes, ne laissez que celles ayant le coût minimum (par exemple, dans SeoPult, ce sont des mots-clés d'une valeur de 100 roubles, dans SeoPult Pro - 25).
- Pour les requêtes de recherche restantes, évaluez leur qualité. Pour ce faire, vous devez calculer le rapport entre les fréquences exactes et de base (disponibles à la fois dans le livre et dans l'article sur l'analyse des requêtes de recherche). Selon le sujet, excluez les mots de mauvaise qualité et les mots factices.
- Maintenant, parmi les mots de qualité reçus, répartissez-les entre les articles. Si une publication contient plusieurs mots-clés, choisissez le plus audacieux (mais ce mot-clé doit avoir un volume exact plus élevé que les autres). Ce sera la requête principale qui générera l’essentiel du trafic de recherche pour l’article promu. Si deux des mots-clés proposés pour l'article conviennent à la domination (plus de deux sont rares), prenez les deux. Écrivez-en un dans le titre, l'autre en h1. plate-forme multifonctionnelle unique Key Kollector ;
- Pour le blogueur meilleur assistant pour créer votre propre noyau sémantique, il y en aura bien sûr . Cela fonctionne rapidement et est absolument gratuit ! Je recommande!