Chaque développeur Web doit connaître SQL pour écrire des requêtes de base de données. Et, bien que phpMyAdmin n'ait pas été annulé, il est souvent nécessaire de mettre la main à la pâte pour écrire du SQL de bas niveau.
C'est pourquoi nous avons préparé un petit tour d'horizon des bases de SQL. Commençons!
1. Créez un tableau
L'instruction CREATE TABLE est utilisée pour créer des tables. Les arguments doivent être les noms des colonnes, ainsi que leurs types de données.
Créons une table simple nommée mois. Il se compose de 3 colonnes :
- identifiant– Numéro du mois dans l'année civile (entier).
- nom– Nom du mois (chaîne, 10 caractères maximum).
- jours– Nombre de jours dans ce mois (entier).
Voici à quoi ressemblerait la requête SQL correspondante :
CREATE TABLE mois (id int, nom varchar(10), jours int) ;
Aussi, lors de la création de tables, il est conseillé d'ajouter une clé primaire pour l'une des colonnes. Cela permettra de conserver les enregistrements uniques et d'accélérer les demandes de récupération. Dans notre cas, que le nom du mois soit unique (colonne nom)
CREATE TABLE mois (id int, nom varchar(10), jours int, PRIMARY KEY (nom)) ;
| Type de données | Description |
|---|---|
| DATE | Valeurs de dates |
| DATEHEURE | Valeurs de date et d'heure précises à la minute près |
| TEMPS | Valeurs temporelles |
2. Insertion de lignes
Maintenant, remplissons notre tableau mois informations utiles. L'ajout d'enregistrements à une table se fait à l'aide de l'instruction INSERT. Il existe deux manières d'écrire cette instruction.
La première méthode ne consiste pas à spécifier les noms des colonnes dans lesquelles les données seront insérées, mais à spécifier uniquement les valeurs.
Cette méthode d'enregistrement est simple, mais dangereuse, car il n'y a aucune garantie qu'à mesure que le projet se développe et que le tableau est modifié, les colonnes seront dans le même ordre qu'auparavant. Une manière sûre (et en même temps plus lourde) d'écrire une instruction INSERT nécessite de spécifier à la fois les valeurs et l'ordre des colonnes :
Voici la première valeur de la liste VALEURS correspond au premier nom de colonne spécifié, etc.
3. Extraire des données des tableaux
L'instruction SELECT est notre meilleure amie lorsque nous souhaitons récupérer des données d'une base de données. Il est utilisé très souvent, alors portez une attention particulière à cette section.
L'utilisation la plus simple de l'instruction SELECT est une requête qui renvoie toutes les colonnes et lignes d'une table (par exemple, les tables par nom personnages):
SELECT * FROM "caractères"
Le symbole astérisque (*) signifie que nous voulons obtenir les données de toutes les colonnes. Étant donné que les bases de données SQL sont généralement constituées de plusieurs tables, il est nécessaire de spécifier le mot-clé FROM, suivi du nom de la table, séparé par un espace.
Parfois, nous ne souhaitons pas obtenir les données de toutes les colonnes d'un tableau. Pour ce faire, au lieu d'un astérisque (*), il faut noter les noms des colonnes souhaitées, séparés par des virgules.
SELECT id, nom FROM mois
De plus, dans de nombreux cas, nous souhaitons que les résultats obtenus soient triés dans un ordre spécifique. En SQL, nous faisons cela en utilisant ORDER BY. Il peut accepter un modificateur facultatif - ASC (par défaut) tri par ordre croissant ou DESC, tri par ordre décroissant :
SELECT id, nom FROM mois ORDER BY nom DESC
Lorsque vous utilisez ORDER BY, assurez-vous qu'il apparaît en dernier dans l'instruction SELECT. Sinon, un message d'erreur s'affichera.
4. Filtrage des données
Vous avez appris à sélectionner des colonnes spécifiques dans une base de données à l'aide d'une requête SQL, mais que se passe-t-il si nous devons également récupérer des lignes spécifiques ? La clause WHERE vient ici à la rescousse, nous permettant de filtrer les données en fonction de la condition.
Dans cette requête, nous sélectionnons uniquement ces mois dans le tableau mois, dans lequel il y a plus de 30 jours d'utilisation de l'opérateur supérieur à (>).
SELECT id, nom FROM mois WHERE jours > 30
5. Filtrage avancé des données. Opérateurs AND et OR
Auparavant, nous utilisions le filtrage des données selon un seul critère. Pour un filtrage de données plus complexe, vous pouvez utiliser les opérateurs AND et OR ainsi que les opérateurs de comparaison (=,<,>,<=,>=,<>).
Nous avons ici un tableau contenant les quatre albums les plus vendus de tous les temps. Choisissons ceux qui sont classés comme rock et qui se sont vendus à moins de 50 millions d'exemplaires. Cela peut être facilement réalisé en plaçant un opérateur ET entre ces deux conditions.
 SELECT * FROM albums WHERE genre = "rock" AND sales_in_millions<= 50
ORDER BY released
SELECT * FROM albums WHERE genre = "rock" AND sales_in_millions<= 50
ORDER BY released
6. Dans/Entre/J’aime
WHERE prend également en charge plusieurs commandes spéciales, vous permettant de vérifier rapidement les requêtes les plus fréquemment utilisées. Les voici:
- IN – sert à indiquer une série de conditions, dont chacune peut être remplie
- ENTRE – vérifie si une valeur se situe dans la plage spécifiée
- LIKE – recherche des modèles spécifiques
Par exemple, si nous voulons sélectionner des albums avec populaire Et âme musique, nous pouvons utiliser IN("value1","value2") .
SELECT * FROM albums WHERE genre IN ("pop","soul");
Si l’on veut récupérer tous les albums sortis entre 1975 et 1985, il faut écrire :
SÉLECTIONNER * DES albums OÙ sortis ENTRE 1975 ET 1985 ;
7. Fonctions
SQL regorge de fonctions qui font toutes sortes de choses utiles. Voici quelques-uns des plus couramment utilisés :
- COUNT() – renvoie le nombre de lignes
- SUM() - renvoie la somme totale d'une colonne numérique
- AVG() - renvoie la moyenne d'un ensemble de valeurs
- MIN() / MAX() – Obtient la valeur minimale/maximale d'une colonne
Pour obtenir l'année la plus récente dans notre table, nous devons écrire la requête SQL suivante :
SELECT MAX (sorti) FROM albums ;
8. Sous-requêtes
Dans le paragraphe précédent, nous avons appris à effectuer des calculs simples avec des données. Si l’on souhaite exploiter le résultat de ces calculs, on ne peut pas se passer de requêtes imbriquées. Disons que nous voulons sortir artiste, album Et année de sortie pour l'album le plus ancien du tableau.
Nous savons comment obtenir ces colonnes spécifiques :
SELECT artiste, album, sorti DES albums ;
Nous savons également comment obtenir l'année la plus ancienne :
SELECT MIN (sorti) DE l'album ;
Il ne reste plus qu'à combiner les deux requêtes en utilisant WHERE :
SELECT artiste, album, sorti FROM albums WHERE release = (SELECT MIN (sorti) FROM albums );
9. Joindre des tables
Dans les bases de données plus complexes, il existe plusieurs tables liées les unes aux autres. Par exemple, vous trouverez ci-dessous deux tableaux sur les jeux vidéo ( jeux vidéo) et les développeurs de jeux vidéo ( développeurs_dejeu).


Dans la table jeux vidéo il y a une colonne développeur ( ID_développeur), mais il contient un entier et non le nom du développeur. Ce numéro représente l'identifiant ( identifiant) du développeur correspondant dans le tableau des développeurs de jeux ( développeurs_dejeu), reliant logiquement deux listes, nous permettant d'utiliser les informations stockées dans les deux en même temps.
Si nous voulons créer une requête qui renvoie tout ce que nous devons savoir sur les jeux, nous pouvons utiliser un INNER JOIN pour lier les colonnes des deux tables.
SELECT video_games.name, video_games.genre, game_developers.name, game_developers.country FROM video_games INNER JOIN game_developers ON video_games.developer_id = game_developers.id;
Il s’agit du type JOIN le plus simple et le plus courant. Il existe plusieurs autres options, mais celles-ci s'appliquent à des cas moins courants.
10. Alias
Si vous regardez l'exemple précédent, vous remarquerez qu'il y a deux colonnes appelées nom. C'est déroutant, alors définissons un alias pour l'une des colonnes répétitives, comme ceci nom de la table développeurs_dejeu sera appelé développeur.
Nous pouvons également raccourcir la requête en créant un alias pour les noms de tables : jeux vidéo appelons Jeux, développeurs_dejeu - les développeurs:
SELECT games.name, games.genre, devs.name AS développeur, devs.country FROM video_games AS games INNER JOIN game_developers AS devs ON games.developer_id = devs.id;
11. Mise à jour des données
Nous devons souvent modifier les données de certaines lignes. En SQL, cela se fait à l'aide de l'instruction UPDATE. L'instruction UPDATE comprend :
- Le tableau dans lequel se situe la valeur de remplacement ;
- Noms de colonnes et leurs nouvelles valeurs ;
- Les lignes sélectionnées en utilisant WHERE que nous souhaitons mettre à jour. Si cela n'est pas fait, toutes les lignes du tableau changeront.
Ci-dessous le tableau Séries TV avec les séries télévisées et leurs audiences. Cependant, une petite erreur s'est glissée dans le tableau : bien que la série Game of Thrones et est décrit comme une comédie, ce n'est vraiment pas le cas. Réparons ça !
 Données de la table tv_series UPDATE tv_series SET genre = "drame" WHERE id = 2;
Données de la table tv_series UPDATE tv_series SET genre = "drame" WHERE id = 2; 12. Suppression de données
La suppression d'une ligne de tableau à l'aide de SQL est un processus très simple. Tout ce que vous avez à faire est de sélectionner le tableau et la ligne que vous souhaitez supprimer. Supprimons la dernière ligne du tableau de l'exemple précédent Séries TV. Cela se fait à l'aide de l'instruction >DELETE.
SUPPRIMER DE tv_series OÙ id = 4
Soyez prudent lorsque vous écrivez l'instruction DELETE et assurez-vous que la clause WHERE est présente, sinon toutes les lignes du tableau seront supprimées !
13. Supprimer un tableau
Si nous voulons supprimer toutes les lignes mais quitter la table elle-même, utilisez la commande TRUNCATE :
TRUNCATE TABLE nom_table ;
Dans le cas où nous souhaitons effectivement supprimer à la fois les données et la table elle-même, alors la commande DROP nous sera utile :
DROP TABLE nom_table ;
Soyez très prudent avec ces commandes. Ils ne peuvent pas être annulés !/p>
Ceci conclut notre tutoriel SQL ! Il y a beaucoup de choses que nous n'avons pas abordées, mais ce que vous savez déjà devrait suffire à vous donner des compétences pratiques pour votre carrière sur le Web.
Bienvenue sur mon blog. Aujourd'hui, nous allons parler des requêtes SQL pour les débutants. Certains webmasters peuvent avoir une question. Pourquoi apprendre SQL ? N'est-il pas possible de s'en sortir ?
Il s'avère que cela ne suffira pas à créer un projet Internet professionnel. SQL est utilisé pour travailler avec des bases de données et créer des applications pour WordPress. Voyons plus en détail comment utiliser les requêtes.
Ce que c'est
SQL est un langage de requête structuré. Conçu pour déterminer le type de données, y donner accès et traiter les informations dans de courts délais. Il décrit les composants ou certains résultats que vous souhaitez voir sur le projet Internet.
Pour faire simple, ce langage de programmation permet d'ajouter, de modifier, de rechercher et d'afficher des informations dans la base de données. La popularité de MySQL est due au fait qu'il est utilisé pour créer des projets Internet dynamiques basés sur une base de données. Par conséquent, pour développer un blog fonctionnel, vous devez apprendre ce langage.
Qu'est-ce que ça peut faire
Le langage SQL permet de :
- créer des tableaux ;
- changer pour recevoir et stocker diverses données ;
- combiner les informations en blocs ;
- protéger les données ;
- créer des requêtes en accès.
Important! Une fois que vous comprenez SQL, vous pouvez écrire des applications pour WordPress de toute complexité.
Quelle structure
La base de données est constituée de tableaux pouvant être présentés sous forme de fichier Excel.
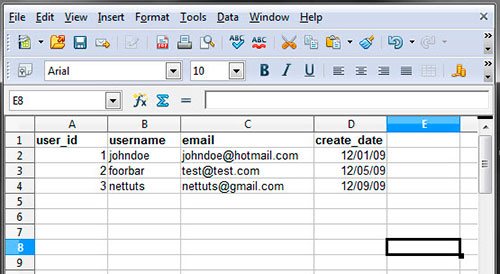
Il a un nom, des colonnes et une ligne avec quelques informations. Vous pouvez créer de telles tables à l'aide de requêtes SQL.
Que souhaitez-vous savoir

Points clés pour apprendre SQL
Comme indiqué ci-dessus, les requêtes sont utilisées pour traiter et saisir de nouvelles informations dans une base de données composée de tables. Chaque ligne est une entrée distincte. Alors, créons une base de données. Pour ce faire, écrivez la commande :
Créer une base de données 'bazaname'
Nous écrivons le nom de la base de données en latin entre guillemets. Essayez de lui trouver un nom clair. Ne créez pas de base de données comme « 111 », « www » et autres.
Après avoir créé la base de données, installez :
FIXER LES NOMS 'utf-8'
Ceci est nécessaire pour que le contenu du site s'affiche correctement.
Créons maintenant un tableau :
CRÉER UNE TABLE 'bazaname' . 'tableau' (
id INT(8) NON NULL CLÉ PRIMAIRE AUTO_INCREMENT,
journal VARCHAR(10),
passer VARCHAR(10),
dateDATE

Dans la deuxième ligne, nous avons écrit trois attributs. Voyons ce qu'ils signifient :
- L'attribut NOT NULL signifie que la cellule ne sera pas vide (le champ est obligatoire) ;
- La valeur AUTO_INCREMENT est une saisie semi-automatique ;
- CLÉ PRIMAIRE - clé primaire.
Comment ajouter des informations
Pour remplir les champs de la table créée avec des valeurs, l'instruction INSERT est utilisée. Nous écrivons les lignes de code suivantes :
INSÉRER DANS 'tableau'
(login, pass, date) VALEURS
(« Vasa », « 87654321 », « 21/06/2017 18:38:44 ») ;
Entre parenthèses, nous indiquons les noms des colonnes et, entre parenthèses, les valeurs.
Important! Maintenez la cohérence des noms et des valeurs des colonnes.
Comment mettre à jour les informations
Pour ce faire, utilisez la commande UPDATE. Voyons comment changer le mot de passe d'un utilisateur spécifique. Nous écrivons les lignes de code suivantes :
UPDATE 'table' SET pass = '12345678' WHERE id = '1'
Changez maintenant le mot de passe « 12345678 ». Les changements se produisent dans la ligne avec « id »=1. Si vous n'écrivez pas la commande WHERE, toutes les lignes changeront, pas une en particulier.
Je vous recommande d'acheter le livre " SQL pour les nuls " Avec son aide, vous pouvez travailler professionnellement avec la base de données étape par étape. Toutes les informations sont structurées selon le principe du simple au complexe et seront bien perçues.

Comment supprimer une entrée
Si vous avez écrit quelque chose de mal, corrigez-le à l'aide de la commande DELETE. Fonctionne de la même manière que UPDATE. Nous écrivons le code suivant :
SUPPRIMER DE 'table' OÙ id = '1'
Informations sur l'échantillonnage
Pour récupérer les valeurs de la base de données, utilisez la commande SELECT. Nous écrivons le code suivant :
SELECT * FROM 'table' WHERE id = '1'
Dans cet exemple, nous sélectionnons tous les champs disponibles dans le tableau. Cela se produit si vous entrez un astérisque « * » dans la commande. Si vous devez sélectionner un exemple de valeur, écrivez ceci :
SELECT log, passez FROM table WHERE id = '1'
Il convient de noter que la capacité de travailler avec des bases de données ne suffira pas. Pour créer un projet Internet professionnel, vous devrez apprendre à ajouter des données d'une base de données aux pages. Pour cela, familiarisez-vous avec le langage de programmation web PHP. Cela vous aidera avec ça cours sympa de Mikhail Rusakov .

Supprimer un tableau
Se produit à l’aide d’une requête DROP. Pour ce faire, nous écrirons les lignes suivantes :
table DÉPOSER LA TABLE ;
Afficher un enregistrement d'une table en fonction d'une condition spécifique
Considérez ce code :
SELECT id, country, city FROM table WHERE people>150000000
Il affichera les enregistrements des pays comptant plus de cent cinquante millions d'habitants.
Une association
Il est possible de lier plusieurs tables entre elles grâce à Join. Découvrez comment cela fonctionne plus en détail dans cette vidéo :
PHP et MySQL
Je tiens encore une fois à souligner que les demandes lors de la création d'un projet Internet sont monnaie courante. Pour les utiliser dans des documents PHP, suivez l'algorithme suivant :
- Connectez-vous à la base de données à l'aide de la commande mysql_connect() ;
- En utilisant mysql_select_db() nous sélectionnons la base de données souhaitée ;
- Nous traitons la requête en utilisant mysql_fetch_array();
- Fermez la connexion avec la commande mysql_close().
Important! Travailler avec une base de données n'est pas difficile. L'essentiel est de rédiger correctement la demande.
Les webmasters débutants y réfléchiront. Que faut-il lire sur ce sujet ? Je voudrais recommander le livre de Martin Graber " SQL pour les simples mortels " Il est écrit de telle manière que les débutants comprendront tout. Utilisez-le comme ouvrage de référence.

Mais c'est une théorie. Comment cela fonctionne-t-il en pratique ? En réalité, un projet Internet doit non seulement être créé, mais également porté au TOP de Google et Yandex. Le cours vidéo vous y aidera " Création et promotion de site internet ».

Instruction vidéo
Vous avez encore des questions ? Regardez la vidéo en ligne pour plus de détails.
Conclusion
Ainsi, comprendre comment écrire des requêtes SQL n'est pas aussi difficile qu'il y paraît, mais tout webmaster doit le faire. Les cours vidéo décrits ci-dessus vous y aideront. S'abonner à mon groupe VKontakte être le premier informé lorsque de nouvelles informations intéressantes apparaissent.
La récupération des données d'une table en SQL se fait à l'aide de la construction suivante :
SÉLECTIONNER *|
[COMME ] DEPUIS [OÙ [ET ]]
[GROUPER PAR | [ AYANT ]]
[COMMANDÉ PAR [COLLATIONNER ]
]
Section SÉLECTIONNER
→ Définir une liste de colonnes de sortie
La liste des colonnes de sortie peut être spécifiée de plusieurs manières :
. Spécifiez le symbole * pour indiquer que toutes les colonnes de requête sont incluses dans les résultats de la requête dans un ordre naturel.
. Listez uniquement ceux dont vous avez besoin dans l’ordre souhaité.
Exemple : SELECT * FROM Client
→ Activer les colonnes calculées
Les colonnes de requête calculées peuvent être :
. Résultats d'expressions arithmétiques simples (+, -, /, *_ ou concaténation de chaînes (||).
. Résultats de la fonction d'agrégation COUNT(*)|(MOYENNE|SUM|MAX|MIN|COUNT) ()
Note: Dans SQL Server, vous pouvez en plus utiliser l'opérateur % - module (reste entier de division).
→ Activer les constantes
Les colonnes peuvent être des constantes de type numérique ou caractère.
Note: SELECT DISTINCT 'Pour ', SNum, Comm*100, '%', SName FROM SalesPeople
→ Renommer les colonnes de sortie
Les colonnes calculées, ainsi que toutes les autres colonnes, peuvent recevoir un nom unique si vous le souhaitez à l'aide du mot-clé AS : AS
Note: Dans SQL SERVER vous pouvez donner un nouveau nom à une colonne en utilisant l'opérateur d'affectation =
→ Préciser le principe de traitement des lignes en double
DISTINCT – interdit l’apparition de lignes en double dans l’ensemble de sortie. Il peut être spécifié une fois par instruction SELECT. En pratique, l'ensemble de sortie est initialement formé, ordonné, puis les valeurs en double en sont supprimées. Cela prend généralement beaucoup de temps et ne doit pas être abusé.
ALL (par défaut) – garantit que les valeurs en double sont également incluses dans les résultats de la requête
→ Activer les fonctions d'agrégation
Les fonctions d'agrégation (fonctions d'ensemble, statistiques ou de base) sont conçues pour calculer certaines valeurs pour un ensemble de lignes donné. Les fonctions d'agrégation suivantes sont utilisées :
. AVG|SUM(|) – calcule la moyenne | la somme des doublons ou éventuellement en excluant, en ignorant NULL.
. MIN|MAX() – trouve le maximum | valeur minimum.
. COUNT(*) – compte le nombre de lignes dans un ensemble, en tenant compte des valeurs NULL | valeurs dans la colonne, en ignorant les valeurs NULL, éventuellement sans doublons.
Notes d'utilisation:
. Les fonctions d'agrégation ne peuvent pas être imbriquées les unes dans les autres.
. En raison des valeurs NULL, l'expression SUM(F1)-SUN(F2)Sum(F1-F2)
. Les expressions AVG(Comm*100) sont autorisées dans les fonctions d'agrégation
. Si la requête ne renvoie aucune ligne ou si toutes les valeurs sont NULL, alors la fonction COUNT renvoie 0 et les autres renvoient NULL.
. Les fonctions AVG et SUM ne peuvent être utilisées que pour les types de données numériques dans Interval, tandis que le reste peut être utilisé pour n'importe quel type de données.
. La fonction COUNT renvoie un entier (de type Integer), et d'autres héritent des types de données des valeurs traitées, vous devez donc faire attention à l'exactitude du résultat de la fonction SUM (éventuellement débordement) et à l'échelle de la fonction AVG.
Exemples de fonctions d'agrégation :
SELECT COUNT(*) FROM Client
. SELECT COUNT(DISTINCT SNum) FROM Commandes
. SELECT MAX(Amt+Binc) FROM Orders //Si Binc est un champ numérique supplémentaire dans Orders
. SELECT AVG(Comm*100) FROM SalesPeople //Expression à l'intérieur de la fonction
→ Caractéristiques des serveurs industriels
Dans le SGBD Oracle, dans la section SELECT, vous pouvez spécifier des indices supplémentaires (27 éléments) qui influencent le choix du type d'optimiseur de requêtes et son fonctionnement.
SELECT /*+ ALL_ROWS */ FROM Commandes… //meilleures performances
Dans le SGBD SQL Server:
] – spécifie le nombre ou le pourcentage de lignes à lire. Si les dernières valeurs sont les mêmes, il est possible de lire toutes ces lignes et le nombre total peut être supérieur à celui spécifié.
DÉCLARER @p AS Int
SÉLECTIONNER @p=10
SELECT TOP (@p) AVEC LIENS * FROM Commandes
DE section
Cette rubrique est obligatoire et vous permet de :
→ Spécifier les noms des tables sources
La section FROM spécifie les noms des tables et/ou vues à partir desquelles les données seront récupérées. De plus, le même tableau peut être inclus plusieurs fois dans cette section.
Remarque : Dans le SGBD Oracle, vous pouvez également sélectionner des lignes à partir des instantanés.
→ Spécifier les alias de table
Un alias de table est un identifiant supplémentaire, généralement court, spécifié avec un espace après le nom de la table/vue.
Exemple : Client C
→ Spécifier une option de jointure de table externe
Si plusieurs tables sont spécifiées dans la clause FROM, elles sont toutes implicitement considérées comme des jointures externes. La norme fournit les principaux types de jointures de tables suivants :
1) Connexion croisée
CROSS JOIN - toutes les combinaisons possibles de paires de lignes sont déterminées, une pour chaque ligne de chacune des tables jointes. Équivalent à la conjonction cartésienne. Parfois appelé produit cartésien.
2) Connexion naturelle
JOIN - seules les lignes des tableaux A et B sont déterminées dans lesquelles les valeurs des colonnes sont les mêmes. Ils appellent cela une équiconnexion pas tout à fait complète. Il s'agit d'une jointure automatique sur plusieurs colonnes portant tous les mêmes noms (rejoindre).
3) Connexion par association
UNION JOIN - seules les lignes de chaque table sont déterminées pour lesquelles aucune correspondance n'a été établie. Les colonnes d'une autre table sont remplies de valeurs NULL. Notez que la jointure UNION et l'opérateur UNIUN ne sont pas la même chose. La connexion est à l’opposé d’une connexion INTÉRIEURE.
4) Union par prédicat
JOIN ON - filtre les lignes. Un prédicat peut contenir des sous-requêtes.
5) Rejoindre via les noms de colonnes
JOIN USING() – définit une connexion uniquement par les colonnes spécifiées, tandis que NATURAL – automatiquement par toutes les colonnes du même nom.
Types de connexion
représente l'un des arguments : INTÉRIEUR|{GAUCHE|DROITE|PLEIN)
. INTÉRIEUR– inclut des lignes contenant des colonnes avec des données correspondantes provenant des tables jointes. Utilisé par défaut.
. GAUCHE– inclut toutes les lignes du tableau A (tableau de gauche) et toutes les valeurs correspondantes du tableau B. Les colonnes des lignes non correspondantes sont remplies de valeurs NULL.
. DROITE– inclut toutes les lignes du tableau B (le tableau de droite) et toutes les valeurs correspondantes du tableau A. L’inverse est pour une jointure gauche.
. COMPLET– inclut toutes les lignes des deux tableaux. Les colonnes des lignes correspondantes sont remplies de valeurs réelles et les colonnes des lignes non correspondantes sont remplies de valeurs NULL.
. EXTÉRIEUR (externe)– un mot qualificatif signifiant que les lignes non correspondantes du tableau principal sont incluses avec les lignes correspondantes.
Exemples de jointure externe :
SELECT * FROM SalesPeople INNER JOIN Client ON SalesPeople.City=Customer.City
. SELECT * FROM Customer LEFT OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
. SELECT * FROM Customer FULL OUTER JOIN SalesPeople ON SalesPeople.City=Customer.City
Jointures cartésiennes et auto-unions
. Si, lors de l'inclusion de plusieurs tables, l'une ou l'autre option de jointure de tables n'est pas utilisée, alors ces jointures sont appelées cartésiennes. Ils sont utilisés pour récupérer des lignes de deux tables différentes. Ensuite, par exemple, lors de la jointure de deux tables contenant chacune 20 lignes, la table résultante contiendra 100 lignes - chacune des lignes d'une table avec chacune des lignes de l'autre table. SELECT * FROM Client, Commandes.
. Rejoindre des tables identiques est appelé une auto-jointure.
Clause OÙ
1. Créer des connexions internes
La connexion entre les tables est effectuée à l'aide d'opérateurs de comparaison et la liste des colonnes de sortie comprend les noms qualificatifs pour les colonnes du même nom des tables source.
Principaux types de connexions :
. Équiconnexions sont des jointures de table basées sur des égalités. La relation entre les tables par colonnes clés garantit l'intégrité référentielle. Si une jointure utilise une clé primaire et étrangère, il existe toujours une relation un-à-plusieurs (ancêtre/descendant).
. Connexions thêta est une jointure où l'opérateur de comparaison est l'inégalité (, >=, Notes SQL Server
Dans SQL Server, les jointures gauche, droite et complète peuvent être spécifiées dans la clause WHERE en utilisant [*]=[*]. En fait, une connexion externe est implémentée, qui dans d'autres SGBD est implémentée dans la section FROM.
Exemples de connexions internes
SELECT C.CName, S.SName, S.City FROM SalesPeople S, Customer C WHERE S.City=C.City
SELECT SName, CName FROM SalesPeople, Customer WHERE SName
2. Filtrage des lignes de l'ensemble de sortie
La clause WHERE vous permet également de définir, c'est-à-dire une condition logique qui peut être vraie ou fausse. De plus, l'une ou les deux valeurs comparées dans un prédicat peuvent être NULL, auquel cas le résultat de la comparaison peut être INCONNU. L'instruction SELECT récupère uniquement les lignes des tables pour lesquelles la valeur est TRUE, à l'exclusion des lignes pour lesquelles elle est FALSE ou UNKNOWN.
J'ai déjà écrit sur une variété de Requêtes SQL, mais il est temps de parler de choses plus complexes, par exemple, Requête SQL pour sélectionner des enregistrements dans plusieurs tables.
Lorsque vous et moi avons fait une sélection dans une table, tout était très simple :
SELECT noms_of_required_fields FROM nom_table OÙ condition_sélection
Tout est très simple et trivial, mais échantillonnage à partir de plusieurs tables à la fois Cela devient un peu plus compliqué. Une difficulté consiste à faire correspondre les noms de champs. Par exemple, chaque table possède un champ identifiant.
Regardons cette requête :
SELECT * FROM table_1, table_2 WHERE table_1.id > table_2.user_id
Beaucoup de ceux qui n'ont pas traité de telles requêtes penseront que tout est très simple, pensant que seuls les noms de tables ont été ajoutés avant les noms de champs. En fait, cela évite les conflits entre noms de champs identiques. Cependant, la difficulté ne réside pas là, mais dans algorithme pour une telle requête SQL.
L'algorithme de travail est le suivant : le premier enregistrement est extrait de Tableau 1. Prend identifiant cette entrée de Tableau 1. Ci-dessous le tableau complet Tableau 2. Et tous les enregistrements sont ajoutés là où la valeur du champ ID de l'utilisateur moins identifiant entrée sélectionnée dans Tableau 1. Ainsi, après la première itération, il peut apparaître de 0 à un nombre infini enregistrements résultants. À l'itération suivante, l'enregistrement de table suivant est pris Tableau 1. Le tableau entier est à nouveau numérisé Tableau 2, et la condition d'échantillonnage est à nouveau déclenchée table_1.id > table_2.user_id. Tous les enregistrements qui remplissent cette condition sont ajoutés au résultat. La sortie peut être un très grand nombre d’enregistrements, plusieurs fois plus grand que la taille totale des deux tables.
Si vous comprenez comment cela fonctionne dès la première fois, alors c'est génial, mais sinon, lisez jusqu'à ce que vous le compreniez parfaitement. Si vous comprenez cela, ce sera plus facile.
Précédent requête SQL, en tant que tel, est rarement utilisé. Il a juste été donné pour explications de l'algorithme de sélection parmi plusieurs tables. Maintenant, regardons le plus trapu requête SQL. Disons que nous avons deux tables : avec des marchandises (il y a un champ id_propriétaire responsable de identifiant Product Owner) et avec les utilisateurs (il existe un champ identifiant). Nous en voulons un requête SQL obtenez tous les enregistrements, et chacun contient des informations sur l'utilisateur et son produit. L'entrée suivante contenait des informations sur le même utilisateur et son prochain produit. Lorsque les produits de cet utilisateur sont épuisés, passez à l'utilisateur suivant. Il faut donc joindre deux tables et obtenir un résultat où chaque enregistrement contient des informations sur l'utilisateur et l'un de ses produits.
Une requête similaire remplacera 2 requêtes SQL: pour sélectionner séparément dans le tableau avec les produits et dans le tableau avec les utilisateurs. De plus, une telle demande mettra immédiatement en relation l’utilisateur et son produit.
La requête en elle-même est très simple (si vous avez compris la précédente) :
SELECT * FROM utilisateurs, produits WHERE users.id = products.owner_id
L'algorithme ici est déjà simple : le premier enregistrement de la table est pris utilisateurs. Ensuite, il est pris identifiant et tous les enregistrements de la table sont analysés des produits, en ajoutant au résultat ceux avec id_propriétaireéquivaut à identifiant de la table utilisateurs. Ainsi, lors de la première itération, toutes les marchandises du premier utilisateur sont collectées. A la deuxième itération, tous les produits du deuxième utilisateur sont collectés, et ainsi de suite.
Comme vous pouvez le voir, Requêtes SQL pour sélectionner parmi plusieurs tables ce n'est pas le plus simple, mais les avantages qui en découlent peuvent être énormes, il est donc très souhaitable de connaître et de pouvoir utiliser de telles requêtes.
Êtes-vous nouveau dans la programmation ou avez-vous simplement évité d'apprendre SQL dans le passé ? Alors vous êtes à la bonne adresse, puisque tout développeur est finalement confronté à la nécessité de connaître ce langage de requête. Vous n’êtes peut-être pas le principal concepteur de bases de données, mais il est presque impossible d’éviter de travailler avec elles. J'espère que ce bref aperçu de la syntaxe de base des requêtes SQL aidera le développeur intéressé et toute autre personne qui en a besoin.
Qu'est-ce qu'une base de données SQL ?
Structured Query Language est une norme de communication de base de données prise en charge par ANSI. La dernière version est SQL-99, bien qu'une nouvelle norme, SQL-200n, soit déjà en développement. La plupart des bases de données adhèrent fermement à la norme ANSI-92. Il y a eu de nombreuses discussions sur l'introduction de normes plus modernes, mais les fournisseurs de bases de données commerciales s'en éloignent en développant leurs propres nouveaux concepts de stockage des données stockées. Presque chaque base de données utilise un ensemble unique de syntaxe, bien que très similaire à la norme ANSI. Dans la plupart des cas, cette syntaxe est une extension de la norme de base, bien qu'il existe des cas où cette syntaxe produit des résultats différents pour différentes bases de données. C'est toujours une bonne idée de consulter la documentation de la base de données, surtout si vous obtenez des résultats inattendus.
Si vous débutez avec SQL, vous devez comprendre certains concepts de base.
En termes généraux, « base de données SQL » est le nom générique d'un système de gestion de base de données relationnelle (SGBDR). Pour certains systèmes, « base de données » fait également référence à un groupe de tables, de données ou d'informations de configuration qui constituent une partie intrinsèquement distincte d'autres constructions similaires. Dans ce cas, chaque installation de base de données SQL peut être constituée de plusieurs bases de données. Dans d'autres systèmes, ils sont appelés tableaux.
Une table est une structure de base de données composée de colonnes contenant des lignes de données. En règle générale, les tableaux sont créés pour contenir des informations associées. Plusieurs tables peuvent être créées dans la même base de données.
Chaque colonne représente un attribut ou un ensemble d'attributs d'objets, tels que les numéros d'identification des employés, la taille, la couleur de la voiture, etc. Souvent, le terme champ est utilisé pour désigner une colonne, suivi d'un nom, tel que « dans le champ Nom ». Un champ de ligne est l'élément minimum d'une table. Chaque colonne d'un tableau a un nom, un type de données et une taille spécifiques. Les noms de colonnes doivent être uniques dans la table.
Chaque ligne (ou enregistrement) représente un ensemble d'attributs d'un objet spécifique, par exemple, une ligne peut contenir le numéro d'identification de l'employé, son salaire, son année de naissance, etc. Les lignes du tableau n'ont pas de nom. Pour accéder à une ligne spécifique, l'utilisateur doit spécifier un attribut (ou un ensemble d'attributs) qui l'identifie de manière unique.
L'une des opérations les plus importantes effectuées lorsque l'on travaille avec des données consiste à récupérer les informations stockées dans la base de données. Pour ce faire, l'utilisateur doit exécuter une requête.
Examinons maintenant les principaux types de requêtes de base de données qui se concentrent sur la manipulation des données au sein de la base de données. Pour nos besoins, tous les exemples sont fournis en SQL standard pour s'adapter à n'importe quel environnement.
Types de requêtes de données
Il existe quatre principaux types de requêtes de données en SQL, qui relèvent de ce que l'on appelle le langage de manipulation de données (DML) :
SELECT – sélectionne les lignes des tableaux ;
INSÉRER – ajouter des lignes au tableau ;
MISE À JOUR – modifiez les lignes du tableau ;
DELETE – supprime des lignes du tableau ;
Chacune de ces requêtes possède différents opérateurs et fonctions utilisés pour effectuer certaines actions sur les données. La requête SELECT possède le plus grand nombre d'options. Il existe également des types de requêtes supplémentaires utilisés conjointement avec SELECT, tels que JOIN et UNION. Mais pour l’instant, nous nous concentrerons uniquement sur les requêtes de base.
Utiliser une requête SELECT pour sélectionner les données souhaitées
Pour récupérer les informations stockées dans la base de données, une requête SELECT est utilisée. L'effet de base de cette requête est limité à une seule table, bien qu'il existe des conceptions qui vous permettent de sélectionner simultanément plusieurs tables. Afin d'obtenir toutes les lignes de données pour des colonnes spécifiques, une requête comme celle-ci est utilisée :
SELECT colonne1, colonne2 FROM nom_table ;
Vous pouvez également obtenir toutes les colonnes d'une table en utilisant le caractère générique "*" :
SELECT * FROM nom_table ;
Cela peut être utile lorsque vous allez sélectionner des données avec une clause WHERE spécifique. La requête suivante renverra toutes les colonnes de toutes les lignes où « colonne1 » contient la valeur « 3 » :
SELECT * FROM nom_table WHERE colonne1=3;
En plus de « = » (égal), il existe les opérateurs conditionnels suivants :
Expressions conditionnelles:
= Égal
<>Inégal
> Plus
<
Меньше
>= Supérieur ou égal à
<=
Меньше или равно
De plus, vous pouvez utiliser les conditions BITWEEN et LIKE pour comparer avec la condition WHERE, ainsi qu'avec des combinaisons des opérateurs AND et OR.
SELECT * FROM nom_table OÙ ((Âge >= 18) ET (Nom ENTRE 'Ivanov' ET 'Sidorov')) OU Société COMME '%Motorola%';
Ce que signifie dans la traduction russe : sélectionnez toutes les colonnes de la table table_name, où la valeur de la colonne age est supérieure ou égale à 18, et la valeur de la colonne LastName est dans la plage alphabétique d'Ivanov à Sidorov inclus, ou la valeur de la colonne Entreprise est Motorola.
Utiliser une requête INSERT pour insérer de nouvelles données
Une requête INSERT est utilisée pour créer une nouvelle ligne de données. Pour mettre à jour des données existantes ou des champs de ligne vides, vous devez utiliser une requête UPDATE.
Exemple de syntaxe de requête INSERT :
INSERT INTO nom_table (colonne1, colonne2, colonne3) VALUES ('data1', 'data2', 'data3');
Si vous souhaitez insérer toutes les valeurs dans l'ordre dans lequel les colonnes du tableau apparaissent, vous pouvez omettre les noms de colonnes, bien que cela soit préférable pour des raisons de lisibilité. De plus, si vous répertoriez des colonnes, vous n'êtes pas obligé de les répertorier dans l'ordre dans lequel elles apparaissent dans la base de données, à condition que les valeurs que vous saisissez correspondent à cet ordre. Vous ne devez pas répertorier les colonnes qui ne contiennent pas d'informations.
Les informations déjà existantes dans la base de données sont modifiées de manière très similaire.
Requête UPDATE et condition WHERE
UPDATE est utilisé pour modifier les valeurs existantes ou libérer un champ dans une rangée, les nouvelles valeurs doivent donc correspondre au type de données existant et fournir des valeurs acceptables. Si vous ne souhaitez pas modifier les valeurs de toutes les lignes, vous devez utiliser la clause WHERE.
UPDATE nom_table SET colonne1 = 'data1', colonne2 = 'data2' WHERE colonne3 = 'data3';
Vous pouvez utiliser WHERE sur n'importe quelle colonne, y compris celle que vous souhaitez modifier. Ceci est utilisé lorsqu'il est nécessaire de remplacer une valeur spécifique par une autre.
UPDATE table_name SET FirstName = 'Vasily' WHERE FirstName = 'Vasily' AND LastName = 'Pupkin';
Sois prudent! La requête DELETE supprime des lignes entières
Une requête DELETE supprime complètement une ligne de la base de données. Si vous souhaitez supprimer un seul champ, vous devez alors utiliser une requête UPDATE et définir ce champ sur une valeur qui sera analogue à NULL dans votre programme. Attention à limiter votre requête DELETE à une clause WHERE, sinon vous risquez de perdre tout le contenu de la table.
DELETE FROM nom_table WHERE colonne1 = 'data1';
Une fois qu'une ligne a été supprimée de votre base de données, elle ne peut pas être restaurée, il est donc conseillé d'avoir une colonne nommée "IsActive", ou quelque chose comme ça, que vous pouvez changer en null, ce qui indiquera que la vue des données de cette ligne est verrouillée.
Vous connaissez désormais les bases des requêtes SQL
SQL est un langage de base de données et nous avons couvert les commandes les plus importantes et les plus basiques utilisées dans les requêtes de données. De nombreux concepts de base n'ont pas été abordés (SUM et COUNT, par exemple), mais les quelques commandes que nous avons réussi à lister ci-dessus devraient vous encourager à devenir actif et à approfondir le merveilleux langage de requête appelé SQL.